البحث عن الشبه
في العديد من تطبيقات التعلم الآلي، البحث عن أقرب البيانات النمطية يعتبر عنصراً أساسياً. يتم تدريب الشبكات العصبية الحديثة لتحويل الكائنات إلى متجهات، مما يجعل الكائنات القريبة في الفضاء المتجهي أيضاً قريبة في العالم الحقيقي. على سبيل المثال، النصوص ذات المعاني المشابهة، الصور المرئية المتشابهة، أو الأغاني المنتمية إلى نفس النوع.
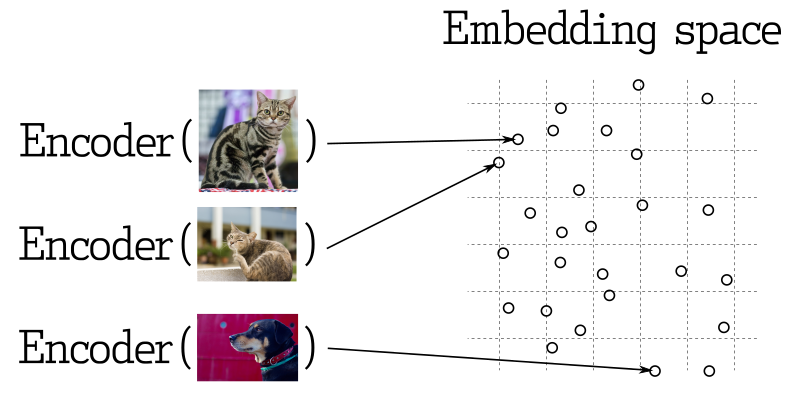
قياس الشبه
هناك العديد من الطرق لتقييم الشبه بين المتجهات. في Qdrant، تُسمى هذه الطرق بقياسات الشبه. اختيار القياس يعتمد على كيفية الحصول على المتجهات، خاصة الطريقة المستخدمة لتدريب مُشفر الشبكة العصبية.
يدعم Qdrant أنواع القياسات الأكثر شيوعاً التالية:
- الضرب الداخلي:
Dot - معامل التشابه الكوسيني:
Cosine - المسافة الأقليدية:
Euclid
أكثر القياسات استخداماً في نماذج التعلم على الشبه هو قياس التشابه الكوسيني.
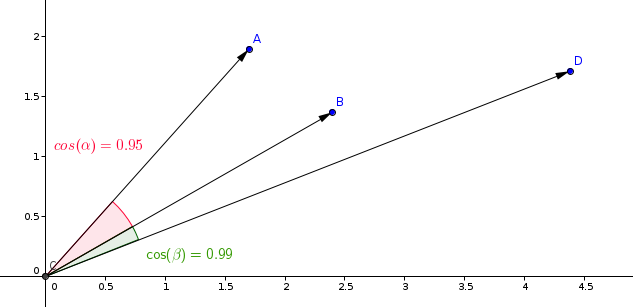
تقوم Qdrant بحساب هذا القياس في خطوتين، مما يؤدي إلى زيادة سرعة البحث. الخطوة الأولى هي تطبيع المتجهات عند إضافتها إلى المجموعة، ويتم ذلك مرة واحدة فقط لكل متجه.
الخطوة الثانية هي مقارنة المتجهات. في هذه الحالة، فإنها تعادل عملية الضرب الداخلي، نظراً لسرعة عمليات SIMD.
خطة الاستعلام
بناءً على المرشحات المستخدمة في البحث، هناك سيناريوهات محتملة عدة لتنفيذ الاستعلام. يختار Qdrant واحدة من خيارات تنفيذ الاستعلام بناءً على الفهارس المتاحة، وتعقيد الشروط، وتوزيع النتائج المرشحة. يُسمى هذا العملية بتخطيط الاستعلام.
يعتمد عملية اختيار الاستراتيجية على خوارزميات تقديرية وقد تختلف بحسب الإصدار. ومع ذلك، فإن المبادئ العامة هي:
- تنفيذ خطط الاستعلام بشكل مستقل لكل قطعة (للحصول على معلومات مفصلة حول القطع، يرجى الرجوع إلى التخزين).
- إعطاء الأولوية للمسح الكامل إذا كان عدد النقاط قليلاً.
- تقدير توزيع النتائج المرشحة قبل تحديد الاستراتيجية.
