Поиск похожих объектов
Во многих приложениях машинного обучения поиск ближайших векторов является основным элементом. Современные нейронные сети обучаются преобразовывать объекты в векторы, что позволяет объектам, близким в векторном пространстве, также быть близкими в реальном мире. Например, тексты с похожими значениями, визуально похожие изображения или песни, принадлежащие к тому же жанру.
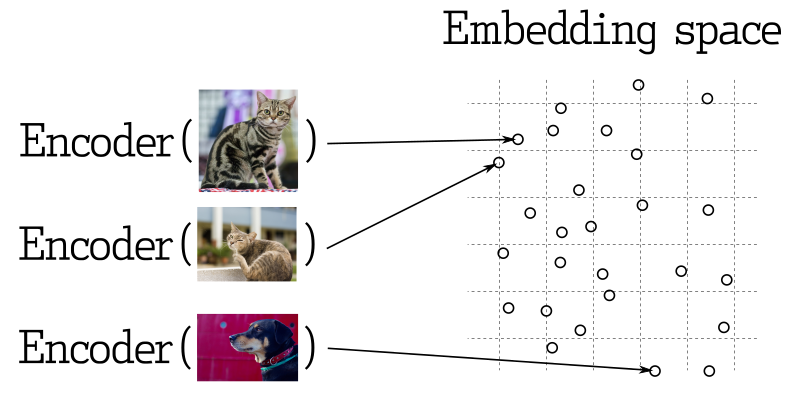
Измерение сходства
Существует множество методов оценки сходства между векторами. В Qdrant эти методы называются методами измерения сходства. Выбор метода зависит от того, как получены векторы, особенно от метода, используемого для обучения нейронной сети.
Qdrant поддерживает следующие наиболее распространенные типы измерений:
- Скалярное произведение:
Dot - Косинусное сходство:
Cosine - Евклидово расстояние:
Euclid
Наиболее часто используемым измерением в моделях обучения сходству является косинусное измерение.
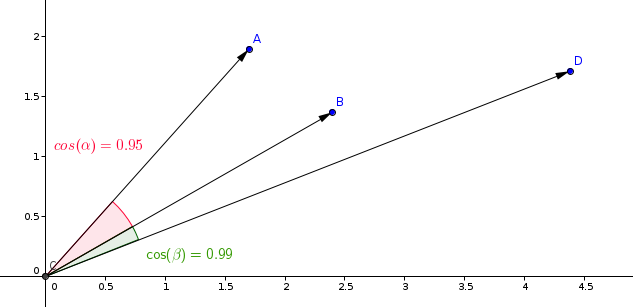
Qdrant вычисляет это измерение за два шага, что позволяет достичь более высокой скорости поиска. Первый шаг - нормализация векторов при добавлении их в коллекцию. Это делается только один раз для каждого вектора.
Второй шаг - сравнение векторов. В этом случае это эквивалентно операции скалярного произведения благодаря быстрым операциям SIMD.
План запроса
В зависимости от фильтров, используемых в поиске, существует несколько возможных сценариев выполнения запроса. Qdrant выбирает один из вариантов выполнения запроса на основе доступных индексов, сложности условий и кардинальности отфильтрованных результатов. Этот процесс называется планированием запроса.
Процесс выбора стратегии основан на эвристических алгоритмах и может изменяться в зависимости от версии. Однако общие принципы заключаются в следующем:
- Выполнять планы запросов независимо для каждого сегмента (для подробной информации о сегментах обратитесь к хранилищу).
- При низком количестве точек отдавать предпочтение полным сканированиям.
- Оценивать кардинальность отфильтрованных результатов перед выбором стратегии.
- Использовать индексы нагрузки для извлечения точек, если кардинальность низкая (см. индексы).
- Использовать индексы фильтруемых векторов, если кардинальность высока.
Пороги могут быть настроены независимо для каждой коллекции через файл конфигурации.
Поиск API
Давайте рассмотрим пример запроса поиска.
REST API - определения схемы API можно найти здесь.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
В этом примере мы ищем векторы, похожие на вектор [0.2, 0.1, 0.9, 0.7]. Параметр limit (или его алиас top) указывает количество наиболее похожих результатов, которые мы хотим получить.
