Ricerca di similarità
In molte applicazioni di machine learning, la ricerca dei vettori più vicini è un elemento centrale. Le moderne reti neurali sono addestrate per trasformare gli oggetti in vettori, rendendo gli oggetti vicini nello spazio vettoriale anche vicini nel mondo reale. Ad esempio, testi con significati simili, immagini simili dal punto di vista visivo o brani appartenenti allo stesso genere.
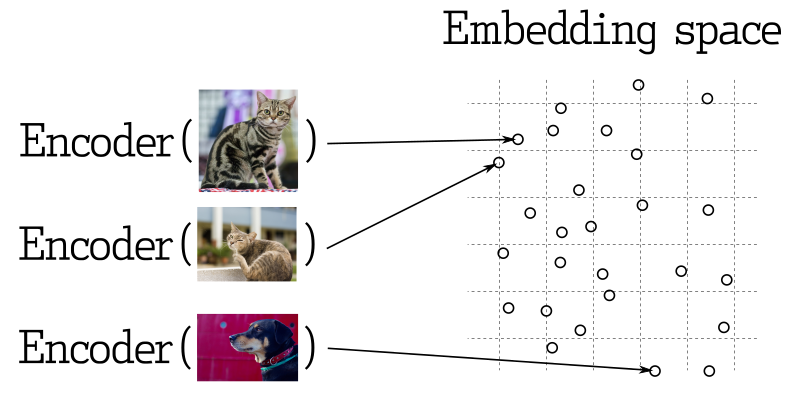
Misurazione della similarità
Ci sono molti metodi per valutare la similarità tra vettori. In Qdrant, questi metodi vengono chiamati misurazioni della similarità. La scelta della misurazione dipende dal modo in cui sono ottenuti i vettori, in particolare dal metodo utilizzato per addestrare l'encoder della rete neurale.
Qdrant supporta i seguenti tipi più comuni di misurazioni:
- Prodotto scalare:
Dot - Similarità del coseno:
Cosine - Distanza euclidea:
Euclid
La misurazione più comunemente utilizzata nei modelli di apprendimento della similarità è la misurazione del coseno.
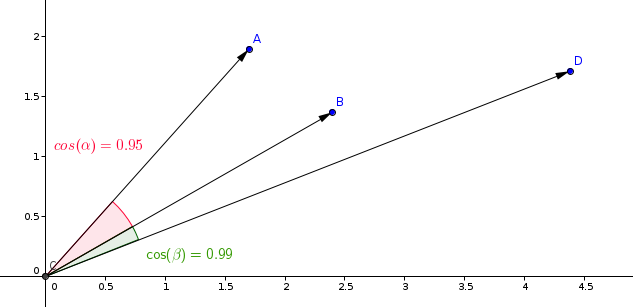
Qdrant calcola questa misurazione in due passaggi, ottenendo così velocità di ricerca più elevate. Il primo passaggio consiste nella normalizzazione dei vettori quando vengono aggiunti alla collezione. Questo viene fatto solo una volta per ciascun vettore.
Il secondo passaggio è il confronto tra vettori. In questo caso, è equivalente a un'operazione di prodotto scalare, grazie alle veloci operazioni di SIMD.
Pianificazione della query
A seconda dei filtri utilizzati nella ricerca, ci sono diversi scenari possibili per l'esecuzione della query. Qdrant seleziona una delle opzioni di esecuzione della query in base agli indici disponibili, alla complessità delle condizioni e alla cardinalità dei risultati filtrati. Questo processo è chiamato pianificazione della query.
Il processo di selezione della strategia si basa su algoritmi euristici e può variare in base alla versione. Tuttavia, i principi generali sono:
- Eseguire piani di query indipendentemente per ciascun segmento (per informazioni dettagliate sui segmenti, consultare lo storage).
- Dare priorità alle scansioni complete se il numero di punti è basso.
- Stimare la cardinalità dei risultati filtrati prima di selezionare una strategia.
- Utilizzare gli indici di payload per recuperare i punti se la cardinalità è bassa (vedere gli indici).
- Utilizzare gli indici di vettori filtrabili se la cardinalità è alta.
