Benzerlik Arama
Makine öğreniminin birçok uygulamasında, en yakın vektörleri aramak temel bir unsurdur. Modern sinir ağları, nesneleri vektörlere dönüştürmek için eğitilir, bu da vektör uzayında birbirine yakın olan nesnelerin gerçek dünyada da birbirine yakın olmasını sağlar. Örneğin, benzer anlamlı metinler, görsel olarak benzer görüntüler veya aynı türe ait şarkılar.
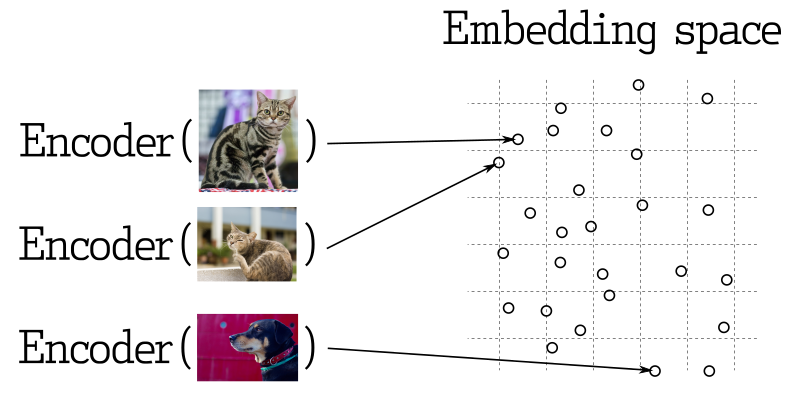
Benzerlik Ölçümü
Vektörler arasındaki benzerliği değerlendirmek için birçok yöntem vardır. Qdrant'ta bu yöntemlere benzerlik ölçümleri denir. Ölçümün seçimi, vektörlerin nasıl elde edildiğine, özellikle de sinir ağı kodlayıcısını eğitmek için kullanılan yönteme bağlıdır.
Qdrant, aşağıdaki en yaygın ölçüm türlerini destekler:
- Nokta çarpımı:
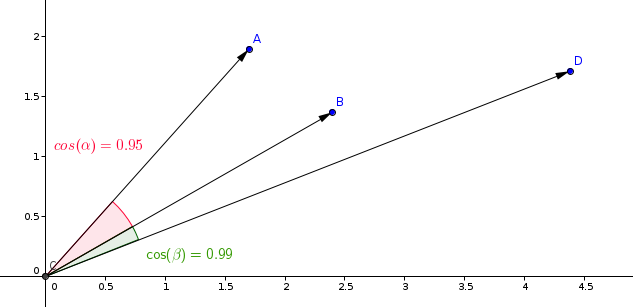
Nokta - Kosinüs benzerliği:
Kosinüs - Öklid uzaklığı:
Öklid
Benzerlik öğrenme modellerinde en yaygın kullanılan ölçüm kosinüs ölçümüdür.
Qdrant, bu ölçümü iki adımda hesaplar, böylece daha yüksek arama hızları elde eder. İlk adım, vektörleri koleksiyona eklerken vektörleri normalize etmektir. Bu sadece her bir vektör için bir kez yapılır.
İkinci adım, vektör karşılaştırmasıdır. Bu durumda, SIMD'in hızlı işlemleri nedeniyle nokta çarpımı işlemine eşdeğerdir.
Sorgu Planı
Aramada kullanılan filtreleme koşullarına bağlı olarak sorgu yürütme için birkaç olası senaryo bulunmaktadır. Qdrant, mevcut dizinlere, koşulların karmaşıklığına ve filtrelenmiş sonuçların kardinalitesine göre bir sorgu yürütme seçeneği seçer. Bu sürece sorgu planlama denir.
Strateji seçimi süreci sezgisel algoritmalar tarafından desteklenir ve sürüme göre değişebilir. Bununla birlikte, genel prensipler şunlardır:
- Her bir segment için sorgu planlarını bağımsız olarak yürütün (segmentler hakkında detaylı bilgi için depolamaya bakınız).
- Nokta sayısı düşükse tam taramaları önceliklendirin.
- Bir strateji seçmeden önce filtrelenmiş sonuçların kardinalitesini tahmin edin.
- Cardinality düşükse noktaları kurtarmak için payload dizinlerini kullanın (dizinlere bakınız).
