Recherche de similarité
Dans de nombreuses applications d'apprentissage automatique, la recherche des vecteurs les plus proches est un élément clé. Les réseaux neuronaux modernes sont entraînés à transformer des objets en vecteurs, rendant les objets proches dans l'espace vectoriel également proches dans le monde réel. Par exemple, du texte ayant des significations similaires, des images visuellement similaires ou des chansons appartenant au même genre.
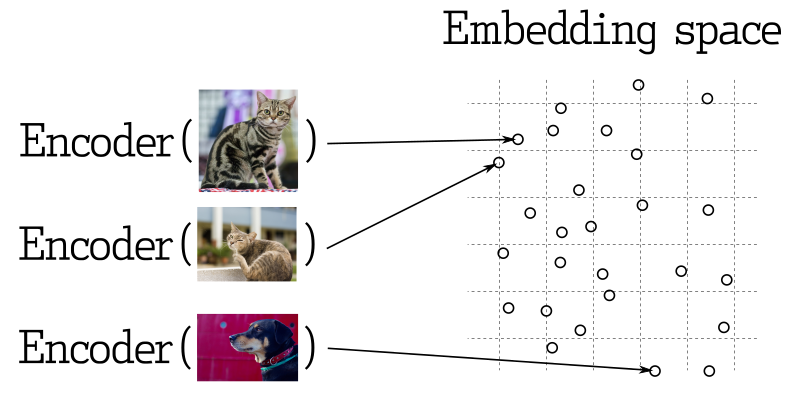
Mesure de similarité
Il existe de nombreuses méthodes pour évaluer la similarité entre des vecteurs. Dans Qdrant, ces méthodes sont appelées mesures de similarité. Le choix de la mesure dépend de la façon dont les vecteurs sont obtenus, en particulier de la méthode utilisée pour entraîner le codeur de réseau neuronal.
Qdrant prend en charge les types de mesures les plus courants suivants :
- Produit scalaire :
Dot - Similarité cosinus :
Cosine - Distance euclidienne :
Euclid
La mesure la plus couramment utilisée dans les modèles d'apprentissage de similarité est la mesure de cosinus.
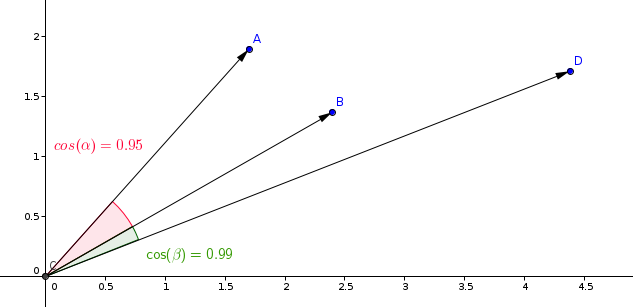
Qdrant calcule cette mesure en deux étapes, ce qui permet d'obtenir des vitesses de recherche plus élevées. La première étape consiste à normaliser les vecteurs lors de leur ajout à la collection. Ceci n'est fait qu'une fois pour chaque vecteur.
La deuxième étape est la comparaison de vecteurs. Dans ce cas, elle est équivalente à une opération de produit scalaire, en raison des opérations rapides de SIMD.
Plan de requête
Selon les filtres utilisés dans la recherche, plusieurs scénarios possibles d'exécution de requête existent. Qdrant sélectionne l'une des options d'exécution de requête en fonction des index disponibles, de la complexité des conditions et de la cardinalité des résultats filtrés. Ce processus est appelé planification de requête.
Le processus de sélection de stratégie repose sur des algorithmes heuristiques et peut varier selon la version. Cependant, les principes généraux sont les suivants :
- Exécuter des plans de requête de manière indépendante pour chaque segment (pour des informations détaillées sur les segments, veuillez vous référer au stockage).
- Prioriser les analyses complètes si le nombre de points est faible.
- Estimer la cardinalité des résultats filtrés avant de sélectionner une stratégie.
- Utiliser des index de charge utile pour récupérer des points si la cardinalité est faible (voir les indexes).
- Utiliser des indexes de vecteurs filtrables si la cardinalité est élevée.
Les seuils peuvent être ajustés de manière indépendante pour chaque collection via le fichier de configuration.
API de recherche
Examinons un exemple de requête de recherche.
REST API - Les définitions de schéma d'API peuvent être trouvées ici.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
Dans cet exemple, nous recherchons des vecteurs similaires au vecteur [0.2, 0.1, 0.9, 0.7]. Le paramètre limit (ou son alias top) spécifie le nombre de résultats les plus similaires que nous voulons récupérer.
