
Cơ sở dữ liệu vector là một cách tương tác tương đối mới với các biểu diễn dữ liệu trừu tượng, đến từ các mô hình học máy không rõ ràng như cấu trúc học sâu. Những biểu diễn này thường được gọi là các vector hoặc vector nhúng, và chúng là phiên bản nén của dữ liệu được sử dụng để huấn luyện các mô hình học máy để thực hiện các nhiệm vụ như phân tích cảm xúc, nhận dạng giọng nói và phát hiện đối tượng.
Các cơ sở dữ liệu mới này đã cho thấy hiệu suất xuất sắc trong nhiều ứng dụng, như tìm kiếm ngữ nghĩa và hệ thống đề xuất.
Qdrant là gì?
Qdrant là một cơ sở dữ liệu vector mã nguồn mở được thiết kế cho các ứng dụng trí tuệ nhân tạo thế hệ tiếp theo. Nó tích hợp với đám mây và cung cấp các API RESTful và gRPC để quản lý việc nhúng. Qdrant có các tính năng mạnh mẽ, hỗ trợ tìm kiếm hình ảnh, giọng nói và video, cũng như tích hợp với các engine trí tuệ nhân tạo.
Cơ sở dữ liệu vector là gì?
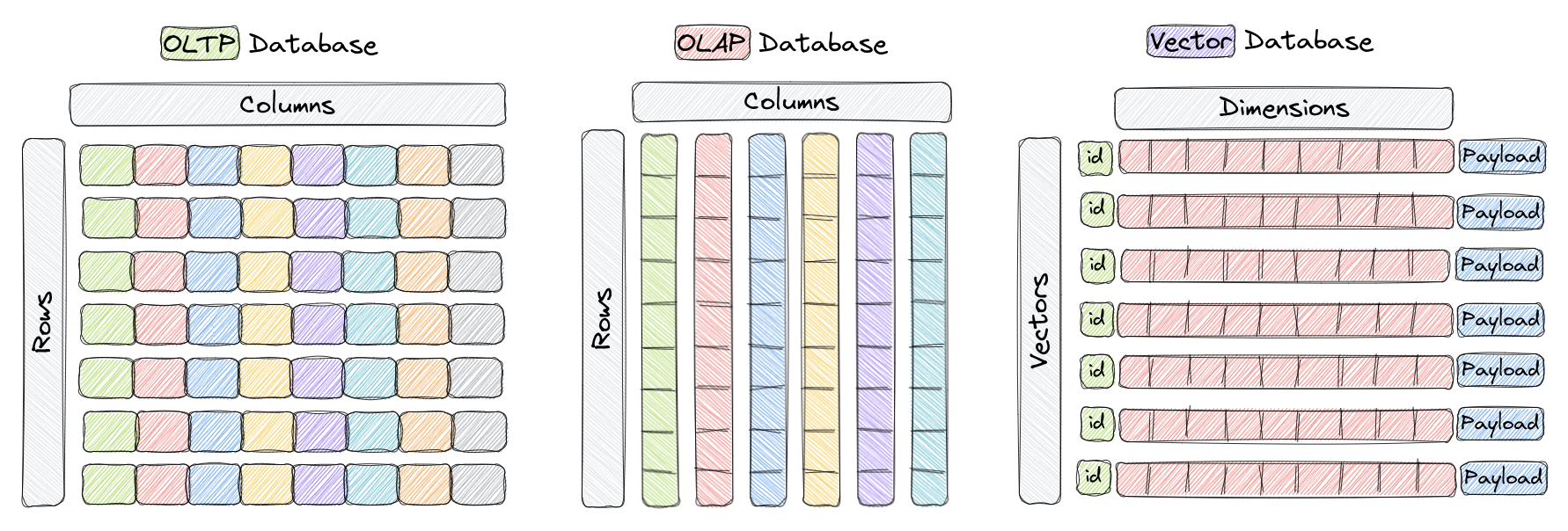
Cơ sở dữ liệu vector là loại cơ sở dữ liệu được thiết kế đặc biệt để lưu trữ và truy vấn hiệu quả các vector có số chiều cao. Trong cơ sở dữ liệu OLTP và OLAP truyền thống (như hình ảnh trên), dữ liệu được tổ chức thành hàng và cột (được gọi là bảng), và các truy vấn dựa trên các giá trị trong những cột này. Tuy nhiên, trong một số ứng dụng như nhận dạng hình ảnh, xử lý ngôn ngữ tự nhiên và hệ thống đề xuất, dữ liệu thường được biểu diễn dưới dạng các vector trong không gian có số chiều cao. Những vector này, cùng với một ID và tải trọng, đóng thành phần được lưu trữ trong cơ sở dữ liệu vector như Qdrant.
