অনুরূপতা অনুসন্ধান
মেশিন লার্নিং এর অনেক অ্যাপ্লিকেশনে, নিকটতম ভেক্টর অনুসন্ধান একটি মৌলিক উপাদান। আধুনিক নিউরাল নেটওয়ার্ক গুলি বস্তুগুলি ভেক্টরে রূপান্তরিত করার জন্য প্রশিক্ষিত হয়, যা ভেক্টর স্পেসে সন্নিকট হয় এবং প্রাকৃতিক বিশ্বেও সন্নিকট হয়। উদাহরণস্বরূপ, একই অর্থের পাঠ, দৃশ্যমান ছবি, বা একই ধরনের গান।
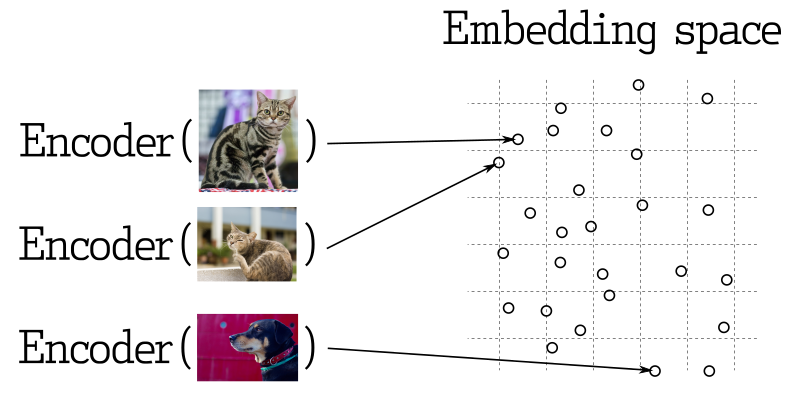
অনুরূপতা পরিমাপ
ভেক্টর মধ্যে সাদৃশ্য পরীক্ষার বিভিন্ন পদ্ধতি রয়েছে। Qdrant এ, এই মেথডগুলি সিমিল্যারিটি মেশারম বলে থাকে। পরিমাপ নির্বাচন করা হয় কিভাবে ভেক্টরগুলি প্রাপ্ত হয়, সাধারণত নিউরাল নেটওয়ার্ক এনকোডার প্রশিক্ষণে ব্যবহৃত পদ্ধতির উপর।
Qdrant সমর্থন করে নিম্নলিখিত সবচেয়ে সাধারণ প্রকার এর পরিমাপ:
- ডট প্রোডাক্ট:
ডট - কোসাইন সিমিল্যারিটি:
কোসাইন - ইউক্লিডিয়ান দূরত্ব:
ইউকলিড
সিমিল্যারিটি লার্নিং মডেলে সবচেয়ে সর্বাধিক ব্যবহৃত পরিমাপ হল কোসাইন পরিমাপ।
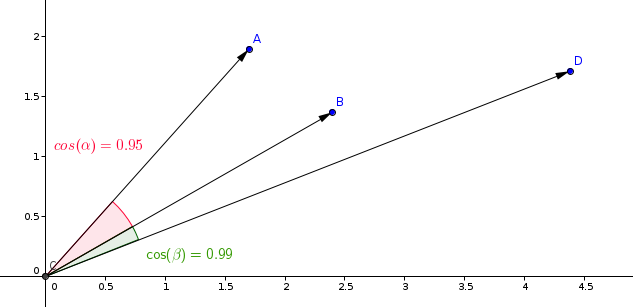
Qdrant এ এই মাপ নির্ধারণ দুই ধাপে গণনা করে, তাদের পাশে বা গতিশীল অপারেশনের জন্য উচ্চ অপারেশনের জন্য সরবরাহ করা। প্রথম ধাপ হল ভেক্টরগুলি সাধারণভাবে যোগ করার সময় তাদের স্থিতি পরিবর্তন করা। এটা কেবলমাত্র প্রতিটি ভেক্টরের জন্য একবার করা হয়।
দ্বিতীয় ধাপ হল ভেক্টর তুলনা। এই মামলায়, এটা SIMD এর দ্রুত অপারেশনের কারণে ডট প্রোডাক্ট অপারেশনের সমান হয়।
ক্যুয়ারি পরিকল্পনা
অনুসন্ধানে ব্যবহৃত ফিল্টারের নির্ভরতা, কিছু সম্ভাব্য স্কেনারিও এর জন্য কিছু প্রশ্ননির্ধারণ রয়েছে। Qdrant নির্ধারণ করে যে কোনও কুয়েরি প্রয়োগ করে, উপলব্ধ ইনডেক্স, শর্ত সম্পাদনের জটিলতা, এবং ফিল্টারকৃত ফলাফলের কার্ডিনালিটি অনুযায়ী। এই প্রক্রিয়াকে কুয়েরি পরিকল্পনা বলা হয়।
প্রয়োজন অনুসারে রণনীতিমূলক অ্যালগোরিদম দ্বারা রণনীয়। তবে, সাধারণ নীতি হল:
- প্রত্যেক সেগমেন্ট (সেগমেন্ট সম্পর্কে বিস্তারিত তথ্যের জন্য, স্টোরেজ দেখুন) এর জন্য স্বতন্ত্রভাবে ক্যুয়ারি পরিকল্পনা প্রয়োগ করুন।
- যদি পয়েন্টের সংখ্যা কম হয়, তবে প্রাথমিক স্ক্যানগুলি প্রাধান্য প্রদান করুন।
- নির্ধারণ করুন ফিল্টারকৃত ফলাফলের কার্ডিনালিটি প্রয়োজন।
- কার্ডিনালিটি কম হলে পয়েন্টগুলি পেতে পেইলোড ইনডেক্স ব্যবহার করুন (দেখুন ইনডেক্সের).
