
ایک ویکٹر ڈیٹا بیس عموماً مبتدی مشین لرننگ ماڈلز جیسے گہرے لرننگ سڑکچرز سے نکلنے والے انتہاپس بنیادی ڈیٹا کی علمی تصویرات کے ساتھ تعامل کرنے کا نیا طریقہ ہے۔ یہ تصویرات عام طور پر ویکٹر یا ایمبیڈنگ ویکٹر کے طور پر ماننے جاتے ہیں، اور یہ ڈیٹا کے مختصر سرخیاں ہیں جو مشین لرننگ ماڈلز کو تربیت دینے کے لئے استعمال ہوتا ہے تاکہ وہ حساسیت تجزیہ، بولنی کی شناخت اور اشیاء کی تشخیص وغیرہ کیلئے کام کر سکے۔
ان نئے ڈیٹا بیسز نے بہت سی اطلاقات میں شاندار کارکردگی ظاہر کی ہے، جیسے کہ لغوی تلاش اور تجاویزی نظامات میں۔
کیا Qdrant ہے؟
Qdrant ایک اوپن سورس ویکٹر ڈیٹا بیس ہے جو اگلی نسل کے AI اطلاقات کے لئے مخصوص بنایا گیا ہے۔ یہ کلاؤڈ نیٹو ہے اور ایمبیڈنگز کو منظم کرنے کے لئے RESTful اور gRPC API فراہم کرتا ہے۔ Qdrant زبردست خصوصیات کو دعوت دیتا ہے، تصویر، آواز اور ویڈیو تلاش کا سپورٹ کرتا ہے، اور AI انجن کے ساتھ انسلاتا ہے۔
ویکٹر ڈیٹا بیس کیا ہے؟
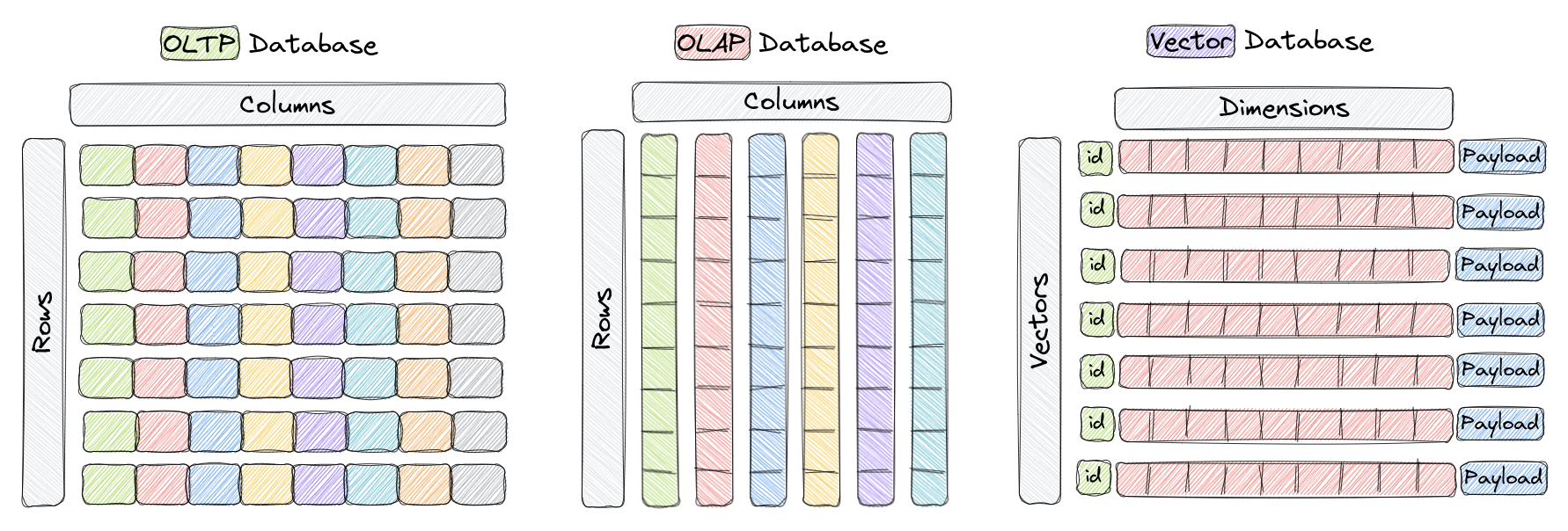
ویکٹر ڈیٹا بیس ایک خاص قسم کا ڈیٹا بیس ہے جو اہم بعدی ویکٹروں کے محفوظ ممالک اور کوئیر کرنے کے لئے خصوصی طور پر بنایا گیا ہے۔ عام طور پر OLTP اور OLAP ڈیٹا بیسوں میں (جیسا کہ فوٹو میں دکھایا گیا ہے)، ڈیٹا قطار اور ستونوں میں منظم کیا جاتا ہے (جو ٹیبلز کہلاتے ہیں)، اور کوئیریز ان ستونوں کی قیمتوں پر مبنی ہوتی ہیں۔ تاہم، کچھ اطلاقات میں مثلاً تصویر کی شناخت، قدرتی زبان کا عمل، اور تجاویزی نظامات، ڈیٹا عام طور پر بلند بعد میں ویکٹرز کی صورت میں پیش کیا جاتا ہے۔ یہ ویکٹروں کے ساتھ، ایک شناخت اور پیمانہ شماری، عنصر اور اثاثے سے مشمول ہیں جو Qdrant جیسے ویکٹر ڈیٹا بیسز میں ذخیرہ ہوتے ہیں۔