Le soglie possono essere regolate indipendentemente per ciascuna collezione tramite il file di configurazione.
API di ricerca
Diamo uno sguardo a un esempio di query di ricerca.
API REST - Le definizioni dello schema dell'API possono essere trovate qui.
POST /collections/{nome_collezione}/punti/ricerca
{
"filtro": {
"deve": [
{
"chiave": "città",
"corrispondenza": {
"valore": "Londra"
}
}
]
},
"parametri": {
"hnsw_ef": 128,
"esatto": false
},
"vettore": [0.2, 0.1, 0.9, 0.7],
"limite": 3
}
In questo esempio, stiamo cercando vettori simili al vettore [0.2, 0.1, 0.9, 0.7]. Il parametro limit (o il suo alias top) specifica il numero di risultati più simili che vogliamo recuperare.
I valori sotto il tasto parametri specificano i parametri di ricerca personalizzati. I parametri attualmente disponibili sono:
-
hnsw_ef- specifica il valore del parametroefper l'algoritmo HNSW. -
esatto- se utilizzare l'opzione di ricerca esatta (ANN). Se impostato su True, la ricerca potrebbe richiedere molto tempo in quanto effettua una scansione completa per ottenere risultati esatti. -
solo_indicizzati- utilizzando questa opzione è possibile disabilitare la ricerca nei segmenti che non hanno ancora costruito un indice vettoriale. Questo può essere utile per minimizzare l'impatto sulle prestazioni di ricerca durante gli aggiornamenti. L'utilizzo di questa opzione può comportare risultati parziali se la collezione non è pienamente indicizzata, quindi utilizzarla solo nei casi in cui è richiesta una consistenza eventualmente accettabile.
Poiché è specificato il parametro filtro, la ricerca viene effettuata solo tra i punti che soddisfano i criteri di filtro. Per informazioni più dettagliate su possibili filtri e le loro funzionalità, fare riferimento alla sezione Filtri.
Un risultato di esempio per questa API potrebbe essere il seguente:
{
"risultato": [
{ "id": 10, "punteggio": 0.81 },
{ "id": 14, "punteggio": 0.75 },
{ "id": 11, "punteggio": 0.73 }
],
"stato": "ok",
"tempo": 0.001
}
Il risultato contiene una lista di punti scoperti ordinati per punteggio.
Si noti che per impostazione predefinita, questi risultati mancano di dati di payload e vettore. Fare riferimento alla sezione Payload e Vettori nei Risultati su come includere payload e vettori nei risultati.
Disponibile dalla versione v0.10.0
Se viene creata una collezione con più vettori, deve essere fornito il nome del vettore da utilizzare per la ricerca:
POST /collections/{nome_collezione}/punti/ricerca
{
"vettore": {
"nome": "immagine",
"vettore": [0.2, 0.1, 0.9, 0.7]
},
"limite": 3
}
La ricerca viene effettuata solo tra i vettori con lo stesso nome.
Filtraggio dei Risultati per Punteggio
Oltre al filtraggio del payload, può essere utile filtrare i risultati con punteggi di similarità bassi. Ad esempio, se si conosce il punteggio minimo accettabile per un modello e non si desiderano risultati di similarità al di sotto della soglia, è possibile utilizzare il parametro soglia_punteggio per la query di ricerca. Esso escluderà tutti i risultati con punteggi inferiori al valore specificato.
Questo parametro può escludere sia punteggi più bassi che più alti, a seconda della metrica utilizzata. Ad esempio, punteggi più alti nella metrica euclidea sono considerati più lontani e quindi saranno esclusi.
Payload e Vettori nei Risultati
Per impostazione predefinita, il metodo di recupero non restituisce alcuna informazione memorizzata, come payload e vettori. I parametri aggiuntivi con_vettori e con_payload possono modificare questo comportamento.
Esempio:
POST /collections/{nome_collezione}/punti/ricerca
{
"vettore": [0.2, 0.1, 0.9, 0.7],
"con_vettori": true,
"con_payload": true
}
Il parametro con_payload può anche essere utilizzato per includere o escludere campi specifici:
POST /collections/{nome_collezione}/punti/ricerca
{
"vettore": [0.2, 0.1, 0.9, 0.7],
"con_payload": {
"escludi": ["città"]
}
}
API di Ricerca Batch
Disponibile dalla versione v0.10.0 in poi
L'API di ricerca batch consente di eseguire più richieste di ricerca tramite una singola richiesta.
