
Bir vektör veritabanı, soyut veri temsilleri ile etkileşim kurmanın nispeten yeni bir yoludur. Bu temsiller, genellikle derin öğrenme yapıları gibi opak makine öğrenme modellerinden gelir ve genellikle vektörler veya gömme vektörleri olarak adlandırılır. Bunlar, duygu analizi, konuşma tanıma ve nesne tespiti gibi görevleri gerçekleştirmek üzere makine öğrenme modellerini eğitmek için kullanılan verilerin sıkıştırılmış sürümleridir.
Bu yeni veritabanları, anlamsal arama ve öneri sistemleri gibi birçok uygulamada olağanüstü performans göstermiştir.
Qdrant Nedir?
Qdrant, gelecek nesil yapay zeka uygulamaları için tasarlanmış açık kaynaklı bir vektör veritabanıdır. Bu, bulut doğal ve, gömülendirmeleri yönetmek için RESTful ve gRPC API'leri sunar. Qdrant, güçlü özelliklere sahiptir; görüntü, ses ve video aramasını destekler ve yapay zeka motorlarıyla entegrasyon sağlar.
Vektör Veritabanı Nedir?
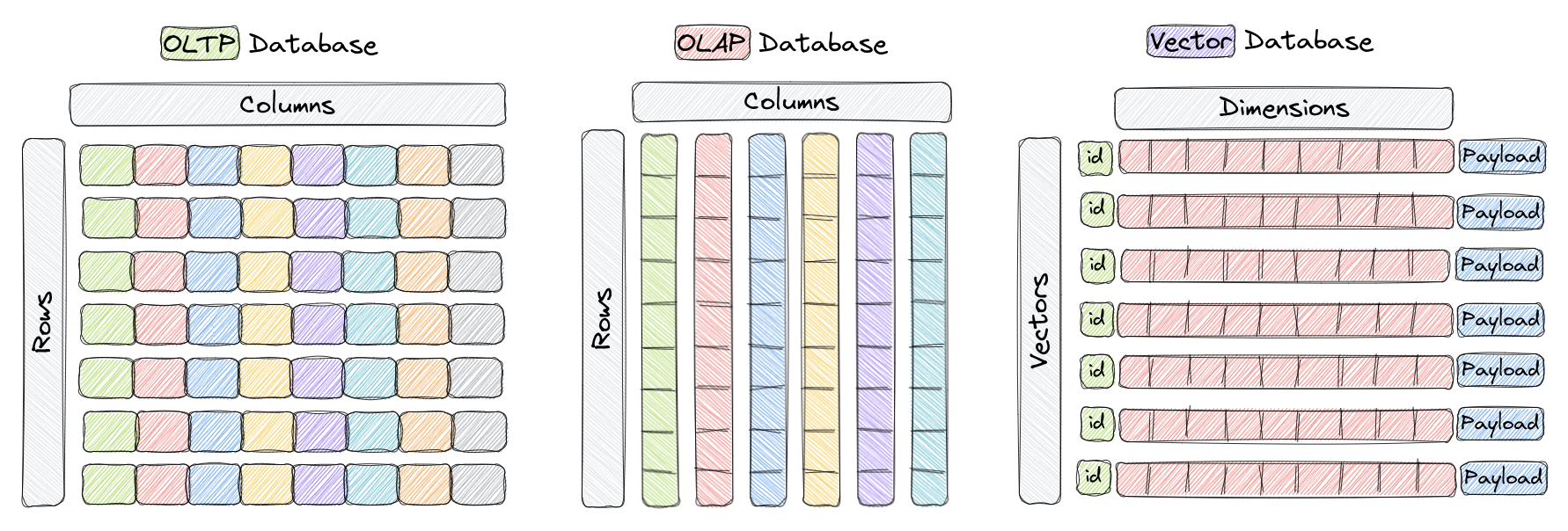
Vektör veritabanı, yüksek boyutlu vektörlerin etkili depolanması ve sorgulanması için özel olarak tasarlanmış bir veritabanı türüdür. Geleneksel OLTP ve OLAP veritabanlarında (yukarıdaki şekilde gösterildiği gibi), veri satır ve sütunlarda (table olarak adlandırılır) düzenlenir ve sorgular bu sütunlardaki değerlere dayanır. Ancak, görüntü tanıma, doğal dil işleme ve öneri sistemleri gibi bazı uygulamalarda, veri genellikle yüksek boyutlu uzayda vektörler olarak temsil edilir. Bu vektörler, bir kimlik ve yük ile birlikte, Qdrant gibi vektör veritabanlarında depolanan unsurları oluşturur.