Значения под ключом params указывают пользовательские параметры поиска. В настоящее время доступны следующие параметры:
-
hnsw_ef- указывает значение параметраefдля алгоритма HNSW. -
exact- указывает, следует ли использовать точный (ANN) параметр поиска. Если установлен в значение True, поиск может занять много времени, так как производится полное сканирование для получения точных результатов. -
indexed_only- использование этой опции может отключить поиск в сегментах, которые еще не построили векторный индекс. Это может быть полезно для минимизации влияния на производительность поиска во время обновлений. Использование этой опции может привести к частичным результатам, если коллекция еще не полностью проиндексирована, поэтому используйте ее только в случаях, когда требуется приемлемая последовательность событий.
Поскольку установлен параметр filter, поиск выполняется только среди точек, которые удовлетворяют критериям фильтрации. Для более подробной информации о возможных фильтрах и их функциональности, пожалуйста, обратитесь к разделу Фильтры.
Пример результат запроса для этого API может выглядеть так:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result содержит список обнаруженных точек, отсортированных по score.
Обратите внимание, что по умолчанию эти результаты не содержат нагрузки и векторные данные. Для получения сведений о том, как включить нагрузку и векторы в результаты, обратитесь к разделу Нагрузка и Векторы в Результатах.
Доступно с версии v0.10.0
Если коллекция создана с несколькими векторами, необходимо указать имя вектора, который будет использоваться для поиска:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
Поиск выполняется только между векторами с тем же именем.
Фильтрация результатов по оценке
Помимо фильтрации нагрузки, также может быть полезно фильтровать результаты с низкими оценками сходства. Например, если известно минимально допустимое значение оценки для модели и необходимо исключить любые результаты схожести ниже порогового значения, можно использовать параметр score_threshold для запроса поиска. Он исключит все результаты с оценками ниже указанного значения.
Этот параметр может исключать как более низкие, так и более высокие оценки, в зависимости от используемой метрики. Например, более высокие оценки в евклидовой метрике считаются более удаленными и, следовательно, будут исключены.
Нагрузка и Векторы в Результатах
По умолчанию метод извлечения не возвращает никакую сохраненную информацию, такую как нагрузку и векторы. Дополнительные параметры with_vectors и with_payload могут изменить это поведение.
Пример:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
Параметр with_payload также может использоваться для включения или исключения конкретных полей:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Пакетный поиск API
Доступно с версии v0.10.0
API пакетного поиска позволяет выполнять несколько запросов на поиск через один запрос.
Его семантика проста: n запросов на пакетный поиск эквивалентны n отдельным запросам на поиск.
Этот метод имеет несколько преимуществ. Логически, он требует меньше сетевых подключений, что само по себе представляет преимущество.
Более того, если у пакетных запросов одинаковый фильтр, пакетный запрос будет эффективно обработан и оптимизирован через планировщик запросов.
Это имеет значительное влияние на задержку при сложных фильтрах, так как промежуточные результаты могут быть общими для запросов.
Чтобы использовать его, просто упакуйте ваши запросы на поиск вместе. Конечно, все обычные атрибуты запроса на поиск доступны.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Лондон"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Лондон"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Результаты этого API содержат массив для каждого запроса на поиск.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Рекомендуемое API
Отрицательный вектор является экспериментальной функцией и не гарантировано работает со всеми типами вложений. Помимо обычных поисков, Qdrant также позволяет вам проводить поиск на основе нескольких векторов, уже хранящихся в коллекции. Этот API используется для векторного поиска закодированных объектов без участия нейронных сетевых кодировщиков.
Рекомендуемое API позволяет указывать несколько положительных и отрицательных идентификаторов векторов, и сервис объединит их в конкретный средний вектор.
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
Если указан только один положительный ID, этот запрос эквивалентен обычному поиску для вектора в этой точке.
Компоненты вектора с бОльшими значениями в отрицательном векторе наказываются, в то время как компоненты вектора с бОльшими значениями в положительном векторе усиливаются. Затем этот средний вектор используется для поиска наиболее похожих векторов в коллекции.
Определение схемы API для REST API можно найти здесь.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Лондон"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
Пример результата для этого API будет следующим:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Доступно с версии v0.10.0 и выше
Если коллекция создана с использованием нескольких векторов, имена используемых векторов должны быть указаны в запросе на рекомендацию:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
Параметр using указывает хранимый вектор, который будет использоваться для рекомендаций.