Les valeurs sous la clé params spécifient des paramètres de recherche personnalisés. Les paramètres actuellement disponibles sont :
-
hnsw_ef- spécifie la valeur du paramètreefpour l'algorithme HNSW. -
exact- s'il faut utiliser l'option de recherche exacte (ANN). Si défini sur True, la recherche peut prendre beaucoup de temps car elle effectue un balayage complet pour obtenir des résultats exacts. -
indexed_only- l'utilisation de cette option peut désactiver la recherche dans les segments qui n'ont pas encore construit un index de vecteur. Cela peut être utile pour minimiser l'impact sur les performances de recherche lors des mises à jour. L'utilisation de cette option peut entraîner des résultats partiels si la collection n'est pas entièrement indexée, donc utilisez-la uniquement dans les cas où une cohérence éventuelle acceptable est requise.
Étant donné que le paramètre filter est spécifié, la recherche n'est effectuée que parmi les points qui répondent aux critères de filtrage. Pour des informations plus détaillées sur les filtres possibles et leurs fonctionnalités, veuillez vous référer à la section Filtres.
Un exemple de résultat pour cette API pourrait ressembler à ceci :
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Le result contient une liste de points découverts triés par score.
Veuillez noter que par défaut, ces résultats manquent de données de chargement et de vecteur. Référez-vous à la section Données de chargement et Vecteurs dans les résultats pour savoir comment inclure les données de chargement et les vecteurs dans les résultats.
Disponible à partir de la version v0.10.0
Si une collection est créée avec plusieurs vecteurs, le nom du vecteur à utiliser pour la recherche doit être fourni :
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
La recherche n'est effectuée qu'entre les vecteurs ayant le même nom.
Filtrer les résultats par score
En plus du filtrage de données, il peut également être utile de filtrer les résultats avec des scores de similarité faibles. Par exemple, si vous connaissez le score minimal acceptable pour un modèle et ne voulez aucun résultat de similarité en dessous du seuil, vous pouvez utiliser le paramètre score_threshold pour la requête de recherche. Il exclura tous les résultats avec des scores inférieurs à la valeur donnée.
Ce paramètre peut exclure à la fois les scores inférieurs et supérieurs, selon la métrique utilisée. Par exemple, les scores plus élevés dans la métrique euclidienne sont considérés comme plus éloignés et seront donc exclus.
Données de chargement et Vecteurs dans les résultats
Par défaut, la méthode de récupération ne renvoie aucune information stockée, telle que les données de chargement et les vecteurs. Les paramètres supplémentaires with_vectors et with_payload peuvent modifier ce comportement.
Exemple :
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
Le paramètre with_payload peut également être utilisé pour inclure ou exclure des champs spécifiques :
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["ville"]
}
}
API de recherche par lot
Disponible depuis la version v0.10.0
L'API de recherche par lot permet d'exécuter plusieurs requêtes de recherche via une seule requête.
Sa sémantique est simple, n requêtes de recherche par lot sont équivalentes à n requêtes de recherche distinctes.
Cette méthode présente plusieurs avantages. Logiquement, elle nécessite moins de connexions réseau, ce qui est bénéfique en soi.
Plus important encore, si les requêtes par lot ont le même filtre, la requête par lot sera traitée de manière efficace et optimisée grâce au planificateur de requêtes.
Cela a un impact significatif sur la latence pour des filtres non triviaux, car les résultats intermédiaires peuvent être partagés entre les requêtes.
Pour l'utiliser, il suffit de regrouper vos requêtes de recherche. Bien sûr, toutes les attributs régulières des requêtes de recherche sont disponibles.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Les résultats de cette API contiennent un tableau pour chaque requête de recherche.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
API recommandée
Le vecteur négatif est une fonctionnalité expérimentale et n'est pas garantie de fonctionner avec tous les types d'encastrement. En plus des recherches régulières, Qdrant vous permet également de rechercher en fonction de plusieurs vecteurs déjà stockés dans une collection. Cette API est utilisée pour la recherche vectorielle d'objets encodés sans impliquer les encodeurs de réseau neuronal.
L'API recommandée vous permet de spécifier plusieurs identifiants de vecteurs positifs et négatifs, et le service les fusionnera en un vecteur moyen spécifique.
vecteur_moyen = moy(positifs) + ( moy(positifs) - moy(négatifs) )
Si un seul identifiant positif est fourni, cette requête est équivalente à une recherche régulière du vecteur à ce point.
Les composants du vecteur avec des valeurs plus importantes dans le vecteur négatif sont pénalisés, tandis que les composants du vecteur avec des valeurs plus importantes dans le vecteur positif sont amplifiés. Ce vecteur moyen est ensuite utilisé pour trouver les vecteurs les plus similaires dans la collection.