- Cardinality yüksekse filtre edilebilir vektör dizinlerini kullanın.
Eşik değerleri, her koleksiyon için yapılandırma dosyası aracılığıyla bağımsız olarak ayarlanabilir.
Arama API
Hadi bir arama sorgusunun örneğine göz atalım.
REST API - API şema tanımlamalarına buradan ulaşılabilir.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
Bu örnekte, vektör [0.2, 0.1, 0.9, 0.7]'ye benzer vektörler arıyoruz. limit parametresi (veya takma adı olan top) aracılığıyla almak istediğimiz en benzer sonuç sayısını belirtir.
params anahtarının altındaki değerler özel arama parametrelerini belirtir. Şu anda kullanılabilir olan parametreler şunlardır:
-
hnsw_ef- HNSW algoritması içinefparametresinin değerini belirtir. -
exact- kesin (ANN) arama seçeneğini kullanılıp kullanılmayacağı. True olarak ayarlandığında, tam sonuçları elde etmek için tam tarama yapılacağından uzun bir süre alabilir. -
indexed_only- bu seçenek, henüz bir vektör indeksi oluşturulmamış segmentlerde aramayı devre dışı bırakabilir. Bu, güncellemeler sırasında arama performansına etkiyi en aza indirmek için faydalı olabilir. Bu seçeneği kullanmak, koleksiyon tam olarak dizine eklenmemişse kısmi sonuçlara neden olabilir, bu nedenle kabul edilebilir son durum tutarlılığı gereken durumlarda yalnızca kullanın.
Filtre parametresi belirtildiği için, arama sadece filtreleme kriterlerini karşılayan noktalar arasında gerçekleştirilir. Olası filtreler ve işlevsellikleri hakkında daha detaylı bilgi için Filtreler bölümüne bakınız.
Bu API için örnek bir sonuç şöyle olabilir:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result, score'a göre sıralanmış keşfedilmiş noktaların bir listesini içerir.
Bu sonuçlar varsayılan olarak yük ve vektör verisi eksiktir. Sonuçlarda yük ve vektörleri nasıl dahil edileceği ile ilgili bilgi için Sonuçlarda Yük ve Vektör bölümüne bakın.
Sürüm v0.10.0'dan itibaren kullanılabilir
Birden fazla vektörle koleksiyon oluşturulduysa, arama için kullanılacak vektörün adı belirtilmelidir:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "resim",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
Sadece aynı adı taşıyan vektörler arasında arama yapılır.
Skor'a Göre Sonuçları Filtreleme
Yük filtrelemesinin yanı sıra, düşük benzerlik skorlarına sahip sonuçları filtrelemek de faydalı olabilir. Örneğin, bir model için minimum kabul edilebilir bir skor biliyorsanız ve eşik altında herhangi bir benzerlik sonucu istemiyorsanız, arama sorgusu için score_threshold parametresini kullanabilirsiniz. Bu, verilen değerin altında olan tüm sonuçları dışlar.
Bu parametre, kullanılan metriğe bağlı olarak hem düşük hem de yüksek skorları dışlayabilir. Örneğin, Öklid metriğinde daha yüksek skorlar daha uzak kabul edildiğinden ve bu nedenle dışlanacaklardır.
Sonuçlarda Yük ve Vektörler
Varsayılan olarak, alma yöntemi depolanan bilgi, yük ve vektör döndürmez. Ek parametreler with_vectors ve with_payload bu davranışı değiştirebilir.
Örnek:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
with_payload parametresi ayrıca belirli alanları dahil etmek veya dışarıda bırakmak için de kullanılabilir:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["şehir"]
}
}
Toplu Arama API
0.10.0 sürümünden itibaren kullanılabilir
Toplu arama API, tek bir istem üzerinden birden çok arama isteğini yürütmenize olanak tanır.
Semantiği basittir, n toplu arama isteği, n ayrı arama isteğiyle eşdeğerdir.
Bu yöntemin birkaç avantajı vardır. Mantıksal olarak, daha az ağ bağlantısı gerektirir, bu da kendi başına faydalıdır.
Daha da önemlisi, toplu istekler aynı filtre ye sahipse, toplu istek sorgu planlayıcı aracılığıyla verimli bir şekilde ele alınır ve optimize edilir.