Пакетный API рекомендаций
Доступно с версии v0.10.0 и выше
Аналогично пакетному поисковому API, с похожим использованием и преимуществами, он может обрабатывать запросы на рекомендации пакетами.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Лондон"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Лондон"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
Результатом этого API будет массив для каждого запроса на рекомендации.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Пагинация
Доступно с версии v0.8.3
API поиска и рекомендаций позволяет пропустить первые несколько результатов поиска и возвращать только результаты, начиная с определенного смещения.
Пример:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Это эквивалентно извлечению 11-й страницы с 10 записями на странице.
Иметь большое значение смещения может привести к проблемам производительности, и метод извлечения на основе векторов обычно не поддерживает пагинацию. Без извлечения первых N векторов невозможно получить N-й ближайший вектор.
Однако использование параметра смещения может экономить ресурсы за счет уменьшения сетевого трафика и доступа к хранилищу.
При использовании параметра offset необходимо внутренне извлечь offset + limit точек, но обращаться только к полезной нагрузке и векторам тех точек, которые фактически возвращаются из хранилища.
Группировка API
Доступно с версии v1.2.0
Результаты могут быть сгруппированы на основе конкретного поля. Это будет очень полезно, когда у вас есть несколько точек для одного и того же элемента и вы хотите избежать избыточных записей в результатах.
Например, если у вас есть большой документ, разделенный на несколько фрагментов, и вы хотите выполнять поиск или рекомендации на основе каждого документа, вы можете сгруппировать результаты по идентификатору документа.
Предположим, что у нас есть точки с данными:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Используя API groups, вы сможете получить топ N точек для каждого документа, предполагая, что данные точки содержат идентификатор документа. Конечно, может возникнуть ситуация, когда лучшие N точки не могут быть найдены из-за недостатка точек или относительно большого расстояния от запроса. В каждом случае group_size - это параметр на усмотрение, аналогичный параметру limit.
Поиск по группам
REST API (Схема):
POST /collections/{collection_name}/points/search/groups
{
// То же самое, что и в обычном API поиска
"vector": [1.1],
...,
// Параметры группировки
"group_by": "document_id", // Путь к полю для группировки
"limit": 4, // Максимальное количество групп
"group_size": 2, // Максимальное количество точек в группе
}
Рекомендация группы
REST API (Схема):
POST /collections/{collection_name}/points/recommend/groups
{
// То же, что и в обычном API рекомендаций
"negative": [1],
"positive": [2, 5],
...,
// Параметры группировки
"group_by": "document_id", // Путь к полю для группировки
"limit": 4, // Максимальное количество групп
"group_size": 2, // Максимальное количество точек в группе
}
Независимо от того, является ли это поиском или рекомендацией, результаты вывода выглядят следующим образом:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
Группы сортируются по наивысшему баллу точек в каждой группе. Внутри каждой группы также происходит сортировка точек.
Если поле group_by точки является массивом (например, "document_id": ["a", "b"]), точка может быть включена в несколько групп (например, "document_id": "a" и document_id: "b").
Эта функциональность сильно зависит от предоставленного ключа group_by. Для повышения производительности убедитесь, что для него создан отдельный индекс. Ограничения:
- Параметр
group_byподдерживает только ключевые слова и целочисленные значения полезной нагрузки. Другие типы значений полезной нагрузки будут проигнорированы. - В настоящее время постраничная навигация не поддерживается при использовании групп, поэтому параметр
offsetне разрешен.
Поиск внутри групп
Доступно с версии v1.3.0
В случаях, когда для различных частей одного и того же элемента существует несколько точек, часто в хранимых данных возникает избыточность. Если общая информация между точками минимальна, это может быть приемлемо. Однако при более интенсивных нагрузках это может стать проблемой, поскольку расчет места хранения для точек происходит на основе количества точек в группе.
Оптимизация хранения при использовании групп заключается в хранении общей информации между точками с одним и тем же идентификатором группы в одной точке в другой коллекции. Затем, при использовании API групп, следует добавить параметр with_lookup для добавления этой информации для каждой группы.
