Búsqueda de similitud
En muchas aplicaciones de aprendizaje automático, buscar vectores cercanos es un elemento clave. Las redes neuronales modernas están entrenadas para transformar objetos en vectores, haciendo que los objetos cercanos en el espacio vectorial también estén cerca en el mundo real. Por ejemplo, texto con significados similares, imágenes visualmente similares o canciones pertenecientes al mismo género.
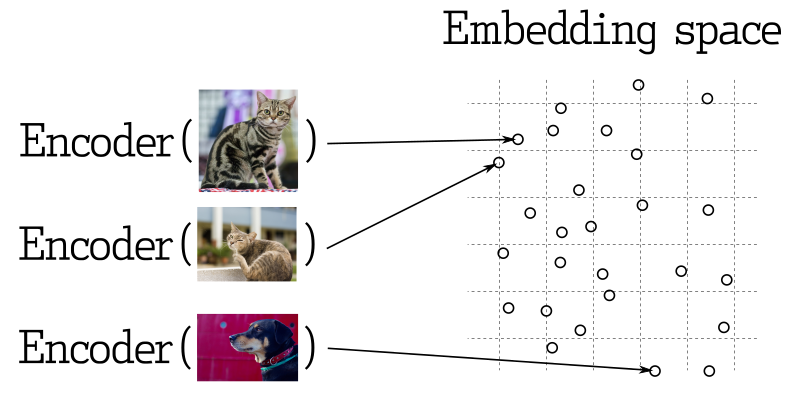
Medición de similitud
Existen muchos métodos para evaluar la similitud entre vectores. En Qdrant, estos métodos se llaman medidas de similitud. La elección de la medida depende de cómo se obtienen los vectores, especialmente el método utilizado para entrenar el codificador de la red neuronal.
Qdrant admite los siguientes tipos más comunes de medidas:
- Producto punto:
Dot - Similitud del coseno:
Cosine - Distancia euclidiana:
Euclid
La medida más comúnmente utilizada en modelos de aprendizaje de similitud es la medida del coseno.
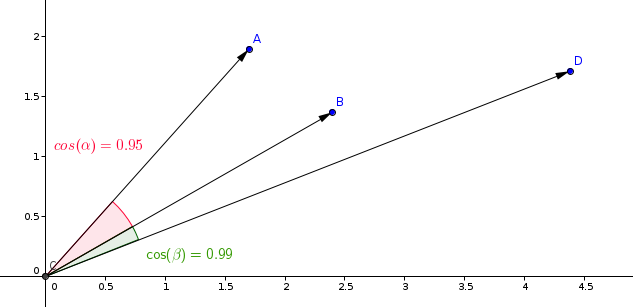
Qdrant calcula esta medida en dos pasos, logrando así velocidades de búsqueda más altas. El primer paso es normalizar los vectores al agregarlos a la colección. Esto se hace solo una vez para cada vector.
El segundo paso es la comparación de vectores. En este caso, es equivalente a una operación de producto punto, debido a las operaciones rápidas de SIMD.
Plan de consulta
Dependiendo de los filtros utilizados en la búsqueda, existen varios escenarios posibles para la ejecución de la consulta. Qdrant selecciona una de las opciones de ejecución de consulta en función de los índices disponibles, la complejidad de las condiciones y la cardinalidad de los resultados filtrados. Este proceso se llama planificación de consultas.
El proceso de selección de estrategia se basa en algoritmos heurísticos y puede variar según la versión. Sin embargo, los principios generales son:
- Ejecutar planes de consulta de forma independiente para cada segmento (para obtener información detallada sobre los segmentos, consulte el almacenamiento).
- Dar prioridad a escaneos completos si el número de puntos es bajo.
- Estimar la cardinalidad de los resultados filtrados antes de seleccionar una estrategia.
- Utilizar índices de carga útil para recuperar puntos si la cardinalidad es baja (consulte los índices).
- Utilizar índices de vectores filtrables si la cardinalidad es alta.
Los umbrales se pueden ajustar de forma independiente para cada colección a través del archivo de configuración.