Bu, ara sonuçların istekler arasında paylaşılabilmesi nedeniyle karmaşık olmayan filtreler için gecikmenin önemli ölçüde etkisi olur.
Kullanmak için sadece arama isteklerinizi bir araya paketleyin. Elbette, tüm düzenli arama isteği öznitelikleri kullanılabilir.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"anahtar": "şehir",
"eşleşme": {
"değer": "Londra"
}
}
]
},
"vektör": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"anahtar": "şehir",
"eşleşme": {
"değer": "Londra"
}
}
]
},
"vektör": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Bu API'nin sonuçları, her bir arama isteği için bir dizi içerir.
{
"sonuç": [
[
{ "id": 10, "skor": 0.81 },
{ "id": 14, "skor": 0.75 },
{ "id": 11, "skor": 0.73 }
],
[
{ "id": 1, "skor": 0.92 },
{ "id": 3, "skor": 0.89 },
{ "id": 9, "skor": 0.75 }
]
],
"durum": "tamam",
"zaman": 0.001
}
Tavsiye Edilen API
Negatif vektör deneysel bir özelliktir ve tüm gömme türleriyle çalışması garanti edilmez. Düzenli aramaların yanı sıra, Qdrant ayrıca koleksiyonda zaten depolanan birden fazla vektöre dayalı arama yapmanıza da izin verir. Bu API, sinir ağı kodlayıcılarını dahil etmeksizin kodlanmış nesnelerin vektör araması için kullanılır.
Tavsiye Edilen API, birden fazla pozitif ve negatif vektör kimliğini belirtmenize olanak tanır ve hizmet bunları belirli bir ortalama vektöre birleştirir.
ortalama_vektör = ortalama(pozitif_vektörler) + ( ortalama(pozitif_vektörler) - ortalama(negatif_vektörler) )
Yalnızca bir pozitif kimlik sağlandığında, bu istek o noktadaki vektör için düzenli bir arama ile eşdeğerdir.
Negatif vektördeki daha büyük değerlere sahip vektör bileşenleri cezalandırılırken, pozitif vektördeki daha büyük değerlere sahip vektör bileşenleri amplifiye edilir. Bu ortalama vektör daha sonra koleksiyondaki en benzer vektörleri bulmak için kullanılır.
REST API için API şema tanımı burada bulunabilir.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"anahtar": "şehir",
"eşleşme": {
"değer": "Londra"
}
}
]
},
"negatif": [718],
"pozitif": [100, 231],
"limit": 10
}
Bu API için örnek sonuç şu şekilde olacaktır:
{
"sonuç": [
{ "id": 10, "skor": 0.81 },
{ "id": 14, "skor": 0.75 },
{ "id": 11, "skor": 0.73 }
],
"durum": "tamam",
"zaman": 0.001
}
0.10.0'dan itibaren kullanılabilir
Koleksiyon birden fazla vektör kullanılarak oluşturulmuşsa, tavsiye isteğinde kullanılan vektörlerin adları belirtilmelidir:
POST /collections/{collection_name}/points/recommend
{
"pozitif": [100, 231],
"negatif": [718],
"kullanarak": "resim",
"limit": 10
}
kullanarak parametresi, öneri için kullanılacak depolanan vektörü belirtir.
Toplu Tavsiye API
V0.10.0 ve sonrasında mevcuttur
Toplu arama API'sine benzer şekilde, benzer kullanıma ve faydalara sahip olarak, toplu olarak tavsiye isteklerini işleyebilir.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londra"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
Bu API'nin sonucu, her bir tavsiye isteği için bir dizi içerir.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Sayfalama
V0.8.3 ve sonrasında mevcuttur
Arama ve tavsiye API'si, aramanın ilk birkaç sonucunu atlamaya ve belirli bir ofsetten başlayarak sadece sonuçları döndürmeye olanak tanır.
Örnek:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Bu, 10 kayıt içeren 11. sayfayı almakla eşdeğerdir.
Büyük ofset değerine sahip olmak, performans sorunlarına yol açabilir ve vektör tabanlı alım yöntemi genellikle sayfalamaı desteklemez. İlk N vektörlerini almadan, N'inci en yakın vektörü almak mümkün olmaz.