اس سنگھانس کے تنظیم میں، ایک ویکٹر ایک چیز یا ڈیٹا نقطے کا ریاضیائی تصور ہے، جہاں ویکٹر کے ہر عنصر کا ڈیٹا نقطے یا شعبی کا خصوصیت یا وصف کے مطابق ہے۔ مثال کے طور پر، ایک تصویر شناختی نظام میں، ایک ویکٹر ایک تصویر کو ظاہر کر سکتا ہے، جہاں ویکٹر کے ہر عنصر نے پکسل کی قیمتوں یا پکسل کی خصوصیت/وصف کی علامتیات کو ظاہر کرتا ہے۔ ایک موسیقی کی تجاویزی نظام میں، ہر ویکٹر ایک گانا کو ظاہر کرتا ہے، جہاں ویکٹر کے ہر عنصر نے گانے کی خصوصیات کو ظاہر کرتا ہے، جیسے کہ چال، جنر، مواضع وغیرہ۔
ویکٹر ڈیٹا بیس میں بلند بعد ویکٹروں کے مؤثر محفوظ اور کوئیرنگ کے لئے بہترین بناوٹ ہے، اور عام طور پر قریبی ترین ہمسایہ تلاش اور پروڈکٹ کوئیرئزیشن جیسے مخصوص ضروریات اور انڈیکسنگ تیکنیکوں کا استعمال کرتے ہیں، جیسے کہ ہائیئرارکل نیوگیبل سمول ورلڈ (HNSW)۔ یہ ڈیٹا بیس صارفین کو دیتا ہے کہ ہدیت ذریعہ کوئیر ویکٹر کے فراہم کردہ ہنگامی فاصلے کے مطابق، قریبی ہمسایہ تلاش اور لغوی تلاش میں تیزی دیتے ہیں۔ سب سے عام فاصلے کی پیمائی کی وہ کیمٹرکسیں میں شامل ہیں یورکلیڈیئن فاصلہ، کوسائن مماثلت، اور ڈاٹ پروڈکٹ، جو پوری طرح سے Qdrant میں حتمی طور پر حمایت کی جاتی ہیں۔
یہاں تین ویکٹر مماثلت الگورتھمات کا مختصر متعارف ہے:
- کوسائن مماثلت - کوسائن مماثلت دو اشیاء کے درمیان موافقت کی ایک پیمائی ہے۔ یہ دو نقطوں کے درمیان فاصلے کی پیمائی کا استعمال کرنے والے کے طور پر دیکھا جا سکتا ہے؛ تاہم، یہ دو اشیاء کے درمیان موافقت کو پیمائی کرتا ہے۔ یہ عام طور پر ٹیکسٹ میں دو دستاویزات یا جملوں کی مماثلت کے موازنے میں استعمال ہوتا ہے۔ کوسائن مماثلت کا آؤٹ پٹ 0 سے 1 تک ہوتا ہے، جہاں 0 مکمل اختلاف کو ظاہر کرتا ہے اور 1 مکمل موافقت کو ظاہر کرتا ہے۔ یہ دو اشیاء کو موازنہ کرنے کا ایک سادہ اور موثر طریقہ ہے!