API de Búsqueda
Echemos un vistazo a un ejemplo de una consulta de búsqueda.
REST API - Se pueden encontrar definiciones de esquema de API aquí.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
En este ejemplo, estamos buscando vectores similares al vector [0.2, 0.1, 0.9, 0.7]. El parámetro limit (o su alias top) especifica la cantidad de resultados más similares que queremos recuperar.
Los valores bajo la clave params especifican parámetros de búsqueda personalizados. Los parámetros actualmente disponibles son:
-
hnsw_ef- especifica el valor del parámetroefpara el algoritmo HNSW. -
exact- si usar la opción de búsqueda exacta (ANN). Si se establece en Verdadero, la búsqueda puede llevar mucho tiempo al realizar un escaneo completo para obtener resultados exactos. -
indexed_only- el uso de esta opción puede deshabilitar la búsqueda en segmentos que aún no han construido un índice de vector. Esto puede ser útil para minimizar el impacto en el rendimiento de búsqueda durante las actualizaciones. El uso de esta opción puede dar como resultado resultados parciales si la colección no está completamente indexada, por lo que úsela solo en casos donde se requiera una consistencia eventual aceptable.
Dado que se especifica el parámetro filter, la búsqueda solo se realiza entre puntos que cumplen con los criterios de filtrado. Para obtener información más detallada sobre los filtros posibles y sus funcionalidades, consulte la sección de Filtros.
Un resultado de muestra para esta API podría ser así:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
El resultado contiene una lista de puntos descubiertos ordenados por score.
Tenga en cuenta que por defecto, estos resultados carecen de datos de carga útil y vector. Consulte la sección de Carga útil y Vector en Resultados para saber cómo incluir la carga útil y los vectores en los resultados.
Disponible a partir de la versión v0.10.0
Si se crea una colección con varios vectores, se debe proporcionar el nombre del vector a utilizar para la búsqueda:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "imagen",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
La búsqueda solo se realiza entre vectores con el mismo nombre.
Filtrado de Resultados por Puntuación
Además del filtrado de carga útil, también puede ser útil filtrar los resultados con puntajes de similitud bajos. Por ejemplo, si conoce el puntaje mínimo aceptable para un modelo y no desea ningún resultado de similitud por debajo del umbral, puede usar el parámetro score_threshold para la consulta de búsqueda. Excluirá todos los resultados con puntajes inferiores al valor dado.
Este parámetro puede excluir tanto puntajes bajos como altos, dependiendo de la métrica utilizada. Por ejemplo, los puntajes más altos en la métrica euclidiana se consideran más alejados y, por lo tanto, serán excluidos.
Carga útil y Vectores en Resultados
Por defecto, el método de recuperación no devuelve ninguna información almacenada, como carga útil y vectores. Los parámetros adicionales with_vectors y with_payload pueden modificar este comportamiento.
Ejemplo:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
El parámetro with_payload también se puede utilizar para incluir o excluir campos específicos:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
API de Búsqueda en Lote
Disponible desde la versión v0.10.0
El API de búsqueda en lote permite ejecutar múltiples solicitudes de búsqueda a través de una única petición.
Su semántica es simple, n solicitudes de búsqueda en lote son equivalentes a n solicitudes de búsqueda separadas.
Este método tiene varias ventajas. Lógicamente, requiere menos conexiones de red, lo cual es beneficioso por sí mismo.
Más importante aún, si las solicitudes en lote tienen el mismo filtro, la solicitud en lote será manejada de manera eficiente y optimizada a través del planificador de consultas.
Esto tiene un impacto significativo en la latencia para filtros no triviales, ya que los resultados intermedios pueden compartirse entre solicitudes.
Para usarlo, simplemente empaquete sus solicitudes de búsqueda juntas. Por supuesto, están disponibles todos los atributos regulares de solicitud de búsqueda.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Los resultados de este API contienen un array para cada solicitud de búsqueda.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
API Recomendado
El vector negativo es una función experimental y no se garantiza que funcione con todos los tipos de embeddings. Además de las búsquedas regulares, Qdrant también le permite buscar basado en múltiples vectores ya almacenados en una colección. Este API se utiliza para la búsqueda de vectores de objetos codificados sin involucrar codificadores de redes neuronales.