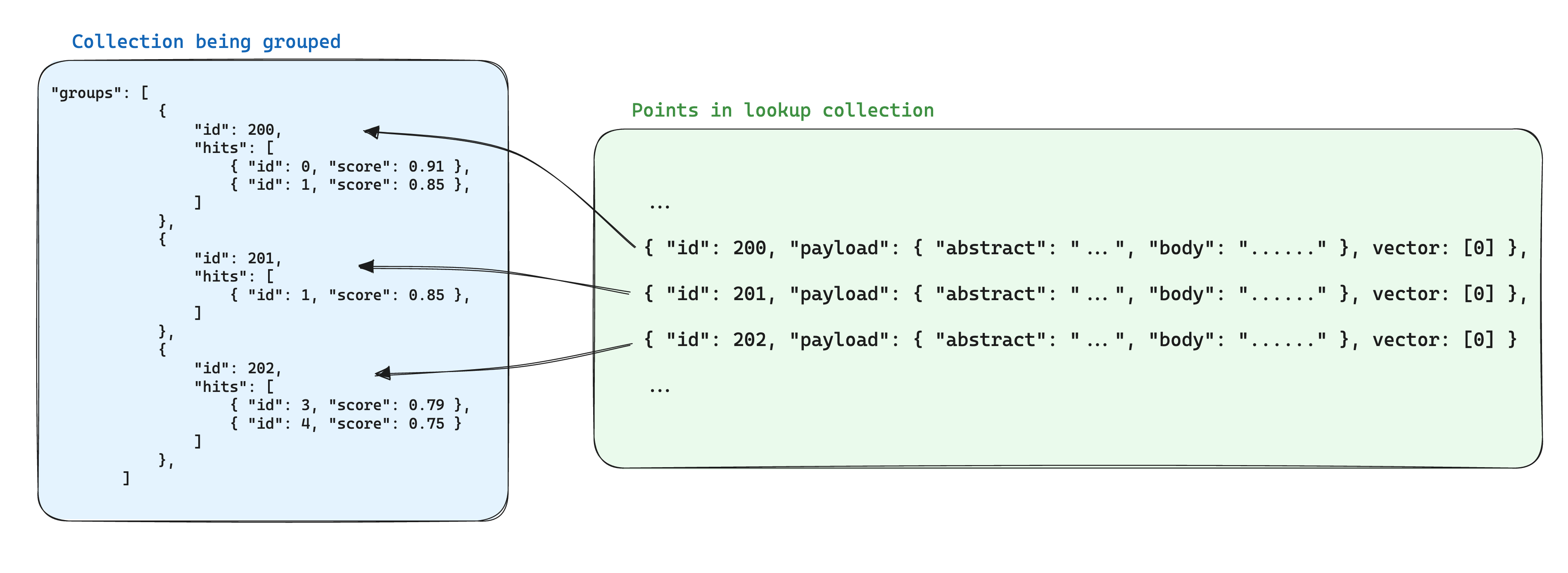
Дополнительным преимуществом такого подхода является то, что при изменении общей информации в точках группы, необходимо обновить только одну точку.
Например, если у вас есть коллекция документов, вы можете разбить их на части и хранить точки, принадлежащие этим частям, в отдельной коллекции, обеспечивая хранение идентификаторов точек, принадлежащих документам, в полезной нагрузке точки части.
В этом случае для переноса информации из документов в части, сгруппированные по идентификатору документа, можно использовать параметр with_lookup:
POST /collections/chunks/points/search/groups
{
// Те же параметры, что и в обычном поисковом API
"vector": [1.1],
...,
// Параметры группировки
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Параметры поиска
"with_lookup": {
// Имя коллекции точек для поиска
"collection": "documents",
// Параметры, указывающие содержание для включения из полезной нагрузки точек поиска, значение по умолчанию - true
"with_payload": ["title", "text"],
// Параметры, указывающие содержание для включения из векторов точек поиска, значение по умолчанию - true
"with_vectors": false
}
}
Для параметра with_lookup также может использоваться краткая форма with_lookup="documents", чтобы включить всю полезную нагрузку и векторы без явного указания.
Результаты поиска будут отображены в поле lookup под каждой группой.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Документ A",
"text": "Это документ A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Документ B",
"text": "Это документ B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Поскольку поиск осуществляется путем прямого сопоставления идентификаторов точек, все идентификаторы групп, которые не являются существующими (и допустимыми) идентификаторами точек, будут проигнорированы, и поле lookup будет пустым.