- استخدام فهارس الحمولة لاسترجاع النقاط إذا كانت توزيع النتائج المرشحة منخفضة (انظر الفهارس).
- استخدام فهارس المتجهات القابلة للفرز إذا كانت توزيع النتائج المرشحة مرتفعة.
يمكن ضبط الحدود بشكل مستقل لكل مجموعة من خلال ملف التكوين.
واجهة برمجة التطبيقات للبحث
دعنا نلقي نظرة على مثال لاستعلام البحث.
واجهة برمجة التطبيقات الراحة - يمكن العثور على تعريفات مخطط واجهة برمجة التطبيقات هنا.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
في هذا المثال، نبحث عن نواقص مشابهة للنقطة [0.2، 0.1، 0.9، 0.7]. المعلمة limit (أو ما يعادلها top) تحدد عدد النتائج المماثلة التي نريد استردادها.
القيم تحت مفتاح params تحدد معلمات البحث المخصصة. المعلمات المتاحة حاليًا هي:
-
hnsw_ef- يحدد قيمة معلمةefلخوارزمية HNSW. -
exact- ما إذا كان استخدام خيار البحث التقريبي (ANN) أم لا. إذا تم تعيينها على True، قد يستغرق البحث وقتًا طويلاً حيث يقوم بفحص كامل للحصول على النتائج الدقيقة. -
indexed_only- باستخدام هذا الخيار يمكن تعطيل البحث في الشرائح التي لم تبني بعد فهرس نقطي. قد يكون ذلك مفيدًا لتقليل التأثير على أداء البحث أثناء التحديثات. يمكن أن يؤدي استخدام هذا الخيار إلى نتائج جزئية إذا لم يتم فهرسة المجموعة بالكامل، لذا استخدمه فقط في الحالات التي يتطلب فيها الاتساق النهائي المقبول.
نظرًا لتحديد معلمة filter، يتم البحث فقط بين النقاط التي تستوفي معايير التصفية. للحصول على معلومات مفصلة حول الفلاتر الممكنة ووظائفها، يرجى الرجوع إلى قسم الفلاتر.
يمكن أن يبدو نتيجة نموذجية لهذه الواجهة كما يلي:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
تحتوي result على قائمة من النقاط المكتشفة مرتبة حسب score.
يرجى ملاحظة أنه بشكل افتراضي، تفتقد هذه النتائج الحمولة وبيانات الناقل. راجع القسم الخاص بالحمولة والنواقل في النتائج لمعرفة كيفية تضمين الحمولة والنواقل في النتائج.
متوفرة اعتبارًا من الإصدار v0.10.0
إذا تم إنشاء مجموعة بنفسُ اسم صفيحة بيانات، فيجب توفير اسم الصفيحة بيانات للاستفسار:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
يتم إجراء البحث فقط بين الصفائح بيانات بنفس الاسم.
تصفية النتائج حسب النقطة
بالإضافة إلى تصفية الحمولة، قد تكون من المفيد أيضًا تصفية النتائج ذات الدرجات التشابه المنخفضة. على سبيل المثال، إذا كنت تعرف النقطة الأدنى المقبولة لنموذج ولا ترغب في أي نتائج تشابه دون العتبة، يمكنك استخدام معلمة score_threshold لاستعلام البحث. سوف تستبعد جميع النتائج مع درجات أقل من القيمة المعطاة.
قد تستبعد هذه المعلمة كلًا من الدرجات المنخفضة والمرتفعة، اعتمادًا على القياس المستخدم. على سبيل المثال، تعتبر الدرجات العالية في القياس الإقليدي أبعد وبالتالي سيتم استبعادها.
الحمولة والنواقل في النتائج
من الافتراضي، لا يعيد طريقة الاسترداد أية معلومات مخزنة، مثل الحمولة والنواقل. يمكن أن تعدّل المعلمات الإضافية with_vectors و with_payload هذا السلوك.
مثال:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
يمكن استخدام المعلمة with_payload أيضًا لتضمين أو استبعاد حقول محددة:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
واجهة برمجة التطبيقات للبحث الدُفعي
متاحة اعتبارًا من الإصدار v0.10.0
واجهة برمجة التطبيقات للبحث الدُفعي تسمح بتنفيذ عدة طلبات بحث من خلال طلب واحد.
معناها بسيط، n طلبات بحث دُفعيّة مكافئة لـ n طلبات بحث منفصلة.