Ancak, ofset parametresi kullanılarak, ağ trafiğini ve depolama erişimini azaltarak kaynakları korumak mümkündür.
offset parametresi kullanılırken, içsel olarak offset + limit noktaları almak gerekli olmasına rağmen, yalnızca gerçekten depodan döndürülen noktaların yükünü ve vektörlerini erişmek gereklidir.
Gruplama API
Versiyon v1.2.0'dan itibaren kullanılabilir
Sonuçlar belirli bir alan temelinde gruplandırılabilir. Bu, aynı öğe için birden fazla noktanız varsa ve sonuçlardaki tekrarlayan girişlerden kaçınmak istiyorsanız çok faydalı olacaktır.
Örneğin, büyük bir belgeniz varsa ve her belgeye göre arama yapmak veya öneride bulunmak istiyorsanız, sonuçları belge kimliğine göre gruplayabilirsiniz.
Örneğin, yükleri olan noktalar varsa:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
groups API kullanılarak, her belge için en iyi N noktayı alabileceksiniz, varsayılan olarak noktanın yükü belge kimliğini içeriyorsa. Elbette, noktaların kıtlığı veya sorgudan göreli uzaklık nedeniyle en iyi N noktalarının karşılanamayabileceği durumlar olabilir. Her durumda, group_size belirli bir çaba parametresidir ve limit parametresine benzerdir.
Grup Araması
REST API (Şema):
POST /collections/{collection_name}/points/search/groups
{
// Normal arama API'siyle aynı
"vector": [1.1],
...,
// Gruplama parametreleri
"group_by": "document_id", // Gruplama yapılacak alan yolu
"limit": 4, // En fazla grup sayısı
"group_size": 2, // Grup başına maksimum nokta sayısı
}
Grup Tavsiyesi
REST API (Schema):
POST /collections/{collection_name}/points/recommend/groups
{
// Düzenli tavsiye API'siyle aynı
"negative": [1],
"positive": [2, 5],
...,
// Gruplama parametreleri
"group_by": "document_id", // Gruplama yapılacak alanın yolu
"limit": 4, // Grupların maksimum sayısı
"group_size": 2, // Her grupdaki maksimum nokta sayısı
}
Arama yapılıyor ya da tavsiye alınıyor olmasına bakılmaksızın, çıkış sonuçları aşağıdaki gibidir:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
Gruplar, her bir grup içindeki noktaların en yüksek puanına göre sıralanır. Her bir grup içinde, noktalar da ayrıca sıralanır.
Bir noktanın group_by alanı bir dizi ise (ör. "document_id": ["a", "b"]), nokta birden fazla gruba dahil edilebilir (ör. "document_id": "a" ve document_id: "b").
Bu işlev, sağlanan group_by anahtarına ağır bir şekilde bağımlıdır. Performansı artırmak için buna özel bir indeks oluşturulduğundan emin olun. Kısıtlamalar:
-
group_byparametresi yalnızca anahtar kelime ve tamsayı yük değerlerini destekler. Diğer yük değeri tipleri yok sayılacaktır. - Şu anda gruplar kullanıldığında sayfalama desteklenmediğinden,
offsetparametresine izin verilmez.
Gruplar İçinde Arama
v1.3.0'dan itibaren kullanılabilir
Aynı öğenin farklı noktaları için farklı yerlerde, depolanan verilerde genellikle tekrarlanma oluşur. Noktalar arasındaki paylaşılan bilgi minimalse, bu kabul edilebilir olabilir. Ancak, yük daha fazla olduğunda sorun oluşturabilir, çünkü grup içindeki noktaların depolama alanı gereksinimi noktaların sayısına dayalı olarak hesaplanacaktır.
Gruplar kullanılırken depolama için bir optimizasyon, aynı grup kimliği üzerindeki noktalar arasındaki paylaşılan bilgiyi başka bir koleksiyondaki tek bir noktada depolamaktır. Ardından, groups API'sını kullanırken her grup için bu bilgiyi eklemek için with_lookup parametresini ekleyebilirsiniz.
