مشابہت تلاش
مشین لرننگ کے بہت سارے اطلاقات میں، قریبی برد دہندوں کی تلاش اہم عنصر ہے۔ جدید نفال نیٹ ورکس کو اشیاء کو برد دہندوں میں تبدیل کرنے کے لئے تربیت دی جاتی ہے، جس کی وجہ سے برد دہندہ فضائی میں قریب وقوع کرنے والے اشیاء واقعی دنیا میں بھی قریب وقوع کرتے ہیں۔ مثلاً، معنوی معنا، وجہنی مشابہ تصاویر یا ایک ہی جنر میں شامل گانے۔
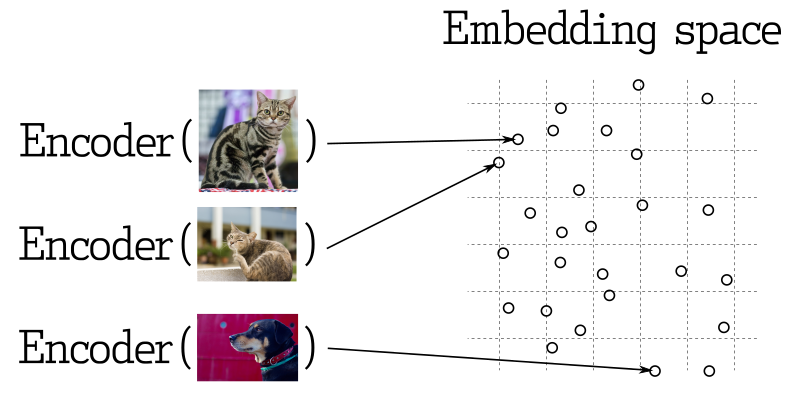
مشابہت کی پیمائش
برد دہندوں کے درمیان مشابہت کا تخمینہ لگانے کے لئے بہت سارے طریقے ہیں۔ Qdrant میں، یہ طریقے مشابہت کی پیمائش کہلاتے ہیں۔ پیمائش کا انتخاب برد دہندوں کے حاصل کرنے کے طریقے پر منحصر ہوتا ہے، خاص طور پر نیورل نیٹ ورک انکوڈر کی تربیت میں استعمال ہونے والے طریقے پر۔
Qdrant مندرجہ ذیل عام طریقے کی پیمائش کی حمایت کرتا ہے:
- ڈاٹ ضرب:
Dot - کوسائن مشابہت:
Cosine - یوروکلیدین فاصلہ:
Euclid
برد دہندہ سیکھنے والے ماڈلس میں سب سے زیادہ استعمال ہونے والی پیمائش کوسائن پیمائش ہے۔
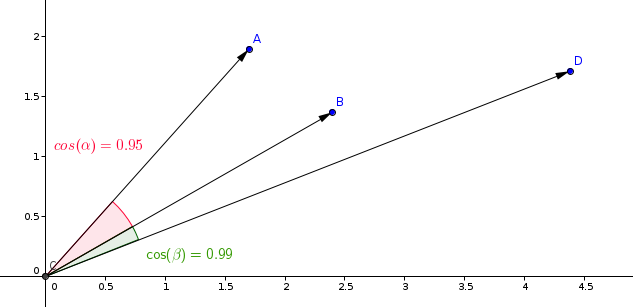
Qdrant اس پیمائش کو دو مراحل میں حاصل کرتا ہے، جس سے زیادہ تلاش کی رفتار حاصل ہوتی ہے۔ پہلے مرحلے میں برد دہندے کو نارملائز کرنا ہوتا ہے جب انہیں کلیکشن میں شامل کیا جاتا ہے۔ یہ صرف ہر برد دہندے کے لئے ایک بار کیا جاتا ہے۔
دوسرے مرحلے میں برد دہندوں کے موازنہ ہوتا ہے۔ اس صورت میں، اس کا مترادف ڈاٹ ضرب کارروائی کے برابر ہوتا ہے، جس کی وجہ سے SIMD کے تیز کارروائیوں کی وجہ سے ہوتا ہے۔
سوال منصوبہ
تلاش میں استعمال ہونے والے فلٹرز کے مطابق، سوال کی اجراء پر کئی ممکنہ مناظر ہیں۔ Qdrant میں، سوال کا منصوبہ مندرجہ ذیل انتخاب کرتا ہے بنیادی انڈیکسوں، شرائط کی پیچیدگی اور فلٹر کردہ نتائج کی طول کی بنیاد پر۔ یہ عمل منصوبہ بندی کہلاتا ہے۔
استراتیجی کا انتخاب عموماً ہیورسٹک الگورتھم پر منحصر ہوتا ہے اور ورژن کے مطابق تبدیل ہو سکتا ہے۔ تاہم، عام اصول یہ ہیں:
- ہر سگمنٹ کے لئے سوال کے منصوبہ کو الگ الگ اجراء کریں (سیگمنٹ کے متعلق تفصیلات کے لئے براہ کرم محفوظ میں دی گئی ہوئی ویب سائٹ کا اشارہ کریں)۔
- اگر نقطوں کی تعداد کم ہے تو فل پھرااں کو ترجیح دیں۔
- استراتیجی کے انتخاب سے پہلے فلٹر کردہ نتائج کی کارڈینیلٹی کا تخمینہ لگائیں۔
- اگر کارڈینیلٹی کم ہو تو پہنچانے والے نقاط کو پیمانے کا استعمال کریں (انڈیکسی کے حوالے سے معلومات کے لئے دی گئی ویب سائٹ کا اشارہ کریں)۔
- اگر کارڈینیلٹی زیادہ ہو تو فلٹر کردہ برد دہندہ انڈیکسز کا استعمال کریں۔