La sua semantica è semplice, n richieste di ricerca batch sono equivalenti a n richieste di ricerca separate.
Questo metodo ha diversi vantaggi. Logicamente, richiede meno connessioni di rete, il che è già di per sé vantaggioso.
Inoltre, se le richieste batch hanno lo stesso filtro, la richiesta batch verrà gestita in modo efficiente e ottimizzata attraverso il pianificatore delle query.
Questo ha un impatto significativo sulla latenza per filtri non banali, in quanto i risultati intermedi possono essere condivisi tra le richieste.
Per utilizzarlo, basta raggruppare insieme le richieste di ricerca. Naturalmente, sono disponibili tutti gli attributi regolari delle richieste di ricerca.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
I risultati di questa API contengono un array per ciascuna richiesta di ricerca.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
API Consigliata
Il vettore negativo è una funzionalità sperimentale e non è garantito che funzioni con tutti i tipi di embedding. Oltre alle ricerche regolari, Qdrant consente anche di cercare basandosi su più vettori già memorizzati in una raccolta. Questa API è utilizzata per la ricerca vettoriale degli oggetti codificati senza coinvolgere gli encoder delle reti neurali.
L'API Consigliata consente di specificare più ID vettoriali positivi e negativi e il servizio li unirà in un vettore medio specifico.
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
Se è fornito solo un ID positivo, questa richiesta è equivalente a una ricerca regolare del vettore in quel punto.
I componenti vettoriali con valori più elevati nel vettore negativo vengono penalizzati, mentre i componenti vettoriali con valori più elevati nel vettore positivo vengono amplificati. Questo vettore medio viene quindi utilizzato per trovare i vettori più simili nella collezione.
La definizione dello schema API per l'API REST può essere trovata qui.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
Il risultato campione per questa API sarà il seguente:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Disponibile dalla versione v0.10.0 in poi
Se la raccolta viene creata utilizzando più vettori, i nomi dei vettori utilizzati dovrebbero essere specificati nella richiesta di raccomandazione:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "immagine",
"limit": 10
}
Il parametro using specifica il vettore memorizzato da utilizzare per la raccomandazione.
API di Raccomandazione Batch
Disponibile dalla versione v0.10.0 in poi
Simile all'API di ricerca batch, con un utilizzo e dei benefici simili, può elaborare le richieste di raccomandazione in blocco.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
Il risultato di questa API contiene un array per ciascuna richiesta di raccomandazione.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Paginazione
Disponibile dalla versione v0.8.3
L'API di ricerca e raccomandazione consente di saltare i primi risultati della ricerca e restituire solo i risultati a partire da un offset specifico.
Esempio:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Questo equivale a recuperare l'undicesima pagina, con 10 record per pagina.
Avere un valore di offset elevato può causare problemi di prestazioni e il metodo di recupero basato su vettori tipicamente non supporta la paginazione. Senza recuperare i primi N vettori, non è possibile recuperare l'N-esimo vettore più vicino.
Tuttavia, l'utilizzo del parametro offset può salvare risorse riducendo il traffico di rete e l'accesso alla memoria.
Quando si utilizza il parametro offset, è necessario recuperare internamente offset + limit punti, ma accedere solo al payload e ai vettori di quei punti effettivamente restituiti dalla memoria.
Raggruppamento API
Disponibile dalla versione v1.2.0
I risultati possono essere raggruppati in base a un campo specifico. Questo sarà molto utile quando si hanno punti multipli per lo stesso elemento e si desidera evitare voci ridondanti nei risultati.
Ad esempio, se si ha un documento grande diviso in più parti e si desidera cercare o raccomandare in base a ciascun documento, è possibile raggruppare i risultati per ID del documento.