Bu bağlamda, bir vektör, bir nesnenin veya veri noktasının matematiksel temsilidir ve vektörün her bir elemanı, nesnenin bir özelliğine veya niteliğine karşılık gelir. Örneğin, bir görüntü tanıma sisteminde, bir vektör bir görüntüyü temsil edebilir ve vektörün her elemanı, piksel değerlerini veya pikselin özelliğini / tanımlayıcısını temsil eder. Bir müzik öneri sisteminde, her vektör bir şarkıyı temsil eder ve vektörün her bir elemanı, şarkının özelliğini, ritmi, türü, sözleri vb. temsil eder.
Vektör veritabanları, yüksek boyutlu vektörlerin etkili depolanması ve sorgulanması için optimize edilmiştir ve yaklaşık en yakın komşu araması için Hiyerarşik Gezer Küçük Dünya (HNSW) gibi özel veri yapıları ve dizinleme tekniklerini kullanır. Bu veritabanları, belirli bir mesafe metriğine göre verilen bir sorgu vektörüne en yakın vektörleri bulmayı mümkün kılar, böylece hızlı benzerlik ve anlamsal arama sağlar. En yaygın olarak kullanılan mesafe metrikleri arasında, Qdrant'ta tamamen desteklenen Kosinüs Benzerliği, Nokta Çarpımı ve Öklid Mesafesi bulunur.
İşte bu üç vektör benzerlik algoritmasının kısa bir tanıtımı:
- Kosinüs Benzerliği - Kosinüs benzerliği, iki öğe arasındaki benzerliği ölçen bir ölçüdür. Bu, iki nokta arasındaki mesafeyi ölçmek için kullanılan bir cetvel olarak düşünülebilir; ancak mesafeyi ölçmek yerine, iki öğe arasındaki benzerliği ölçer. Metnin içindeki iki belge veya cümle arasındaki benzerliği karşılaştırmak için sıkça kullanılır. Kosinüs benzerliğinin çıkış aralığı, 0'dan 1'e kadar olan bir aralıktır, 0 tam benzersizliği, 1 tam benzerliği gösterir. İki öğe arasında karşılaştırma yapmanın basit ve etkili bir yoludur!
- Nokta Çarpımı - Nokta çarpımı benzerliği, kosinüs benzerliğine benzer şekilde, iki öğe arasındaki benzerliği ölçen bir ölçüdür. Sayılarla uğraşırken, genellikle makine öğrenimi ve veri bilimi alanlarında kullanılır. Nokta çarpımı benzerliği, iki sayı kümesindeki değerleri çarparak bu ürünleri toplamak suretiyle hesaplanır. Daha yüksek bir toplam, iki sayı kümesi arasındaki benzerliğin daha yüksek olduğunu gösterir. İki sayı kümesi arasındaki eşleşme derecesini ölçen bir ölçektir.
- Öklid Mesafesi - Öklid mesafesi, uzaydaki iki nokta arasındaki mesafeyi ölçmenin bir yoludur, bir haritada iki yer arasındaki mesafeyi ölçme şeklimize benzer. İki noktanın koordinatlarının farklarının karelerinin toplamının karekökünü bulmak suretiyle hesaplanır. Bu mesafe ölçüm yöntemi, iki veri noktasının benzerliğini veya farkını değerlendirmek için genellikle makine öğreniminde kullanılır, yani ne kadar uzak olduklarını anlamak için kullanılır.
Şimdi vektör veritabanlarının ne olduğunu ve diğer veritabanlarından yapısal olarak nasıl farklı olduğunu bildiğimize göre, neden önemli olduklarını anlayalım.