تمتلك هذه الطريقة عدة مزايا. من الناحية المنطقية، فهي تتطلب اتصالات شبكية أقل، مما يعود بالفائدة في حد ذاته.
الأهم من ذلك، إذا كانت الطلبات الدُفعية تحتوي على نفس المرشح، سيتم التعامل مع الطلب بكفاءة وتحسينه من خلال مخطط الاستعلام.
هذا يؤثر بشكل كبير على الكفاءة الزمنية للمرشحات غير التافهة، حيث يمكن مشاركة النتائج الوسيطة بين الطلبات.
لاستخدامها، ما عليك سوى تجميع طلبات البحث الخاصة بك معًا. بالطبع، جميع سمات طلب البحث العادي متاحة.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
نتائج هذه الواجهة تحتوي على مجموعة لكل طلب بحث.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
واجهة برمجة التطبيقات الموصى بها
المتجه السالب هو ميزة تجريبية ولا يتم ضمان عملها مع جميع أنواع التضمينات. بالإضافة إلى البحوث العادية، يسمح Qdrant أيضًا لك بالبحث استنادًا إلى متجهات متعددة مخزنة بالفعل في مجموعة البيانات. تُستخدم هذه واجهة برمجة التطبيقات للبحث في المتجهات المُشفرة دون الاعتماد على مُشفري شبكات عصبونية.
واجهة برمجة التطبيقات الموصى بها تسمح لك بتحديد معرفات متجه إيجابية وسلبية متعددة، وسيقوم الخدمة بدمجها في متجه متوسط معين.
متوسط_المتجه = متوسط(المتجهات_الإيجابية) + (متوسط(المتجهات_الإيجابية) - متوسط(المتجهات_السالبة) )
إذا تم توفير مُعرف إيجابي واحد فقط، فإن هذا الطلب مكافئ لبحث عادي للمتجه في ذلك النقطة.
يتم تغريم مكونات المتجه ذات القيم الأكبر في المتجه السالب، بينما يتم تعزيز مكونات المتجه ذات القيم الأكبر في المتجه الإيجابي. يُستخدم بعد ذلك المتوسط المتوسط للبحث عن المتجهات الأكثر تشابهًا في المجموعة.
يمكن العثور على تعريف مخطط واجهة برمجة التطبيقات لواجهة برمجة التطبيقات الداخلية على هذا الرابط.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
نتيجة عينة لهذه الواجهة ستكون كالتالي:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
متاحة ابتداءً من الإصدار v0.10.0
إذا تم إنشاء المجموعة باستخدام متجهات متعددة، يجب تحديد أسماء المتجهات المستخدمة في طلب الاقتراح:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
يُحدد المعلم المقدم المتجه المخزن لاستخدامه للإقتراح.
دفعة الواجهة البرمجية الموصى بها
متاحة اعتبارًا من الإصدار v0.10.0
مماثلة لواجهة البحث الدفعي، مع استخدام وفوائد مماثلة، يمكن أن تعالج طلبات التوصية دفعيًا.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
نتيجة هذه الواجهة البرمجية تحتوي على مصفوفة لكل طلب توصية.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
ترقيم الصفحات
متاحة من الإصدار v0.8.3
تسمح واجهة برمجة الواجهة والبحث بتخطي النتائج الأولى للبحث وإرجاع النتائج اعتبارًا من إزاحة محددة.
مثال:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
هذا يعادل استرجاع الصفحة الحادية عشرة، مع 10 سجلات في كل صفحة.
قد يؤدي وجود قيمة إزاحة كبيرة إلى مشاكل في الأداء، وعادةً ما لا تدعم طريقة الاسترجاع بناء الناقل ترقيم الصفحات. بدون استرجاع الناقلات الأولى N، لا يمكن استرجاع Nth ناقل الأقرب.
ومع ذلك، يمكن أن يوفر استخدام معلمة الإزاحة موارد عن طريق تقليل حركة المرور عبر الشبكة والوصول إلى التخزين.
عند استخدام معلمة الإزاحة، يجب استرجاع الإزاحة + الحد الأقصى من النقاط داخليًا، ولكن الوصول إلى الحمولة والناقلات لتلك النقاط التي يتم في الواقع إرجاعها فقط من التخزين.