Trong ngữ cảnh này, một vector là biểu diễn toán học của một đối tượng hoặc điểm dữ liệu, trong đó mỗi phần tử của vector tương ứng với một đặc tính hoặc thuộc tính của đối tượng. Ví dụ, trong một hệ thống nhận dạng hình ảnh, một vector có thể biểu diễn một hình ảnh, với mỗi phần tử của vector đại diện cho giá trị pixel hoặc đặc trưng của pixel. Trong một hệ thống đề xuất âm nhạc, mỗi vector đại diện cho một bài hát, với mỗi phần tử của vector đại diện cho một đặc tính của bài hát, như nhịp, thể loại, lời bài hát, v.v.
Cơ sở dữ liệu vector được tối ưu hóa để lưu trữ và truy vấn hiệu quả các vector có số chiều cao, thường sử dụng cấu trúc dữ liệu và kỹ thuật lập chỉ mục chuyên biệt như Hierarchical Navigable Small World (HNSW) cho việc tìm kiếm gần nhất xấp xỉ và Product Quantization. Những cơ sở dữ liệu này có thể cho phép người dùng tìm thấy các vector gần nhất với một vector truy vấn cho trước theo một số lượng đo lường khoảng cách nhất định, cho phép tìm kiếm tương đồng và ngữ nghĩa nhanh chóng. Các đo lường khoảng cách thông thường bao gồm khoảng cách Euclid, tương đồng cosine và tích vô hướng, tất cả đều được hỗ trợ đầy đủ trong Qdrant.
Dưới đây là một phần giới thiệu ngắn gọn về ba thuật toán tương đồng vector này:
- Tương đồng Cosine - Tương đồng cosine là một đo lường độ tương tự giữa hai mục. Nó có thể được xem như một thước đo được sử dụng để đo khoảng cách giữa hai điểm; tuy nhiên, thay vì đo khoảng cách, nó đo lường độ tương tự giữa hai mục. Nó thường được sử dụng để so sánh sự tương tự giữa hai tài liệu hoặc câu trong văn bản. Phạm vi đầu ra của tương đồng cosine từ 0 đến 1, trong đó 0 chỉ ngữ nghĩa hoàn toàn không tương đồng và 1 chỉ ngữ nghĩa hoàn toàn tương đồng. Đó là một cách đơn giản và hiệu quả để so sánh hai mục!
- Tích Vô Hướng - Tương đồng tích vô hướng là một đo lường tương tự khác giữa hai mục, tương tự như tương đồng cosine. Trong xử lý số, nó thường được sử dụng trong học máy và khoa học dữ liệu. Tương đồng tích vô hướng tính bằng cách nhân các giá trị trong hai tập số và sau đó cộng các tích này lại. Tổng cao hơn chỉ ra sự tương tự cao hơn giữa hai tập số. Nó giống như một thước đo đo độ tương đồng giữa hai tập số.
- Khoảng Cách Euclid - Khoảng cách Euclid là cách đo khoảng cách giữa hai điểm trong không gian, tương tự như cách chúng ta đo khoảng cách giữa hai địa điểm trên bản đồ. Nó được tính bằng cách tìm căn bậc hai của tổng của bình phương của sự khác biệt giữa các tọa độ của hai điểm. Phương pháp đo khoảng cách này thường được sử dụng trong học máy để đánh giá độ tương đồng hoặc khác biệt của hai điểm dữ liệu, nói cách khác, để hiểu được hai điểm đó cách nhau bao xa.
Bây giờ khi chúng ta đã biết cơ sở dữ liệu vector là gì và cách chúng khác biệt về cấu trúc so với các cơ sở dữ liệu khác, hãy hiểu tại sao chúng quan trọng.