ہر کلیکشن کے لئے حدوں کو ترتیب فائل کے ذریعے الگ الگ ترتیب دی جا سکتی ہے۔
تلاش API
دیکھیں ایک تلاش کوئیری کے مثال کو۔
REST API - ایپی سکیما کی تشریح یہاں ملاحظہ کی جا سکتی ہے۔
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
اس مثال میں ہم ویکٹر [0.2, 0.1, 0.9, 0.7] کے مماثل ویکٹروں کی تلاش کر رہے ہیں۔ پیرامیٹر limit (یا اس کا مترادف top) وضاحت کرتا ہے کہ ہمیں حاصل کرنا چاہتے ہیں۔
params کی زیر کلید قیمتیں ان کسام کی تلاش پیرامیٹرز کو وضاحت کرتی ہیں۔ یہاں دستیاب پیرامیٹرز درج ذیل ہیں:
-
hnsw_ef- HNSW الگورتھم کےefپیرامیٹر کی قیمت کا تعین کرتا ہے۔ -
exact- کیا دقیق (ANN) تلاش اختیار کرنا چاہیے یا نہیں۔ اگر یہ سیٹ ٹرُو ہوتا ہے، تو تلاش زیادہ وقت لے سکتی ہے کیونکہ یہ دقیق نتائج حاصل کرنے کیلئے مکمل اسکین کرتا ہے۔ -
indexed_only- اس اختیار کا استعمال کرتے ہوئے ویکٹر انڈیکس نہیں بنائے گئے سیگمنٹس میں تلاش کو غیر فعال کرنا ممکن ہے۔ اس کا استعمال اپ ڈیٹس کے دوران تلاش کی کارکردگی پر اثرات کو کم کرنے کے لئے مفید ہو سکتا ہے۔ اس اختیار کا استعمال کرنے سے اگر کلیکشن مکمل طور پر انڈیکس نہیں ہوا ہو تو یہ قسم کی نتائج غیر کامل ہو سکتی ہیں، اس لئے اسے صرف ان معاملات میں استعمال کریں جہاں قبول پذیر اختیارات کی لازمی تاخیر درکار ہو۔
اگر فلٹر پیرامیٹر کا تعین کیا گیا ہے تو، تلاش صرف وہ نقطے کا مقابلہ کرتی ہے جو فلٹر کی کریٹیریا کو مطمئن کرتے ہیں۔ ممکنہ فلٹرز اور ان کی کارکردگیوں کے بارے میں مزید تفصیلات کے لئے فلٹرز سیکشن پر ملاحظہ کیجئے۔
اس API کے لئے ایک نمونہ نتیجہ درج ذیل ہو سکتا ہے:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result میں score کے مطابق ترتیب دیے گئے دریافت شدہ نقطوں کی فہرست شامل ہے۔
براہ کرم نوٹ کریں کہ ڈیفالٹ طور پر، یہ نتائج نہ تو کوئیری کے اور نہ ہی ویکٹر کے ڈیٹا ساتھ میں واپس کرتے ہیں۔ نتائج میں پیمانہ اور ویکٹر ڈیٹا شامل کرنے کے لئے Payload and Vector in Results سیکشن کا ملاحظہ کریں۔
اصدار v0.10.0 سے دستیاب ہے
اگر ایک کلیکشن میں مختلف ویکٹروں کے ساتھ تشکیل دی گئی ہے تو تلاش کے لیے استعمال ہونے والے ویکٹر کا نام فراہم کرنا چاہئے:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
تلاش صرف اُن ویکٹروں کے درمیان کی جاتی ہے جن کا نام ایک جیسا ہو۔
نتائج کو امتیاز کی بنیاد پر فلٹر کرنا