تجميع واجهة برمجة التطبيقات
متوفر اعتبارًا من الإصدار v1.2.0
يمكن تجميع النتائج استنادًا إلى حقل محدد. سيكون هذا مفيدًا للغاية عندما تكون لديك نقاط متعددة لنفس العنصر وترغب في تجنب الإدخالات المتكررة في النتائج.
على سبيل المثال، إذا كان لديك وثيقة كبيرة مقسمة إلى أجزاء متعددة وترغب في البحث أو التوصية بناءً على كل وثيقة، يمكنك تجميع النتائج حسب معرف الوثيقة.
لنفترض أن هناك نقاطًا بحمولات:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
من خلال واجهة المجموعات، ستكون قادرًا على استرداد أفضل N نقطة لكل وثيقة، بشرط أن تحتوي حمولة النقطة على معرف الوثيقة. بالطبع، قد تكون هناك حالات حيث لا يمكن تحقيق أفضل N نقطة بسبب نقص في النقاط أو بسبب مسافة كبيرة نسبيًا عن الاستعلام. في كل حالة، يعتبر group_size معلمة تسعى جاهدة، على غرار معلمة limit.
البحث المجموع
واجهة برمجة التطبيقات REST (مخطط):
POST /collections/{collection_name}/points/search/groups
{
// نفس واجهة البحث العادية
"vector": [1.1],
...,
// معلمات التجميع
"group_by": "document_id", // مسار الحقل المستخدم للتجميع
"limit": 4, // الحد الأقصى لعدد المجموعات
"group_size": 2, // الحد الأقصى لعدد النقاط في كل مجموعة
}
توصية المجموعة
REST API (مخطط):
POST /collections/{collection_name}/points/recommend/groups
{
// نفس ما في واجهة برمجة التطبيقات العادية
"negative": [1],
"positive": [2, 5],
...,
// معلمات التجميع
"group_by": "document_id", // مسار الحقل للتجميع حسبه
"limit": 4, // الحد الأقصى لعدد المجموعات
"group_size": 2, // الحد الأقصى لعدد النقاط في كل مجموعة
}
بغض النظر عن ما إذا كانت عملية بحث أم توصية، فإن نتائج الإخراج كما يلي:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
تم فرز المجموعات حسب أعلى تصنيف للنقاط داخل كل مجموعة. في داخل كل مجموعة، يتم أيضاً فرز النقاط.
إذا كان حقل group_by لنقطة هو مصفوفة (مثال: "document_id": ["a", "b"]، يمكن أن تكون النقطة مضمنة في عدة مجموعات (مثال: "document_id": "a" و document_id: "b").
تعتمد هذه الوظيفة بشكل كبير على مفتاح group_by المقدم. لتحسين الأداء، تأكد من إنشاء فهرس مخصص له. قيود:
- يدعم معلمة
group_byفقط قيم حمولة كلمة مرور وعددية. سيتم تجاهل أنواع قيم حمولة أخرى. - حالياً، لا يتم دعم تقسيم الصفحات عند استخدام المجموعات، لذلك لا يُسمح بمعلمة
offset.
البحث ضمن المجموعات
متاح منذ الإصدار v1.3.0
في الحالات التي تحتوي فيها على عدة نقاط لأجزاء مختلفة من نفس العنصر، غالبًا ما يتم إدخال تكرار في البيانات المخزنة. إذا كانت المعلومات المشتركة بين النقاط دقيقة، فقد يكون ذلك مقبولًا. ومع ذلك، يمكن أن يصبح مشكلة عندما يزيد العبء، حيث سيتم حساب مساحة التخزين المطلوبة للنقاط بناءً على عددها في المجموعة.
أحد الأمثلة لتحسين التخزين عند استخدام المجموعات هو تخزين المعلومات المشتركة بين النقاط بناءً على نفس معرف المجموعة في نقطة واحدة ضمن مجموعة أخرى. ثم، عند استخدام API المجموعات، يتم إضافة معلومات معرفة إلى كل مجموعة باستخدام معامل with_lookup.