- কার্ডিনালিটি বেশি হলে, ফিল্টার করা ভেক্টর ইনডেক্স ব্যবহার করুন।
এই configuration file এর মাধ্যমে প্রতিটি সংগ্রহের জন্য ঠেষ্টা আলাদা করে পরিষ্কার করা যেতে পারে।
সার্চ API
আসুন একটি সার্চ কুয়ারীর একটি উদাহরণ দেখা যাক।
REST API - API স্কিমা পরিভ্রমণ পাওয়া যাবে এখানে।
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "লন্ডন"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
এই উদাহরণে, আমরা ভেক্টর [0.2, 0.1, 0.9, 0.7] এর মতো ভেক্টর খোঁজ করছি। প্যারামিটার limit (বা এর অ্যালিয়াস top) সংগ্রহ করতে চাইলে আমাদের কিছু সবসম্মিলিত ফলাফল প্রাপ্ত করা হবে।
params কীর্দের মানগুলি ব্যক্তিগত অনুসন্ধান প্যারামিটার নির্ধারণ করে। বর্তমানে পাওয়া যায় নিম্নলিখিত প্যারামিটারগুলি:
-
hnsw_ef- HNSW এলগোরিদমের জন্যefপ্যারামিটার এর মান নির্ধারণ করে। -
exact- কি উপযোগ করবেন এক্যুয়েট (ANN) সার্চ অপশন। যদি এটি True হয়, তবে পূর্ণ স্ক্যান অনুযায়ী নির্ধারিত ফলাফল প্রাপ্ত করার জন্য সার্চ বেশ সময় নেওয়া যেতে পারে। -
indexed_only- এই অপশন ব্যবহার করে এক্ষেপ্ট আপডেটের জন্য সার্চ করে এখনো ভেক্টর ইনডেক্স তৈরি না করা বিভাগগুলিতে। এটা আপডেটের সার্চ কর্মক্ষমতা কমাতে দরকারী হতে পারে। এই অপশনটি ব্যবহার করা হতে পারে, যদি অ্যাকসেপ্টেবল উচ্চাকাঙ্খি দীর্ঘদিনের সামঞ্জস্যপূর্ণভাবে আবদ্ধ হয় যা প্রয়োজনীয়। এই অপশন ব্যবহার করা সেরা হতে পারে, যদি যে কোনও কার্যরত না থাকা এবং ফলাফল অংশগুলি অসম্পূর্ণ ইনডেক্স করা না।
যেহেতু filter প্যারামিটারটি নির্ধারণ করা হয়েছে, সার্চটি শুধুমাত্র ফিল্টারিং মান মেলার মধ্যে পরিচালিত হয়। সম্ভাব্য ফিল্টার এবং তাদের কার্যক্ষমতার বিস্তারিত তথ্যের জন্য অনুগ্রহ করে ফিল্টার বিভাগের দিকে দেখুন।
এই API-র জন্য একটি নমুনা ফলাফল এর মধ্যে এমন হতে পারে:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result এমন একটি প্রাপ্ত পয়েন্টের একটি তালিকা ধারণ করে যা score দ্বারা সার্ট করা হয়।
দয়া করে মনে রাখবেন যে, ডিফল্টভাবে, এই ফলাফলগুলি পেইলোড এবং ভেক্টর ডাটা অন্যান্য ফরিমে প্রদান করে না। প্রধান এবং ভেক্টর এবং ফলাফল ফলাফল অপশন সম্পর্কে বিস্তারিত তথ্যের জন্য পেইলোড এবং ভেক্টর বিভাগে দেখুন।
ভার্সন v0.10.0 থেকে উপলব্ধ
যদি কোলেকশন একাধিক ভেক্টর দিয়ে তৈরি হয়, আগামী অনুসন্ধানের জন্য ব্যবহার করা হতে পারেঃ
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
এই খোঁজ শুধুমাত্র একই নামের ভেক্টর মধ্যে পরিচালিত হয়।
স্কোর দ্বারা ফলাফল ফিল্টার করা
পতিতা ফিল্টার ছাড়াও, ছেলে-মেয়েরা মান লেবেল অপশনের সাথে রেজাল্ট ফিল্টারিং এই উপযোগী হতে পারে। উদাহরণস্বরূপ, যদি আপনি মডেলের জন্য ন্যূনতম গ্রহণযোগ্য স্কোর জানেন এবং সীমানা নীচের সীমানা সার্চ জন্য ব্যবহার না করতে চান তাহলে আপনি সার্চ কুয়ারীর জন্য score_threshold প্যারামিটারটি ব্যবহার করতে পারেন। এটা দেওয়া লেগে ভেলুর নীচে রেজাল্টগুলি বাদ দেয়।