La définition du schéma API pour REST API peut être trouvée ici.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
Le résultat d'exemple pour cette API sera comme suit :
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Disponible à partir de la version v0.10.0
Si la collection est créée à l'aide de plusieurs vecteurs, les noms des vecteurs utilisés doivent être spécifiés dans la demande de recommandation :
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
Le paramètre using spécifie le vecteur stocké à utiliser pour la recommandation.
API de recommandation par lot
Disponible à partir de la version v0.10.0
Similaire à l'API de recherche par lot, avec une utilisation et des avantages similaires, elle peut traiter les demandes de recommandation en lot.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
Le résultat de cette API contient un tableau pour chaque demande de recommandation.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Pagination
Disponible à partir de la version v0.8.3
L'API de recherche et de recommandation permet de sauter les premiers résultats de la recherche et de ne renvoyer que les résultats à partir d'un décalage spécifique.
Exemple :
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Cela équivaut à récupérer la 11ème page, avec 10 enregistrements par page.
Un décalage important peut entraîner des problèmes de performance, et la méthode de récupération basée sur vecteurs ne prend généralement pas en charge la pagination. Sans récupérer les premiers vecteurs, il n'est pas possible de récupérer le vecteur le plus proche numéro N.
Cependant, l'utilisation du paramètre de décalage peut économiser des ressources en réduisant le trafic réseau et l'accès au stockage.
Lors de l'utilisation du paramètre offset, il est nécessaire de récupérer internement offset + limit points, mais d'accéder uniquement à la charge utile et aux vecteurs de ces points qui sont effectivement renvoyés depuis le stockage.
API de regroupement
Disponible à partir de la version v1.2.0
Les résultats peuvent être regroupés en fonction d'un champ spécifique. Cela sera très utile lorsque vous avez plusieurs points pour le même élément et que vous souhaitez éviter des entrées redondantes dans les résultats.
Par exemple, si vous avez un grand document divisé en plusieurs morceaux et que vous souhaitez effectuer une recherche ou des recommandations basées sur chaque document, vous pouvez regrouper les résultats par identifiant de document.
Supposons qu'il y ait des points avec des charges utiles :
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
En utilisant l'API groups, vous pourrez récupérer les N meilleurs points pour chaque document, en supposant que la charge utile du point contienne l'identifiant du document. Bien sûr, il peut y avoir des cas où les meilleurs N points ne peuvent pas être satisfaits en raison d'un manque de points ou d'une distance relativement grande par rapport à la requête. Dans chaque cas, group_size est un paramètre d'effort maximal, similaire au paramètre limit.
Recherche de groupe
API REST (Schéma) :
POST /collections/{collection_name}/points/search/groups
{
// Identique à l'API de recherche classique
"vector": [1.1],
...,
// Paramètres de regroupement
"group_by": "document_id", // Chemin du champ à regrouper
"limit": 4, // Nombre maximal de groupes
"group_size": 2, // Nombre maximal de points par groupe
}
Recommandation de groupe
API REST (Schéma):
POST /collections/{collection_name}/points/recommend/groups
{
// Identique à l'API de recommandation classique
"negative": [1],
"positive": [2, 5],
...,
// Paramètres de regroupement
"group_by": "document_id", // Chemin du champ par lequel regrouper
"limit": 4, // Nombre maximum de groupes
"group_size": 2, // Nombre maximum de points par groupe
}
Que ce soit une recherche ou une recommandation, les résultats de sortie sont les suivants :
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
Les groupes sont triés par le score le plus élevé des points à l'intérieur de chaque groupe. À l'intérieur de chaque groupe, les points sont également triés.
Si le champ group_by d'un point est un tableau (par exemple, "document_id": ["a", "b"]), le point peut être inclus dans plusieurs groupes (par exemple, "document_id": "a" et document_id: "b").
Cette fonctionnalité dépend fortement de la clé group_by fournie. Pour améliorer les performances, assurez-vous de créer un index dédié. Restrictions:
- Le paramètre
group_byne prend en charge que les valeurs payload de type mot-clé et entier. Les autres types de valeurs payload seront ignorés. - Actuellement, la pagination n'est pas prise en charge lors de l'utilisation des groupes, donc le paramètre
offsetn'est pas autorisé.
Recherche au sein des groupes
Disponible depuis la version v1.3.0
Dans les cas où il y a plusieurs points pour différentes parties du même élément, la redondance est souvent introduite dans les données stockées. Si les informations partagées entre les points sont minimes, cela peut être acceptable. Cependant, cela peut devenir problématique avec des charges plus importantes, car cela calculera l'espace de stockage requis pour les points en fonction du nombre de points dans le groupe.
Une optimisation pour le stockage lors de l'utilisation de groupes est de stocker les informations partagées entre les points en fonction du même ID de groupe dans un seul point d'une autre collection. Ensuite, lors de l'utilisation de l'API groups, ajoutez le paramètre with_lookup pour ajouter ces informations pour chaque groupe.