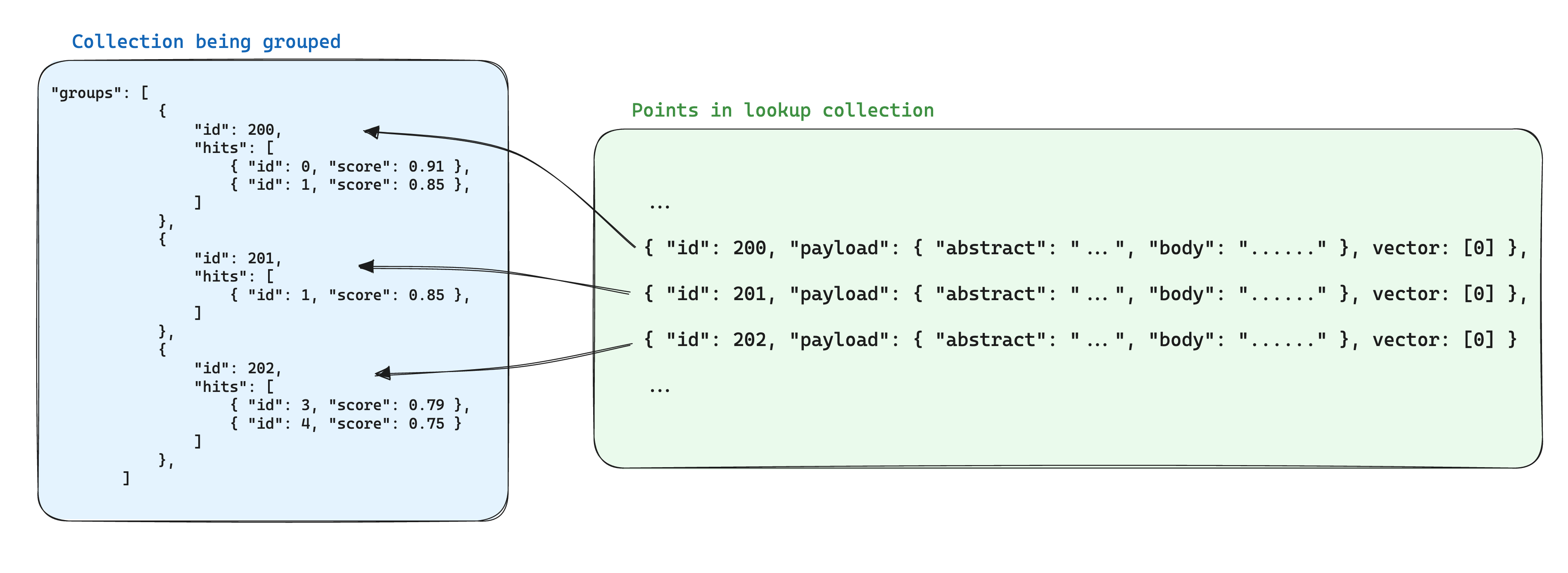
فائدة إضافية لهذا النهج هي أنه عند تغيير المعلومات المشتركة داخل نقاط المجموعة، سيتعين تحديث النقطة الواحدة فقط.
على سبيل المثال، إذا كان لديك مجموعة من المستندات، قد ترغب في تجزئتها وتخزين النقاط التي تنتمي إلى هذه القطع في مجموعة مستقلة، مضمنة معرفي النقاط المنتمية إلى المستندات في حمولة نقطة القطع.
في هذ scenاريو، يمكن استخدام معامل with_lookup لجلب المعلومات من المستندات إلى القطع المجموعة حسب معرّف المستند:
POST /collections/chunks/points/search/groups
{
// نفس المعاملات كما في API البحث العادي
"vector": [1.1],
...,
// معاملات التجميع
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// معاملات البحث
"with_lookup": {
// اسم المجموعة للنقاط المراد البحث فيها
"collection": "documents",
// خيارات تحديد المحتوى المطلوب جلبه من حمولة نقط البحث، القيمة الافتراضية هي true
"with_payload": ["title", "text"],
// خيارات تحديد المحتوى المطلوب جلبه من فيكتورات نقط البحث، القيمة الافتراضية هي true
"with_vectors": false
}
}
بالنسبة إلى معامل with_lookup، يمكن أيضا استخدام "معامل اختصاري" with_lookup="documents" لجلب الحمولة والفيكتورات بالكامل دون تحديد صراحي.
سيتم عرض نتائج البحث في الحقل lookup تحت كل مجموعة.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "مستند أ",
"text": "هذا هو مستند أ"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "مستند ب",
"text": "هذا هو مستند ب"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
نظرًا لأن البحث يتم عن طريق مطابقة معرّفات النقاط مباشرة، سيتم تجاهل أي معرّفات مجموعة غير موجودة (وصالحة) وستكون حقل "البحث" فارغة.