Vektör Veritabanına Neden İhtiyacımız Var?
Vektör veritabanları, öneri sistemleri, içerik tabanlı görüntü arama ve kişiselleştirilmiş aramalar gibi benzerlik arama gerektiren çeşitli uygulamalarda kritik bir rol oynar. Etkili dizinleme ve arama tekniklerinden faydalanarak vektör veritabanları, yapılandırılmamış veriyi vektörlerle temsil ederek kullanıcının sorgusuna en uygun sonuçları daha hızlı ve daha doğru bir şekilde sunabilir.
Ayrıca, vektör veritabanlarını kullanmanın diğer faydaları şunları içerir:
- Yüksek boyutlu verilerin verimli depolanması ve dizinlenmesi.
- Milyarlarca veri noktasını içeren büyük ölçekli veri kümelerini işleme yeteneği.
- Gerçek zamanlı analiz ve sorguları destekleme.
- Resimler, videolar ve doğal dil metinleri gibi karmaşık veri türlerinden türetilen vektörleri işleme yeteneği.
- Makine öğrenimi ve yapay zeka uygulamalarının performansını artırma ve gecikmeyi azaltma.
- Özel çözümler geliştirmek ve dağıtmakla karşılaştırıldığında, geliştirme ve dağıtım süresi ile maliyetlerin azaltılması.
Lütfen unutmayın ki vektör veritabanlarını kullanmanın belirli faydaları, kuruluşunuzun kullanım durumlarına ve seçilen veritabanı işlevlerine bağlı olarak değişebilir.
Şimdi, Qdrant mimarisinin yüksek düzeyli bir değerlendirmesini yapalım.
Qdrant Mimarisinin Yüksek Düzeyli Genel Bakışı
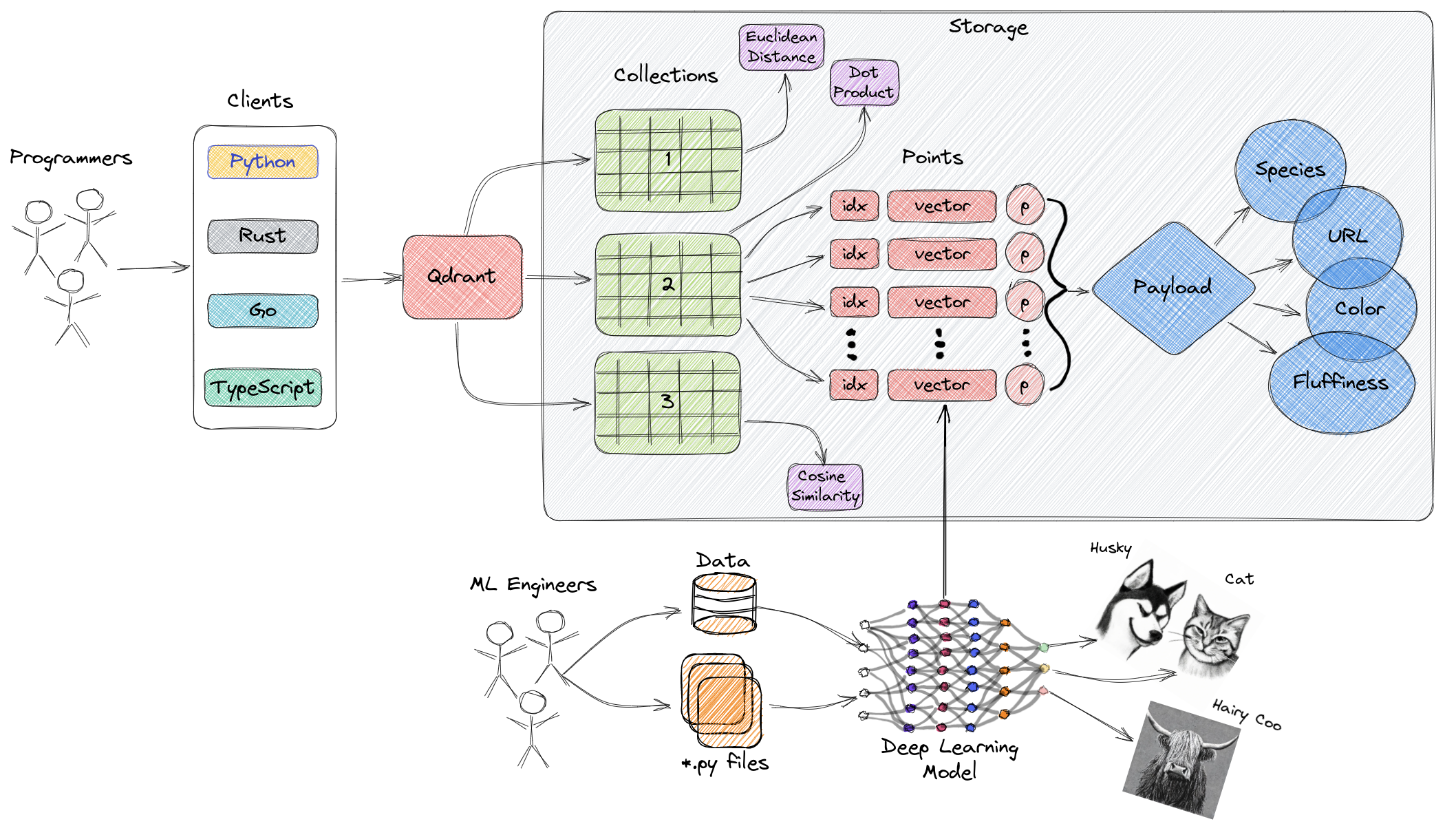
Yukarıdaki diyagram, Qdrant'ın ana bileşenlerinin yüksek düzeyli bir genel bakışını sağlar. Qdrant ile ilgili anahtar terimler aşağıdaki gibidir:
- Koleksiyonlar: Koleksiyonlar, adlandırılmış noktaların (yükleri olan vektörler ile esasen vektör verisi) bir grupu. Daha basit bir ifadeyle, koleksiyonlar MySQL'deki tablolara benzer, noktalar ise bu tablolar içindeki veri satırlarına benzer. Bu noktalar arasında arama yapılabilmektedir. Aynı koleksiyon içindeki her vektörün aynı boyuta sahip olması ve tek bir metrik kullanılarak karşılaştırılması gerekir. Adlandırılmış vektörler, her birinin kendi boyutu ve metrik gereksinimlerine sahip olduğu tek bir noktada birden fazla vektörün kullanılmasına olanak tanır.
- Metrik: Vektörler arasındaki benzerliği nicelendirmek için kullanılan bir ölçü. Bir koleksiyon oluşturulurken seçilmesi gereken metrik, özellikle yeni sorguları kodlamak için kullanılan sinir ağları için vektör edinme yöntemine bağlıdır (metrik, seçtiğimiz benzerlik algoritmasıdır).
- Noktalar: Noktalar, Qdrant tarafından işlenen temel varlıklardır ve vektörler, isteğe bağlı kimlikler ve yükleri (MySQL tablosundaki veri satırlarına benzer) içerir.
- Kimlik: Vektörün benzersiz tanımlayıcısı.
- Vektör: Resimler, sesler, belgeler, videolar vb. gibi yüksek boyutlu verilerin temsilidir.
- Yük: Vektöre ek veri olarak eklenen bir JSON nesnesi (vektörle ilişkilendirilmiş işletme özelliklerini depolamak için kullanılır).
- Depolama: Qdrant, iki depolama seçeneğinden yararlanabilir—hafızada depolama (tüm vektörler hafızada depolanır, kalıcılık için disk erişimi yalnızca kullanılır, böylece en yüksek hız sağlanır) ve Memmap depolama (diskteki dosyalarla ilişkilendirilmiş sanal bir adres alanı oluşturma).
- İstemciler: Qdrant'a programlama dilinde SDK'lar aracılığıyla bağlanabilir veya doğrudan REST API'sini kullanarak etkileşimde bulunabilirsiniz.