پیمانہ فلٹرنگ کے علاوہ، نتائج کو کم امتیاز کیا گیا نتائج سے الگ کرنا بھی مفید ہو سکتا ہے۔ مثلاً، اگر آپ کو ماڈل کے لئے کم سے کم قبولیت امتیاز معلوم ہوتا ہے اور آپ چاہتے ہیں کہ کسی بھی حد سے کم متشابہتہ نتائج شامل نہ ہوں، تو آپ تلاش کوئیری کے لئے score_threshold پیرامیٹر کا استعمال کر سکتے ہیں۔ یہ سب نتائج کو وضاحت کرے گا جن کے امتیازات دی گئی قیمت سے کم ہوں گے۔
یہ پیرامیٹر میٹرک کے استعمال پر منحصر ہو سکتا ہے اور کم اور زیادہ امتیازات دونوں کو خارج کر سکتا ہے۔ مثال کے طور پر، یوروکلیڈین میٹرک میں زیادہ امتیازات کو دور قرار دیا جاتا ہے اور ان کو خارج کرا جاتا ہے۔
نتائج میں پیمانہ اور ویکٹر
پیش فرض طور پر، حاصل کرنے کا طریقہ کسی بھی ذخیرہ شدہ معلومات، مثلاً پیمانہ اور ویکٹر، واپس نہیں کرتا ہے۔ اضافی پیرامیٹرز with_vectors اور with_payload اس عمل کو ترتیب دیتے ہیں۔
مثال:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
پیرامیٹر with_payload کو ایک خاص فیلڈ شامل یا خارج کرنے کے لئے بھی استعمال کیا جا سکتا ہے:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
بیچ سرچ API
v0.10.0 سے دستیاب ہے
بیچ سرچ API سے ایک ہی درخواست کے ذریعے متعدد تلاش کی درخواستیں نافذ کرنے کی اجازت ہے۔
اس کا معنوں سیدھے ہیں، n بیچ سرچ درخواستیں n علیحدہ تلاش درخواستوں کے مترادف ہیں۔
اس طریقے کے کئی فوائد ہیں۔ منطقی طور پر، یہ کم نیٹ ورک کنکشن کی ضرورت ہوتی ہے، جو خود میں فائدہ مند ہے۔
اس سے زیادہ اہم بات، اگر بیچ درخواستوں کے پاس کے ہمیں فلٹر ہوتا ہے، تو بیچ درخواست کو کوئی کام کرنے والا ریاستی نظامدار کریگا۔
یہ غیر طبیعی فلٹرز کے لیے لیٹنسی پر اہم اثر انداز ہوتا ہے، کیونکہ درمیانی نتائج ڈھیر بیچ درخواستوں کے درمیان تقسیم کیے جا سکتے ہیں۔
اس کا استعمال کرنے کے لیے، بس اپنی تلاش کی درخواستوں کو اکٹھا پیک کریں۔ البتہ، تمام عمومی تلاش درخواست خصوصیات دستیاب ہیں۔
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
اس API کے نتائج میں ہر تلاش کی درخواست کے لیے ایک ایرے شامل ہیں۔
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
سفارشی API
منفی سمتیہ ایک تجرباتی خصوصیت ہے اور یہ یقینی نہیں ہے کہ یہ تمام اقسام کے تنصیبوں کے ساتھ کام کرے گا۔ علاوہ ازیں عام تلاش کے علاوہ، کوئی بھی قدرتی نیٹ ورک انکوڈرز کو شامل کیے بغیر کڈرنٹ کو مخزن میں موجود متعدد سمتیوں پر بنیاد پر تلاش کرنے کی اجازت بھی دیتا ہے۔
سفارشی API آپ کو متعدد مثبت اور منفی سمتیہ آئی ڈیز کو محدود کرنے کی اجازت دیتا ہے، اور خدمت انہیں ایک مخصوص اوسط سمتیہ میں جمع کرے گی۔