- ڈاٹ پروڈکٹ - ڈاٹ پروڈکٹ مماثلت دو اشیاء کے درمیان میں ایک اور پیمائی ہے، جو کہ کوسائن مماثلت کے متکمل ہے۔ اعداد کے ساتھ کا کام کرنے میں، یہ عام طور پر مشین لرننگ اور ڈیٹا سائنس میں استعمال ہوتا ہے۔ ڈاٹ پروڈکٹ سمتیات میں مقداروں کو ضرب دینے کے بعد یہ مجموعہ دیتا ہے۔ زیادہ سم گزارتا ہے،وہ اشیاء کے دو سیٹ میں موافقت کی زیادہ خصوصیت کو ظاہر کرتا ہے۔ یہ دو سیٹ میں مچنے کی ڈری مقدار کو ناپنے والی ایک پیمائی ہے۔
- یورکلیڈئیئن فاصلہ - یورکلیڈیئین فاصلہ دو نقطوں کے درمیان فاصلے کی ایک ترکیب ہے، جیسا کہ ہم نقطوں کے درمیان نقطوں کے فرق کو نقاط کے مربع کے مجموعے کو ناپنے کی طرح دریافت کرتے ہیں۔ یہ فاصلہ ناپنے کی طریقہ کھلائی جاتی ہے۔ مشین لرننگ میں یہ عموماً دو ڈیٹا نقطوں کے مشابہت یا مختلفیت کو جاننے کے لئے استعمال ہوتا ہے، دوسرے الفاظ میں، یہ بات سمجھنے کو مدد کرتی ہے کہ دو نقطے کتنے دور ہیں۔
اب جب ہم جانتے ہیں کہ ویکٹر ڈیٹا بیس کیا ہے اور یہ ساخت کی روابط سے دوسرے ڈیٹا بیسوں سے مختلف ہوتے ہیں، ہم اس بات کو سمجھتے ہیں کہ یہ مشکل کیوں ہیں۔
ویکٹر ڈیٹا بیس کیوں ضروری ہے؟
ویکٹر ڈیٹا بیس مختلف اطلاقات میں اہم کردار ادا کرتے ہیں جو مشابہت تلاش کی ضرورت ہوتی ہے، جیسے تجاویزی نظامات، مواد پر مبنی تصاویر کی تلاش اور شخصی بنایا گیا تلاش۔ عمل کو موثر انڈیکسنگ اور تلاش کی تکنیکوں کا فائدہ ہوتا ہے، جو ویکٹر ڈیٹا بیس غیر مرتب ڈیٹا کو ویکٹر کی صورت میں تیزی سے اور درستی سے کھول سکتے ہیں، صارف کی سوال کو متعلقہ نتائج پیش کرتے ہیں۔