এই প্যারামিটারটি ব্যবহার করে প্রয়োজনীয় মেট্রিক ব্যবহার করা স্কোর সহ নিম্ন এবং উচ্চ স্কোর বাদ দেওয়া যেতে পারে। উদাহরণস্বরূপ, Euclidean মেট্রিকে উচ্চ স্কোরগুলি দূরে মনে করা হয় এবং এতে পরীক্ষা করা হয়।
পেইলোড এবং রেজাল্টে ভেক্টর
ডিফল্ট ভাবে, প্রেরণের উপায়টি যেকোনো সংরক্ষিত তথ্য, যেমন পেইলোড এবং ভেক্টর প্রদান করে না। অতিরিক্ত প্যারামিটার with_vectors এবং with_payload এই আচরণটি পরিবর্তন করতে পারে।
উদাহরণঃ
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
with_payload প্যারামিটারটি এছাড়াও ব্যবহার করা যেতে পারে বিশেষ ক্ষেত্রেঃ
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Batch Search API
ভার্সন v0.10.0 থেকে উপলব্ধ
ব্যাচ অনুসন্ধান API একটি একক অনুরোধের মাধ্যমে একাধিক অনুসন্ধান অনুরোধ প্রয়ান করার অনুমতি দেয়।
এর অর্থশাস্ত্র সহজ, n ব্যাচ অনুসন্ধান অনুরোধ n বিভিন্ন অনুসন্ধান অনুরোধের সমান।
এই পদ্ধতিটির অনেক সুবিধা আছে। মনোযোগী হিসাবে, এটি অল্প নেটওয়ার্ক সংযোগের প্রয়োজন আছে, যা নিজস্বতা দিয়ে সুবিধাজনক।
আরও গুরুত্বপূর্ণভাবে, যদি ব্যাচ অনুরোধের একই ফিল্টার এ থাকে, তবে এই অনুরোধগুলি তারিখিত হতে এবং জিয়া নির্ধারণ করির মাধ্যমেই সুসংগতি সাধ্য।
এটা অসাধারণ নির্ধারিত চাঁদার জন্য ল্যাটেন্সির উপর অসাধারণ প্রভাব ফেলে। কারণ, মধ্যমিক ফলাফলগুলি অনুরোধগুলির মাঝে ভাগ করা হতে পারে।
এটি ব্যবহার করতে, আপনার অনুসন্ধান অনুরোধগুলি একত্রিত প্যাক করুন। কোরবাস, সমস্ত নিয়মিত অনুসন্ধান অনুরোধ প্রায় উপলব্ধ।
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "লন্ডন"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "লন্ডন"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
এই API-র ফলাফল সম্পর্কের জন্য এই API-র ফলাফল সম্পর্কে একটি অ্যারে থাকে।
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ঠিক আছে",
"time": 0.001
}
পরামর্শিত API
নেতিবাচক ভেক্টর একটি পরিচয়কৃষ্ট বৈশিষ্ট্য এবং সমস্ত ধরনের ইম্বেডিংসের সাথে কাজ করার নিশ্চিত নয় একটি প্রযোজনীয় বৈশিষ্ট্য। সবে সাধারণ অনুসন্ধানের পাশাপাশি, Qdrant আপনাকে আপনার নথিভুক্ত মৌলিক অব্জেক্টগুলির ভেক্টর অনুসন্ধান করার জন্য অনুমতি দেয়। এই API ব্যবহার ওয়ালা ভেক্টর সনাক্ত করে যে কোনও ধরনের গণনা নিয়ন্ত্রণ নেই।
পরামর্শিত API আপনাকে একাধিক গতিসূত্র এবং নেতিবাচক ভেক্টর আইডি সুনির্দিষ্ট করতে দেয়, এবং পরিষেবাটি এগুলোকে একটি সীমানা ভেক্টরে মার্জ করবে।
গুণিত ভেক্টর = গড় (ধনাত্মক ভেক্টর) + ( গড় (ধনাত্মক ভেক্টর) - গড় (নেতিবাচক ভেক্টর) )
যদি শুধুমাত্র একটি ধনাত্মক আইডি প্রদান করা হয়, তবে এই অনুরোধটি তাত্ত্বিকভাবে এমন একটি ফ্লেটির ভেক্টরের জন্য স্বাভাবিক অনুসন্ধানের সমান।