Supponiamo ci siano punti con carichi:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Utilizzando l'API groups, sarà possibile ottenere i primi N punti per ciascun documento, assumendo che il carico utile del punto contenga l'ID del documento. Naturalmente, potrebbero verificarsi casi in cui i migliori N punti non possono essere soddisfatti a causa della scarsità di punti o di una distanza relativamente grande dalla query. In ogni caso, group_size è un parametro di massimo impegno, simile al parametro limit.
Ricerca Raggruppata
API REST (Schema):
POST /collections/{collection_name}/points/search/groups
{
// Uguale all'API di ricerca regolare
"vector": [1.1],
...,
// Parametri di raggruppamento
"group_by": "document_id", // Percorso del campo per raggruppare
"limit": 4, // Numero massimo di gruppi
"group_size": 2, // Numero massimo di punti per gruppo
}
Raccomandazione di Gruppo
API REST (Schema):
POST /collections/{nome_collezione}/points/recommend/groups
{
// Stesso come la normale API di raccomandazione
"negativo": [1],
"positivo": [2, 5],
...,
// Parametri di raggruppamento
"raggruppa_per": "document_id", // Percorso del campo su cui eseguire il raggruppamento
"limite": 4, // Numero massimo di gruppi
"dimensione_gruppo": 2, // Numero massimo di punti per gruppo
}
Indipendentemente che si tratti di una ricerca o di una raccomandazione, i risultati in uscita sono i seguenti:
{
"risultato": {
"gruppi": [
{
"id": "a",
"risultati": [
{ "id": 0, "punteggio": 0.91 },
{ "id": 1, "punteggio": 0.85 }
]
},
{
"id": "b",
"risultati": [
{ "id": 1, "punteggio": 0.85 }
]
},
{
"id": 123,
"risultati": [
{ "id": 3, "punteggio": 0.79 },
{ "id": 4, "punteggio": 0.75 }
]
},
{
"id": -10,
"risultati": [
{ "id": 5, "punteggio": 0.6 }
]
}
]
},
"stato": "ok",
"tempo": 0.001
}
I gruppi sono ordinati in base al punteggio più alto dei punti all'interno di ciascun gruppo. All'interno di ogni gruppo, i punti sono anche ordinati.
Se il campo raggruppa_per di un punto è un array (ad esempio, document_id: ["a", "b"]), il punto può essere incluso in più gruppi (ad esempio, document_id: "a" e document_id: "b").
Questa funzionalità dipende pesantemente dal campo raggruppa_per fornito. Per migliorare le prestazioni, assicurarsi di creare un indice dedicato per esso. Restrizioni:
- Il parametro
raggruppa_persupporta solo valori di payload di tipo parole chiave e interi. Altri tipi di valori payload verranno ignorati. - Attualmente, la paginazione non è supportata quando si utilizzano gruppi, quindi il parametro
offsetnon è consentito.
Ricerca all'interno dei gruppi
Disponibile dalla versione v1.3.0
Nei casi in cui vi siano più punti per diverse parti dello stesso elemento, è spesso introdotta della ridondanza nei dati memorizzati. Se le informazioni condivise tra i punti sono minime, questo potrebbe essere accettabile. Tuttavia, può diventare problematico con carichi più pesanti, in quanto calcolerà lo spazio di archiviazione richiesto per i punti in base al numero di punti nel gruppo.
Un'ottimizzazione per l'archiviazione quando si usano gruppi è quella di memorizzare le informazioni condivise tra i punti in base allo stesso ID del gruppo in un unico punto all'interno di un'altra raccolta. Quindi, quando si utilizza l'API groups, aggiungere il parametro with_lookup per aggiungere queste informazioni per ciascun gruppo.