اوسط_سمتیہ = متوسط(مثبت_سمتیہ) + (متوسط(مثبت_سمتیہ) - متوسط(منفی_سمتیہ))
اگر صرف ایک مثبت آئی ڈی فراہم کیا گیا ہے، تو یہ درخواست اس نقطے پر سمتیہ کی عام تلاش کے مترادف ہوتی ہے۔ منفی سمتیہ میں بڑے قیمت کے سمتیہ اجرت میں کمی آئے گی، جبکہ مثبت سمتیہ میں بڑے قیمت کے سمتیہ توانا ہوں گے۔ یہ اوسط سمتیہ پھر مخزن میں سب سے مشابہ سمتیوں کو تلاش کرنے کے لیے استعمال کیا جاتا ہے۔
REST API کے لیے API سکیما تعریف یہاں دستیاب ہے۔
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
اس API کے نتائج کا نمونہ مندرجہ ذیل ہوگا:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
v0.10.0 کے بعد دستیاب ہے
اگر مخزن میں متعدد سمتیوں کا استعمال کیا گیا ہوتا ہے، تو سفارشی درخواست میں استعمال ہونے والے سمتیوں کے نام ذکر کرنا چاہئے:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
use پیرامیٹر سٹورش سمتیہ کی مخصوص کرنے کے لیے ہے۔
بیچ تجویز شدہ API
v0.10.0 سے دستیاب ہے
بیچ تجویز کی API جیسے بیچ تلاش API کے ساتھ، اس کا استعمال اور فوائد ہیں، وہ بھی تجویز کے دستاویزات کو بیچ میں پروسس کرسکتی ہے۔
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
اس API کے نتائج میں ہر تجویز کی درخواست کے لئے ایک ایرے شامل ہے۔
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
صفحہ بندی
v0.8.3 سے دستیاب ہے
تلاش اور تجویز کی API امکان فراہم کرتی ہے کہ تلاش کے پہلے کچھ نتائج کو چھوڑ کر صرف ایک مخصوص آفسٹ سے شروع ہونے والے نتائج واپس بھیجیں۔
مثال:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
اس کا مترادف ہے کہ ہم 11 ویں صفحہ حاصل کر رہے ہیں، ہر صفحے 10 ریکارڈ ہوں گے۔
بڑے آفسٹ قیمت ہوسکتی ہے تو تناظری کارروائی مسائل کا سبب بن سکتی ہے، اور عام طور پر یہ وضاحت کی تھا کہ آفسٹ پیرامیٹر کا استعمال پورْی نیٹ ورک ٹریفک اور اسٹوریج تک رسائی کو تخفیف دینے کے ذریعے وسائل بچا سکتا ہے۔
جب آفسٹ پیرامیٹر کا استعمال کر رہے ہیں تو ضروری ہے کہ اندریشیمیٹلی آفسٹ + لمحہ پوائنٹس کو واپسی کریں، لیکن صرف وہ مسکان ویکٹراز اور پے لوڈ کو دستیابی دےں جو مخزن سے واپس مکمل ہوں۔
گروپنگ API
نسخہ v1.2.0 سے دستیاب ہے
نتائج کسی خاص فیلڈ کے مطابق گروپ کیے جا سکتے ہیں۔ جب آپ کے پاس ایک چیز کے لئے متعدد نقطے ہوں اور آپ نتائج میں تکراری داخلات سے بچنا چاہتے ہیں تو یہ بہت مفید ہوگا۔