El API de recomendaciones le permite especificar múltiples IDs de vectores positivos y negativos, y el servicio los fusionará en un vector promedio específico.
average_vector = avg(vectores_positivos) + (avg(vectores_positivos) - avg(vectores_negativos))
Si solo se proporciona un ID positivo, esta solicitud es equivalente a una búsqueda regular para el vector en ese punto.
Los componentes del vector con valores mayores en el vector negativo son penalizados, mientras que los componentes del vector con valores mayores en el vector positivo se amplifican. Este vector promedio se utiliza entonces para encontrar los vectores más similares en la colección.
La definición del esquema del API para el API REST se puede encontrar aquí.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
El resultado de muestra para este API será el siguiente:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Disponible desde la versión v0.10.0 en adelante
Si la colección se crea utilizando múltiples vectores, los nombres de los vectores que se están utilizando deben especificarse en la solicitud de recomendación:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "imagen",
"limit": 10
}
El parámetro using especifica el vector almacenado que se utilizará para la recomendación.
API de Recomendación en Lote
Disponible desde la versión v0.10.0 en adelante
Similar a la API de búsqueda en lote, con un uso y beneficios similares, puede procesar solicitudes de recomendación en lote.
POST /colecciones/{nombre_coleccion}/puntos/recomendar/lote
{
"búsquedas": [
{
"filtro": {
"debe": [
{
"clave": "ciudad",
"coincidencia": {
"valor": "Londres"
}
}
]
},
"negativo": [718],
"positivo": [100, 231],
"límite": 10
},
{
"filtro": {
"debe": [
{
"clave": "ciudad",
"coincidencia": {
"valor": "Londres"
}
}
]
},
"negativo": [300],
"positivo": [200, 67],
"límite": 10
}
]
}
El resultado de esta API contiene un array para cada solicitud de recomendación.
{
"resultado": [
[
{ "id": 10, "puntuación": 0.81 },
{ "id": 14, "puntuación": 0.75 },
{ "id": 11, "puntuación": 0.73 }
],
[
{ "id": 1, "puntuación": 0.92 },
{ "id": 3, "puntuación": 0.89 },
{ "id": 9, "puntuación": 0.75 }
]
],
"estado": "ok",
"tiempo": 0.001
}
Paginación
Disponible desde la versión v0.8.3
La API de búsqueda y recomendación permite omitir los primeros resultados de la búsqueda y solo devolver resultados a partir de un desplazamiento específico.
Ejemplo:
POST /colecciones/{nombre_coleccion}/puntos/buscar
{
"vector": [0.2, 0.1, 0.9, 0.7],
"con_vectores": true,
"con_carga_util": true,
"límite": 10,
"desplazamiento": 100
}
Esto es equivalente a recuperar la decimoprimera página, con 10 registros por página.
Tener un valor de desplazamiento grande puede provocar problemas de rendimiento, y el método de recuperación basado en vectores generalmente no admite la paginación. Sin recuperar los primeros N vectores, no es posible recuperar el N-ésimo vector más cercano.
Sin embargo, el uso del parámetro desplazamiento puede ahorrar recursos al reducir el tráfico de red y el acceso al almacenamiento.
Al utilizar el parámetro desplazamiento, es necesario recuperar internamente desplazamiento + límite puntos, pero solo acceder a la carga útil y a los vectores de aquellos puntos que realmente se devuelven desde el almacenamiento.
Agrupación de la API
Disponible desde la versión v1.2.0
Los resultados pueden agruparse en función de un campo específico. Esto será muy útil cuando tenga varios puntos para el mismo elemento y desee evitar entradas redundantes en los resultados.
Por ejemplo, si tiene un documento grande dividido en varios fragmentos y desea buscar o recomendar en función de cada documento, puede agrupar los resultados por ID de documento.