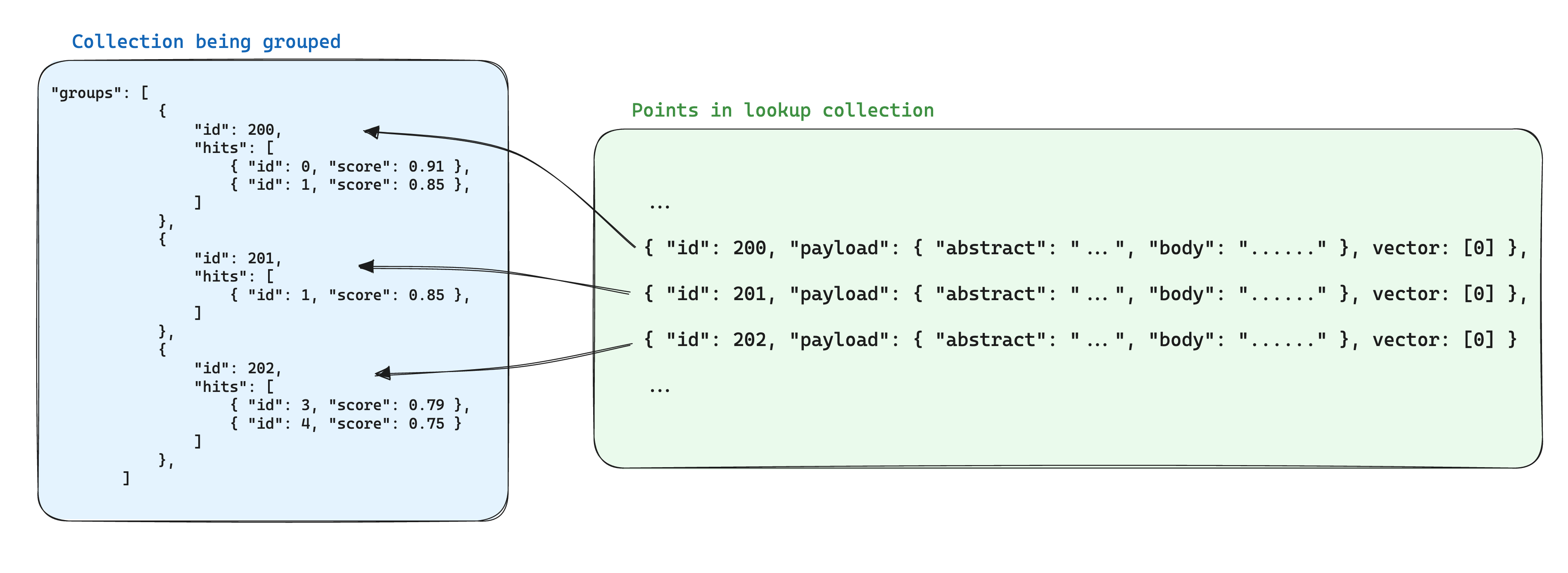
Un avantage supplémentaire de cette approche est que lorsque les informations partagées au sein des points de groupe changent, seul le point unique doit être mis à jour.
Par exemple, si vous avez une collection de documents, vous voudrez peut-être les découper et stocker les points appartenant à ces morceaux dans une collection séparée, en veillant à ce que les IDs des points appartenant aux documents soient stockés dans la charge utile du point de morceau.
Dans ce scénario, pour apporter les informations des documents dans les morceaux regroupés par ID de document, le paramètre with_lookup peut être utilisé:
POST /collections/chunks/points/search/groups
{
// Mêmes paramètres que dans l'API de recherche régulière
"vector": [1.1],
...,
// Paramètres de regroupement
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Paramètres de recherche
"with_lookup": {
// Nom de collection des points à rechercher
"collection": "documents",
// Options spécifiant le contenu à apporter depuis la charge utile des points de recherche, par défaut à true
"with_payload": ["titre", "texte"],
// Options spécifiant le contenu à apporter depuis les vecteurs des points de recherche, par défaut à true
"with_vectors": false
}
}
Pour le paramètre with_lookup, un raccourci with_lookup="documents" peut également être utilisé pour apporter l'intégralité de la charge utile et des vecteurs sans spécification explicite.
Les résultats de la recherche seront affichés dans le champ lookup sous chaque groupe.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"titre": "Document A",
"texte": "Il s'agit du document A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"titre": "Document B",
"texte": "Il s'agit du document B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Étant donné que la recherche est effectuée en faisant correspondre directement les IDs des points, tout ID de groupe qui n'est pas un ID de point existant (et valide) sera ignoré, et le champ lookup sera vide.