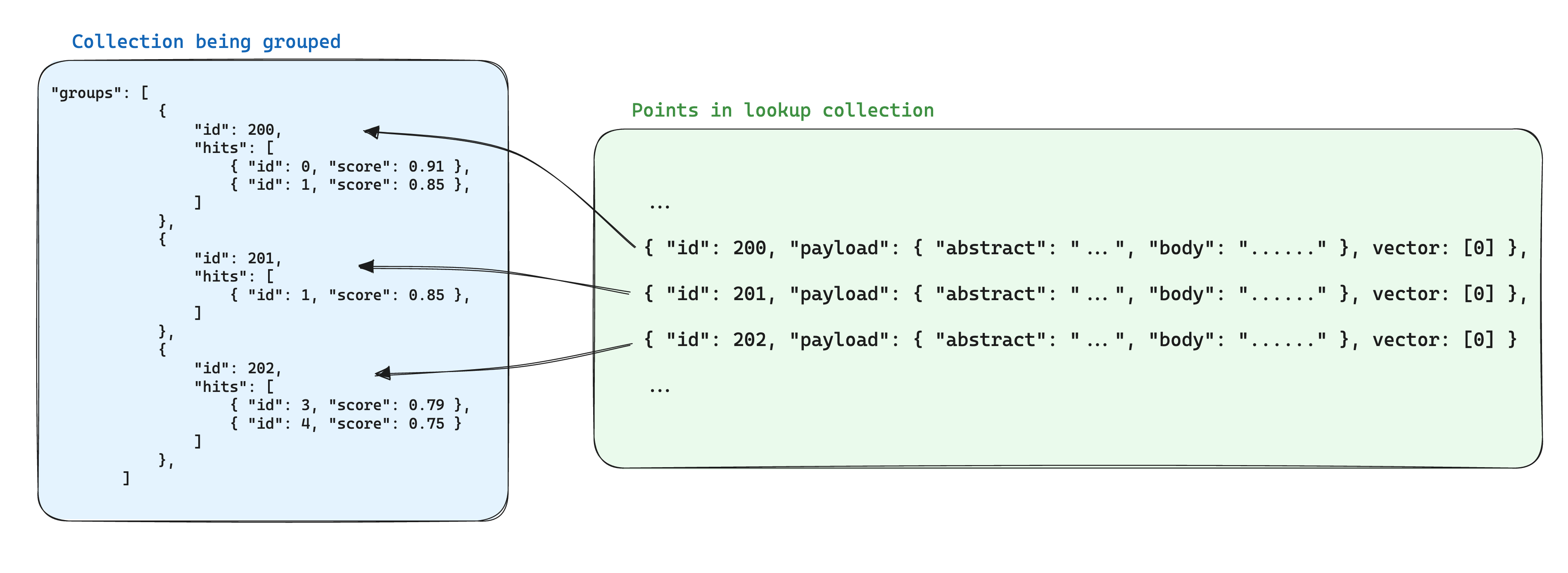
Bu yaklaşımın ek bir faydası, grup noktaları içindeki paylaşılan bilginin değişmesi durumunda sadece tek bir noktanın güncellenmesinin gerekliliğidir.
Örneğin, bir belge koleksiyonunuz varsa, bunları bölmek ve bu parçalara ait noktaları ayrı bir koleksiyonda depolamak isteyebilir, böylece belgelere ait nokta kimlikleri parça noktasının taşıyıcısında depolanır.
Bu senaryoda, belgelerden parçalara getirilen bilgiler için with_lookup parametresi kullanılabilir:
POST /collections/chunks/points/search/groups
{
// Normal arama API'sindeki gibi aynı parametreler
"vector": [1.1],
...,
// Gruplama parametreleri
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Arama parametreleri
"with_lookup": {
// Aranacak noktaların koleksiyon adı
"collection": "documents",
// Arama noktalarının taşıyıcısından getirilecek içeriği belirleyen seçenekler, varsayılan olarak true
"with_payload": ["title", "text"],
// Arama noktalarının vektörlerinden getirilecek içeriği belirleyen seçenekler, varsayılan olarak true
"with_vectors": false
}
}
with_lookup parametresi için, tüm taşıyıcıyı ve vektörleri açıkça belirtmeden getirmek için kısa bir yol olarak with_lookup="documents" de kullanılabilir.
Arama sonuçları, her grup altında lookup alanında görüntülenecektir.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Belge A",
"text": "Bu belge A'dır"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Belge B",
"text": "Bu belge B'dır"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Nokta kimlikleri doğrudan eşleştirilerek arama yapıldığı için var olmayan ve geçerli olmayan grup kimlikleri yok sayılır ve lookup alanı boş olacaktır.