Supongamos que hay puntos con cargas útiles:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Usando la API de grupos, podrá obtener los primeros N puntos para cada documento, suponiendo que la carga útil del punto contiene el ID del documento. Por supuesto, puede haber casos en los que los mejores N puntos no puedan satisfacerse debido a la escasez de puntos o a una distancia relativamente grande desde la consulta. En cada caso, group_size es un parámetro de mejor esfuerzo, similar al parámetro limit.
Búsqueda de Grupo
API REST (Esquema):
POST /collections/{collection_name}/points/search/groups
{
// Igual que la API de búsqueda regular
"vector": [1.1],
...,
// Parámetros de agrupación
"group_by": "document_id", // La ruta del campo por la que agrupar
"limit": 4, // Número máximo de grupos
"group_size": 2, // Número máximo de puntos por grupo
}
Recomendación de Grupo
API REST (Esquema):
POST /colecciones/{nombre_coleccion}/puntos/recomendar/grupos
{
// Igual que la API de recomendación regular
"negativo": [1],
"positivo": [2, 5],
...,
// Parámetros de agrupación
"agrupar_por": "id_documento", // Ruta del campo por el cual agrupar
"limite": 4, // Número máximo de grupos
"tamano_grupo": 2, // Número máximo de puntos por grupo
}
Ya sea una búsqueda o una recomendación, los resultados de salida son los siguientes:
{
"resultado": {
"grupos": [
{
"id": "a",
"hits": [
{ "id": 0, "puntuacion": 0.91 },
{ "id": 1, "puntuacion": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "puntuacion": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "puntuacion": 0.79 },
{ "id": 4, "puntuacion": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "puntuacion": 0.6 }
]
}
]
},
"estado": "ok",
"tiempo": 0.001
}
Los grupos se ordenan por la puntuación más alta de los puntos dentro de cada grupo. Dentro de cada grupo, los puntos también se ordenan.
Si el campo agrupar_por de un punto es un array (por ejemplo, "id_documento": ["a", "b"]), el punto puede estar incluido en varios grupos (por ejemplo, id_documento: "a" y id_documento: "b").
Esta funcionalidad depende en gran medida de la clave agrupar_por proporcionada. Para mejorar el rendimiento, asegúrese de crear un índice dedicado para ello. Restricciones:
- El parámetro
agrupar_porsolo admite valores de carga útil de tipo palabra clave e entero. Se ignorarán otros tipos de valores de carga útil. - Actualmente, no se admite la paginación al utilizar grupos, por lo que el parámetro
offsetno está permitido.
Búsqueda dentro de Grupos
Disponible desde la v1.3.0
En casos donde hay múltiples puntos para distintas partes del mismo ítem, frecuentemente se introduce redundancia en los datos almacenados. Si la información compartida entre los puntos es mínima, esto puede ser aceptable. Sin embargo, puede volverse problemático con cargas más pesadas, ya que calculará el espacio de almacenamiento requerido para los puntos basado en el número de puntos en el grupo.
Una optimización para el almacenamiento al utilizar grupos es almacenar la información compartida entre puntos basados en el mismo ID de grupo en un solo punto dentro de otra colección. Luego, al usar la API de grupos, se agrega el parámetro with_lookup para añadir esta información para cada grupo.