مثال کے طور پر، اگر آپکے پاس ایک بڑے دستاویز ہوں جو مختلف حصوں میں تقسیم ہوتا ہے اور آپ ہر حصے کے بنیاد پر تلاش یا تجویز کرنا چاہتے ہیں، تو آپ دستاویز کی شناخت کے لحاظ سے نتائج کو گروپ کرسکتے ہیں۔
مان لیں کہ پوائنٹس پوئیڈ کے ساتھ پوائنٹس ہیں:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
گروپس API کا استعمال کرکے، آپ ہر دستاویز کے لئے اوپر کی N پوائنٹس حاصل کرسکتے ہیں، اگر پوائنٹ کا پیمانہ دستاویز شناخت شامل کرتا ہے۔ البتہ، کچھ صورتوں میں کمی یا پوائنٹس کی نسبت سے زیادہ فاصلہ کی وجہ سے بہترین N پوائنٹس کی مکمل کرنا مشکل ہوسکتا ہے۔ ہر صورت میں، group_size، limit پیرامیٹر کی طرح ایک بہترین کوششی پیرامیٹر ہے۔
گروپ تلاش
REST API (سکیما):
POST /collections/{collection_name}/points/search/groups
{
// عام تلاش API کی طرح
"vector": [1.1],
...,
// گروپنگ پیرامیٹر
"group_by": "document_id", // گروپ کرنے والے فیلڈ کا راستہ
"limit": 4, // گروپ کی زیادہ سے زیادہ تعداد
"group_size": 2, // ہر گروپ کی زیادہ سے زیادہ نقطوں کی تعداد
}
گروپ تجویز
REST API (ضابطہ):
POST /collections/{collection_name}/points/recommend/groups
{
// معمولی تجویز API کی طرح
"negative": [1],
"positive": [2, 5],
...,
// گروپ بنانے کے پیرامیٹر
"group_by": "document_id", // گروپ بنانے کے فیلڈ کا راستہ
"limit": 4, // زیادہ سے زیادہ گروپ کی تعداد
"group_size": 2, // گروپ کے ہر اندر کے زیادہ سے زیادہ نمبر
}
چاہے سرچ ہو یا تجویز، خروجی نتائج مندرجہ زیر ہوتی ہے:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
گروپ کو اندر کے نقطوں کی ہائی سکور کے مطابق سارٹ کیا جاتا ہے۔ ہر گروپ کے اندر، نقطے بھی سارٹ ہوتے ہیں۔
اگر کسی نقطے کا group_by فیلڈ ایک ایرے ہے (مثلاً، "document_id": ["a", "b"]), تو وہ نقطہ مختلف گروپ میں شامل ہو سکتا ہے (مثلاً، "document_id": "a" اور document_id: "b").
یہ فعالیت دی گئی group_by کلید پر بے حد منحصر ہے۔کارکردگی کو بہتر بنانے کے لیے، یقینی بنائیں کہ اس کے لیے ایک مخصوص انڈیکس بنایا گیا ہے۔ پابندیاں:
-
group_byپیرامیٹر صرف کوئی ورد اور عددی پیمانے کی قیمتوں کو سپورٹ کرتا ہے۔ دیگر پیمانے کی قیمتیں نظر انداز کر دیں گئیں۔ - موجودہ وقت میں groups کا استعمال کرتے وقت صفحہ بندی کی حمایت نہیں کی جاتی ہے، لہذا
offsetپیرامیٹر کی اجازت نہیں ہے۔
گروپس کے اندر تلاش
(وی.1.3.0 سے دستیاب)