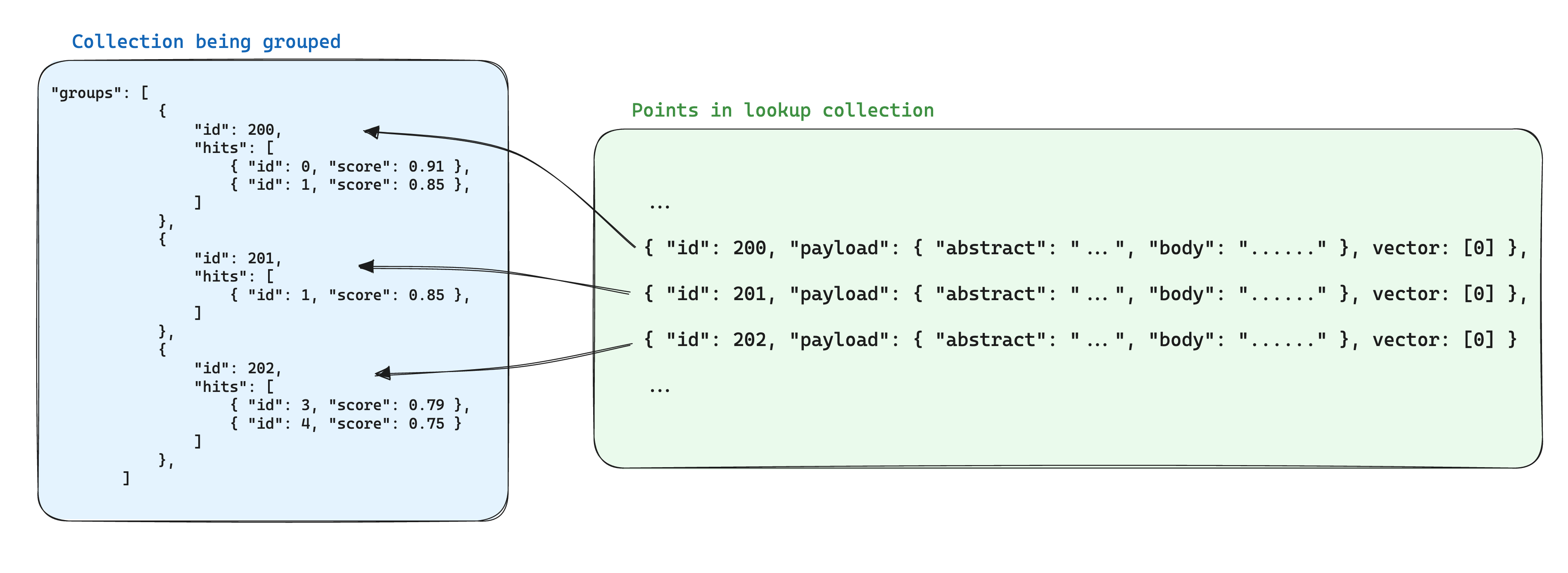
Un ulteriore vantaggio di questo approccio è che quando le informazioni condivise all'interno dei punti dei gruppi cambiano, è sufficiente aggiornare solo il singolo punto.
Ad esempio, se si ha una raccolta di documenti, potrebbe essere necessario suddividerli e memorizzare i punti appartenenti a questi frammenti in una raccolta separata, garantendo che gli ID dei punti appartenenti ai documenti siano memorizzati nel payload del punto del frammento.
In questo scenario, per portare le informazioni dai documenti nei frammenti raggruppati per ID del documento, può essere utilizzato il parametro with_lookup:
POST /collections/chunks/points/search/groups
{
// Stessi parametri dell'API di ricerca regolare
"vector": [1.1],
...,
// Parametri di raggruppamento
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Parametri di ricerca
"with_lookup": {
// Nome della raccolta dei punti da cercare
"collection": "documents",
// Opzioni specificando i contenuti da importare dal payload dei punti di ricerca, il valore predefinito è true
"with_payload": ["title", "text"],
// Opzioni specificando i contenuti da importare dai vettori dei punti di ricerca, il valore predefinito è true
"with_vectors": false
}
}
Per il parametro with_lookup, può essere utilizzato anche il comando abbreviato with_lookup="documents" per importare l'intero payload e i vettori senza specificarlo esplicitamente.
I risultati della ricerca verranno visualizzati nel campo lookup sotto ciascun gruppo.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Documento A",
"text": "Questo è il documento A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Documento B",
"text": "Questo è il documento B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Poiché la ricerca avviene tramite corrispondenza diretta degli ID dei punti, eventuali ID di gruppo che non siano punti esistenti (e validi) verranno ignorati, e il campo lookup sarà vuoto.