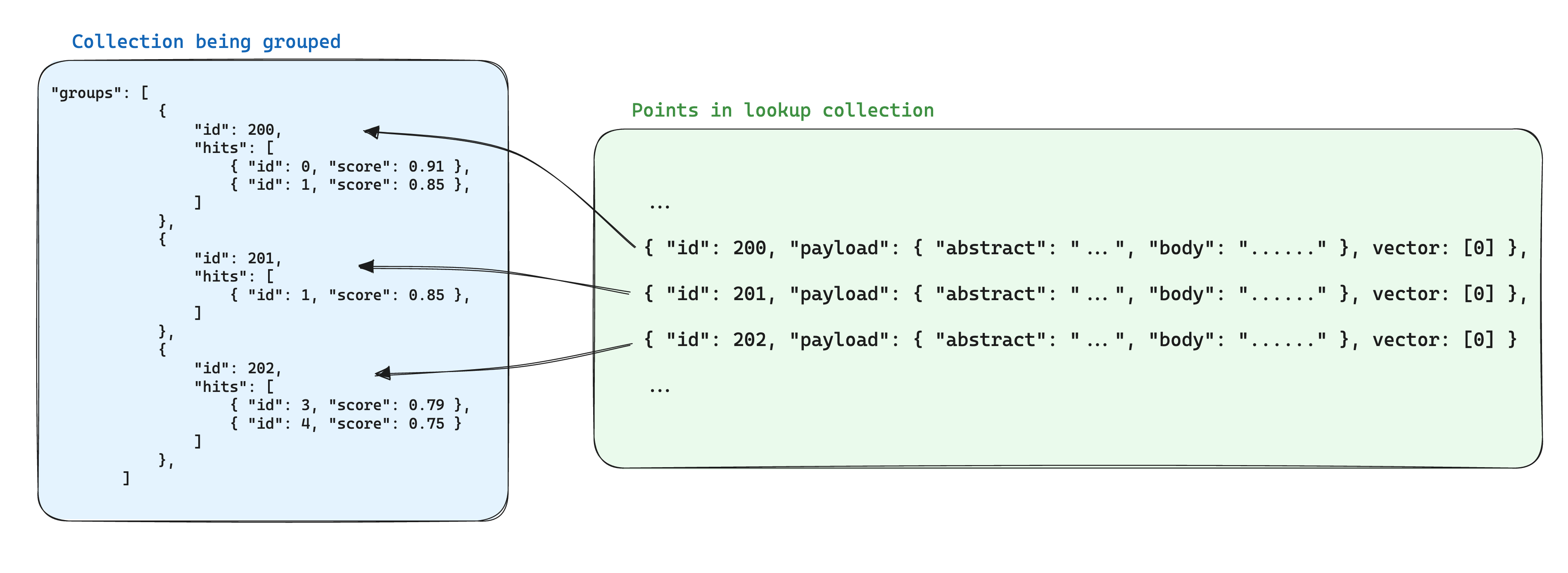
Un beneficio adicional de este enfoque es que cuando la información compartida dentro de los puntos de grupo cambia, solo es necesario actualizar el punto único.
Por ejemplo, si tienes una colección de documentos, es posible que desees dividirlos en fragmentos y almacenar los puntos pertenecientes a estos fragmentos en una colección separada, asegurando que los IDs de los puntos pertenecientes a los documentos se almacenen en la carga útil del punto de fragmento.
En este escenario, para llevar la información de los documentos a los fragmentos agrupados por ID de documento, se puede utilizar el parámetro with_lookup:
POST /colecciones/fragmentos/puntos/buscar/grupos
{
// Mismos parámetros que en la API de búsqueda regular
"vector": [1.1],
...,
// Parámetros de agrupación
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Parámetros de búsqueda
"with_lookup": {
// Nombre de la colección de los puntos a buscar
"collection": "documentos",
// Opciones especificando el contenido a traer de la carga útil de los puntos de búsqueda, por defecto es true
"with_payload": ["título", "texto"],
// Opciones especificando el contenido a traer de los vectores de los puntos de búsqueda, por defecto es true
"with_vectors": false
}
}
Para el parámetro with_lookup, también se puede utilizar una forma abreviada with_lookup="documentos" para traer toda la carga útil y vectores sin especificar explícitamente.
Los resultados de la búsqueda se mostrarán en el campo lookup debajo de cada grupo.
{
"resultado": {
"grupos": [
{
"id": 1,
"hits": [
{ "id": 0, "puntaje": 0.91 },
{ "id": 1, "puntaje": 0.85 }
],
"lookup": {
"id": 1,
"carga_útil": {
"título": "Documento A",
"texto": "Este es el documento A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "puntaje": 0.85 }
],
"lookup": {
"id": 2,
"carga_útil": {
"título": "Documento B",
"texto": "Este es el documento B"
}
}
}
]
},
"estado": "ok",
"tiempo": 0.001
}
Como la búsqueda se realiza mediante la coincidencia directa de los IDs de puntos, cualquier ID de grupo que no sea un ID de punto existente (y válido) será ignorado, y el campo lookup estará vacío.