اس کے علاوہ، ویکٹر ڈیٹا بیس کا استعمال کرنے کے دیگر فوائد شامل ہیں:
- بلند بُعدی ڈیٹا کی موثر ذخیرہ اور انڈیکسنگ۔
- اربوں ڈیٹا پوائنٹس کے ساتھ بڑے پیمانے پر ڈیٹا سیٹس کا سنبھالنے کی صلاحیت۔
- ریل ٹائم تجزیہ اور سوالات کی حمایت۔
- مشکل ڈیٹا قسموں سے حاصل شدہ ویکٹروں کا سنبھالنا، جیسے تصاویر، ویڈیوز، اور زبانی متن۔
- مشین لرننگ اور اصطناعی ذہانت کے اطلاقات کی کارکردگی میں بہتری اور وقت میں کمی۔
- تخلیق اور نصب کرنے کے وقت اور لاگت میں کسٹم حل بنانے کے مقابلے میں کمی۔
براہ کرم نوٹ کریں کہ ویکٹر ڈیٹا بیس کا استعمال کرنے کے مخصوص فائدے آپ کی تنظیم کے استعمال کے مواقع اور منتخب ڈیٹا بیس کی کارکردگی پر منحصر ہو سکتے ہیں۔
اب ہم Qdrant معماری کا اعلی سطح کا جائزہ لیتے ہیں۔
Qdrant معماری کا اعلی سطحی جائزہ
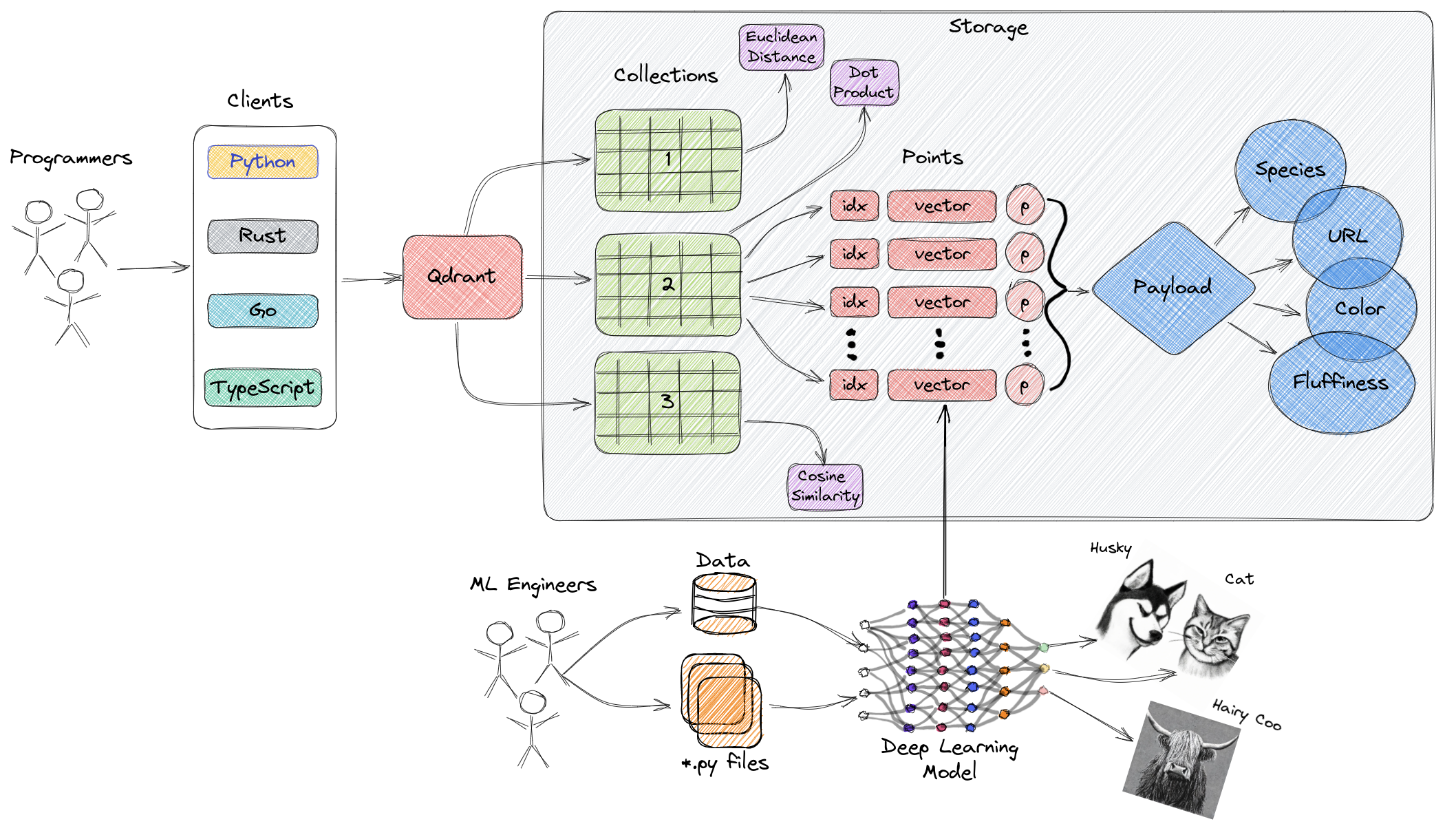
مذکورہ بالا خاکہ Qdrant کے اہم جزویں کی اعلی سطحی نظریہ فراہم کرتا ہے۔ زیر میں Qdrant کے متعلق اہم اصطلاحات ہیں:
- Collections: کلیکشنز نامک پوائنٹس (پیمانے والی ڈیٹا کے ساتھ ویکٹرز) کا ایک گروہ ہوتے ہیں۔ سادہ الفاظ میں، کلیکشنز مائی ایس کیو ایل کی طرح ہوتے ہیں، اور پوائنٹس یہ ڈیٹا کی میزان کی صفوں کی مانند ہوتے ہیں۔ ان پوائنٹس میں تلاش کی جا سکتی ہے۔ ہر کلیکشنز کے اندر ویکٹر کا ایک ہی بعد ہونا ضروری ہے اور ان کی موازنہ ایک ہی میٹرک کا استعمال کرکے ہوتی ہے۔ نامک ویکٹرز کو استعمال کیا جا سکتا ہے تاکہ ایک ہی پوائنٹ میں متعدد ویکٹرز ہوں جن میں ہر ایک کا اپنا بعد اور میٹرک کی ضرورت ہو۔
- Metric: ایک پیمائش جو ویکٹر کی مشابہت کو قیمت دینے میں استعمال ہوتی ہے، جو کلیکشن بنانے کے وقت منتخب ہونی چاہیے۔ میٹرک کا انتخاب ویکٹر حاصل کرنے کے طریقے پر منحصر ہوتا ہے، خاص طور پر نیورل نیٹ ورکس کے لئے (میٹرک وہ مشابہت الگورتم ہے جو ہم آپ کو منتخب کرتے ہیں)۔
- Points: پوائنٹس Qdrant کی طرف سے چلائے جانے والے بنیادی اکاونٹس ہیں جو ویکٹرز، اختیاری شناختی نمبر، اور پیمانے (مانند ایک مائی ایس کیو ایل کے صف ڈیٹا) کا مجموعہ ہوتے ہیں۔
- ID: ویکٹر کی یونیک شناختی سرکار۔
- Vector: ڈیٹا کی بلند بُعدی نمائندگی، مانند تصاویر، آڈیو، دستاویزات، ویڈیوز، وغیرہ۔
- Payload: ایک JSON شے جو ویکٹر کے ساتھ اضافی ڈیٹا کے طور پر شامل کیا جا سکتا ہے۔
- Storage: Qdrant دو ذخیرہ اختیارات استعمال کرسکتا ہے—ان-میموری ذخیرہ (تمام ویکٹرز کی میموری میں ذخیرہ ہوتے ہیں، جو بہترین رفتار فراہم کرتا ہے، کیونکہ ڈسک تک رسائی صرف پائرسسنس کے لئے استعمال ہوتی ہے) اور میم گینپ ذخیرہ (ڈسک پر فائلوں سے منسلک ورچوئل ایڈرس اسپیس بناتا ہے)۔
- Clients: آپ Qdrant سے پروگرامنگ زبان ایس ڈی کے کی ایس ڈیز یا اس کے REST اے پی آئی کے ذریعے وابستہ کر سکتے ہیں۔