Tại sao chúng ta cần một cơ sở dữ liệu vector?
Cơ sở dữ liệu vector đóng vai trò quan trọng trong các ứng dụng đòi hỏi tìm kiếm sự tương đồng, như hệ thống gợi ý, tìm kiếm dựa trên nội dung hình ảnh và tìm kiếm cá nhân hóa. Bằng cách tận dụng các kỹ thuật lập chỉ mục và tìm kiếm hiệu quả, cơ sở dữ liệu vector có thể truy xuất dữ liệu không cấu trúc được biểu diễn dưới dạng vector một cách nhanh chóng và chính xác hơn, hiển thị kết quả phù hợp nhất với truy vấn của người dùng.
Ngoài ra, những lợi ích khác của việc sử dụng cơ sở dữ liệu vector bao gồm:
- Lưu trữ và lập chỉ mục dữ liệu có chiều cao một cách hiệu quả.
- Có khả năng xử lý tập dữ liệu quy mô lớn với hàng tỷ điểm dữ liệu.
- Hỗ trợ phân tích và truy vấn thời gian thực.
- Có khả năng xử lý vector có nguồn gốc từ các loại dữ liệu phức tạp như hình ảnh, video và văn bản tự nhiên.
- Cải thiện hiệu suất của ứng dụng học máy và trí tuệ nhân tạo đồng thời giảm thiểu độ trễ.
- Giảm thiểu thời gian và chi phí phát triển và triển khai so với việc xây dựng các giải pháp tùy chỉnh.
Vui lòng lưu ý rằng những lợi ích cụ thể khi sử dụng cơ sở dữ liệu vector có thể thay đổi tùy thuộc vào các trường hợp sử dụng của tổ chức và các chức năng cơ sở dữ liệu được chọn.
Bây giờ, hãy thực hiện một bản đánh giá tổng quan cao cấp về kiến trúc của Qdrant.
Tổng Quan Cao Cấp về Kiến Trúc của Qdrant
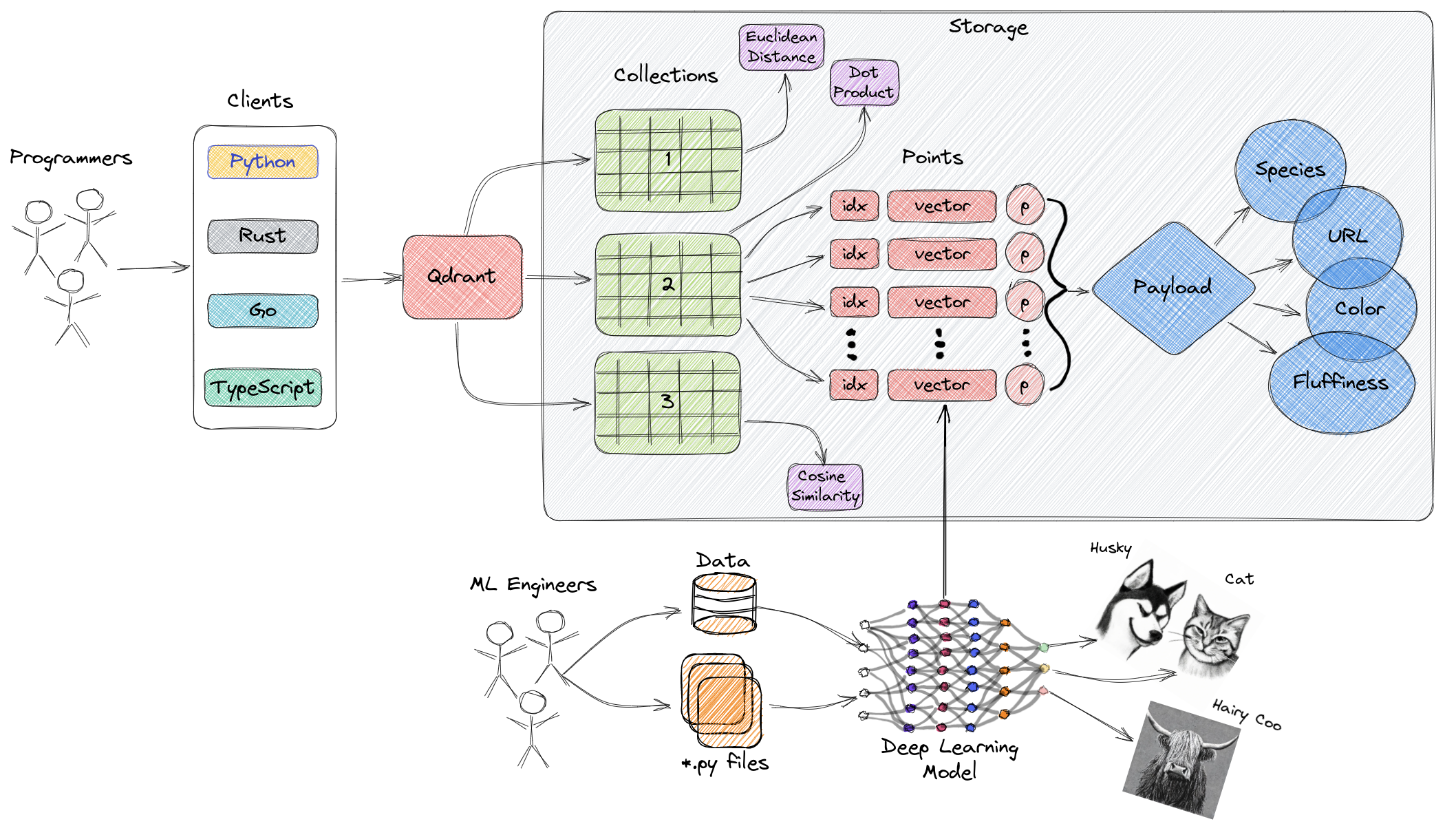
Sơ đồ trên cung cấp một bản đánh giá cao cấp về các thành phần chính của Qdrant. Dưới đây là các thuật ngữ quan trọng liên quan đến Qdrant:
- Bộ sưu tập: Bộ sưu tập là một nhóm các điểm có tên (vector với tải trọng - về cơ bản là dữ liệu vector). Nói một cách đơn giản, bộ sưu tập tương tự như các bảng trong MySQL, và các điểm tương tự như các hàng dữ liệu trong những bảng đó. Tìm kiếm có thể được thực hiện giữa các điểm này. Mỗi vector trong cùng một bộ sưu tập phải có cùng chiều và được so sánh bằng một thước đo duy nhất. Có thể sử dụng các vector có tên để có nhiều vector trong cùng một điểm, mỗi vector có chiều riêng và yêu cầu thước đo riêng.
- Thước đo: Một phép đo được sử dụng để đo lường sự tương đồng giữa các vector, mà phải được chọn khi tạo bộ sưu tập. Lựa chọn thước đo phụ thuộc vào phương pháp thu thập vector, đặc biệt là đối với các mạng nơ-ron được sử dụng để mã hóa các truy vấn mới (thước đo là thuật toán tương đồng mà chúng ta chọn).
- Điểm: Điểm là các thực thể cốt lõi mà Qdrant hoạt động, bao gồm vector, ID tùy chọn, và tải trọng (tương tự như các hàng dữ liệu trong bảng MySQL).
- ID: Bộ nhận dạng duy nhất của vector.
- Vector: Biểu diễn đa chiều của dữ liệu, chẳng hạn như hình ảnh, âm thanh, tài liệu, video, vv.
- Tải trọng: Một đối tượng JSON có thể được thêm vào vector như dữ liệu bổ sung (chủ yếu được sử dụng để lưu trữ các thuộc tính kinh doanh liên quan đến vector).
- Lưu trữ: Qdrant có thể sử dụng hai tùy chọn lưu trữ — lưu trữ trong bộ nhớ (tất cả các vector được lưu trữ trong bộ nhớ, cung cấp tốc độ cao nhất, vì truy cập đĩa chỉ được sử dụng cho tính chất bền vững) và lưu trữ Memmap (tạo một không gian địa chỉ ảo liên kết với các tệp trên đĩa).
- Khách hàng: Bạn có thể kết nối với Qdrant bằng cách sử dụng SDK ngôn ngữ lập trình hoặc tương tác trực tiếp với Qdrant bằng API REST của nó.