وقتی حالتوں میں جب ایک چیز کے مختلف حصوں کے لئے متعدد نُقطوں ہوتے ہیں، ذخیرہ شدہ ڈیٹا میں عرضیت عموماً پیدا ہوتی ہے۔ اگر نُقطوں کے درمیان مشترک معلومات کم ہوں، تو یہ قابل قبول ہو سکتا ہے۔ تاہم، بھاری بوجھ سے یہ مسئلہ پیدا ہو سکتا ہے، کیونکہ یہ گروپ میں نقطوں کی تعداد کے مبنی ہوگا۔
جب گروپس استعمال کرتے وقت ذخیرہ میں حسن انداز ممکن ہوتا ہے، تو ایک اندر پیشہ جات کلیکشن میں گروپ آئی ڈی کے مطابقت سے نقطوں کے درمیان مشترک معلومات کو ایک ہی نقطے میں ذخیرہ کرنا ہے۔ پھر جب گروپس API کا استعمال ہوتا ہے، ہر گروپ کے لئے اس معلومات کو شامل کرنے کے لیے with_lookup پیرامیٹر شامل کریں۔
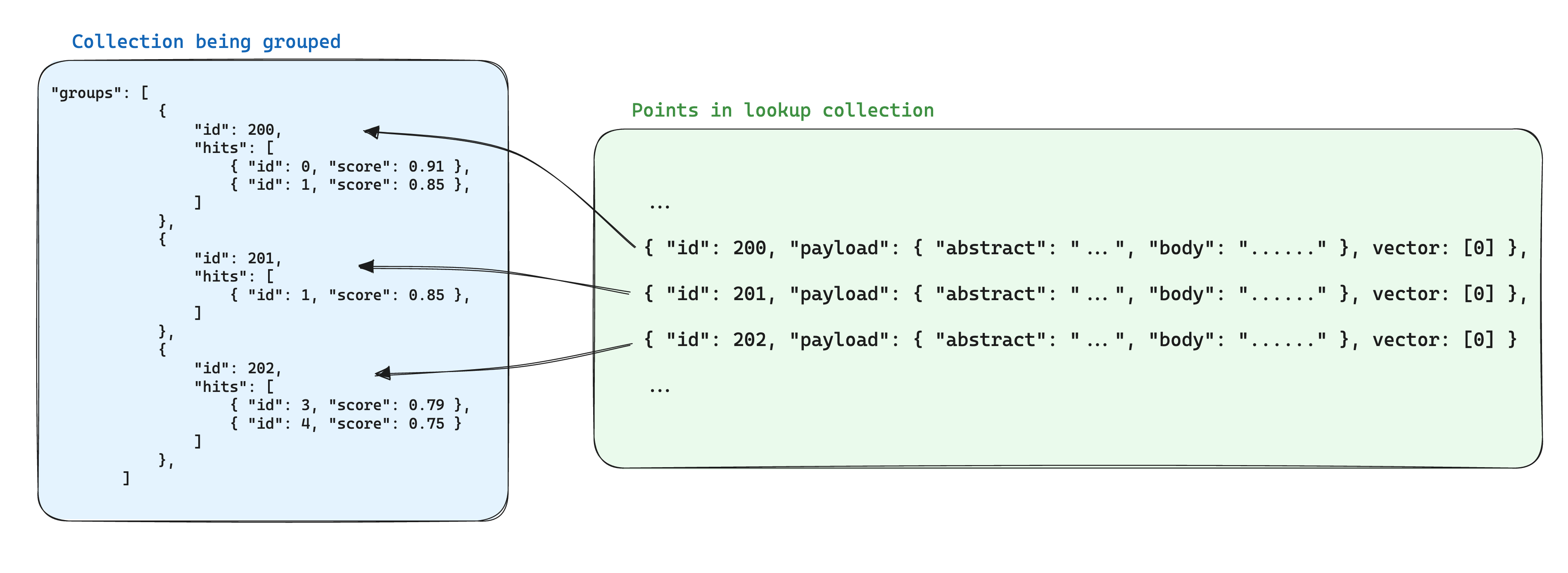
اس طریقے کا ایک اضافی فائدہ یہ ہے کہ گروپ نقطوں کے اندر مشترک معلومات تبدیل ہونے پر صرف ایک نقطے کو اپ ڈیٹ کرنا ہوتا ہے۔
مثلاً، اگر آپ کے پاس کسی دستاویز کا مجموعہ ہے تو آپ انہیں ٹکڑوں میں تقسیم کرکے ان ٹکڑوں میں شامل نقطے الگ الگ کلیکشن میں ذخیرہ کرنا چاہتے ہوں، اس سے یہ یقینی بنایا جائے کہ دستاویز کے نقطوں کی آئی ڈی ٹکڑوں کے نقطے کی پیمائش میں ذخیرہ ہوں۔
اس سناریو میں، دستاویزوں کی معلومات کو ٹکڑوں میں لانے کے لیے with_lookup پیرامیٹر استعمال کیا جاسکتا ہے:
POST /collections/chunks/points/search/groups
{
// ریگولر تلاش API میں جیسے ہی پیرامیٹرز
"vector": [1.1],
...,
// گروپ بنانے والے پیرامیٹرز
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// تلاش پیرامیٹرز
"with_lookup": {
// تلاش کرنے والے نقطوں کی کلیکشن کا نام
"collection": "documents",
// مواد کا اندر لانا مختصراً سے منتخب کرتا ہے
"with_payload": ["title", "text"],
// سانچوں میں سے مواد لانا مختصراً سے منتخب کرتا ہے
"with_vectors": false
}
}
with_lookup پیرامیٹر کے لئے، مختصر with_lookup="documents" بھی استعمال کیا جا سکتا ہے تاکہ مختارہ سانچوں اور سانچو کے ساتھ ساتھ پوری پیمائش دیکھائی دے بغیر سب معلومات ضروری ہوں۔
تلاش کے نتائج گروپ کے ہر زیر مجموعوں کے تحت lookup فیلڈ میں دکھائی دی جائیں گی۔
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Document A",
"text": "This is document A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Document B",
"text": "This is document B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
جیسا کہ نُقطوں کی آئی ڈی کی سیدھی موازنہ سے تلاش کیا گیا ہے، اسی لئے وہ گروپ آئی ڈی جو موجود نہیں ہیں (اور درست نہیں ہیں) نقطہ آئی ڈیوں کو نظرانداز کر دیا جائے گا، اور lookup فیلڈ خالی ہو گا۔