নেতিবাচক ভেক্টরের বৃহত্তর মানসমূহ দণ্ডিত করা হয়, যতটা ধনাত্মক ভেক্টরের বৃহত্তর মানসমূহ বাড়ানো হয়। এই গড় ভেক্টরটি তারপর সংগ্রহের সর্বাধিক অনুরূপ ভেক্টরগুলি খুঁজে আবার ব্যবহার করা হয়।
দর্শনার্থে REST API-র জন্য API স্কিমা সংজ্ঞানা এখানে পাওয়া যাবে এখানে।
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "লন্ডন"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
এই API-র জন্য নমুনা ফলাফল নিম্নরূপ:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ঠিক আছে",
"time": 0.001
}
ভার্সন v0.10.0 থেকে উপরে
যদি সংগ্রহটি একাধিক ভেক্টর ব্যবহার করে তৈরি করা হয়, তবে পরামর্শ রিকোয়েস্টে ব্যবহৃত ভেক্টরগুলির নামগুলি উল্লেখ করা আবশ্যক:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
using প্যারামিটারটি পরামর্শ দেয় যে পরামর্শের জন্য সঞ্চিত ভেক্টরটি ব্যবহার করা হবে।
ব্যাচ প্রস্তাবিত API
v0.10.0 এবং তারপর থেকে উপলব্ধ
ব্যাচ অনুসন্ধান API এর মতো, এই API টি প্রেরণ করে প্রসঙ্গে অনুশীলন করতে পারে। এটি একই ভূক্তি এবং সুবিধা সহ অনুসন্ধানের অনুরোধ প্রসেস করতে পারে।
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "লন্ডন"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "লন্ডন"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
এই API এর ফলাফলে প্রতিটি সুপারিশের জন্য একটি অ্যারে থাকে।
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
পেজিনেশন
v0.8.3 এবং তারপর থেকে উপলব্ধ
অনুসন্ধান এবং সুপারিশ API মধ্যে প্রথম কিছু ফলাফল ছাড়া বাকি ফলাফলের মাত্রার মুখে শুরু করে কেবলমাত্র ফলাফল পুনরাবৃত্তি করা যায়।
উদাহরণ:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
এটি প্রাথমিক ১০০ থেকে সুপারিশের ১১তম পৃষ্ঠা পরিবর্তন করে।
বড় এলাকা মান আছে অনেকটা ভালো হতে পারে, এবং ভেক্টর ভিত্তিক পাওয়া মেথডটি সাধারণত পেজ
গ্রুপিং এপিআই
সংস্করণ v1.2.0 থেকে উপলব্ধ
ফলাফলগুলি একটি নির্দিষ্ট ফিল্ডের উপর ভিত্তি করে গ্রুপ করা যেতে পারে। এটা খুব দরকারি হতে পারে যখন একই আইটেমের জন্য আপনার বেশি বিন্দু থাকবে এবং ফলাফলে অনুপ্রবণ এন্ট্রিগুলি এড়ানোর জন্য।
উদাহরণস্বরূপ, যদি আপনার একটি বড় ডকুমেন্ট থাকে যা বেশি স্লিস করে ভাগ করা হয়েছে এবং প্রতিটি ডকুমেন্টের ভিত্তিতে অনুসন্ধান বা সুপারিশ করতে চান, তাহলে আপনি ফলাফলগুলি ডকুমেন্ট আইডি দ্বারা গ্রুপ করতে পারেন।
ধরা যাক পয়েন্টগুলিতে উপাদানগুলিঃ
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
গ্রুপ এপিআই ব্যবহার করে, আপনি প্রতিটি ডকুমেন্টের জন্য শীর্ষ N পয়েন্ট পেতে পারবেন, যদি পয়েন্টের পেলোয়েরের আইডিতে পয়েন্টের পেলোয়ের মেটাডাটা থাকে। অবশ্যই, ক্ষেত্রগুলিতে হতে পারে যেখানে সেরা N পয়েন্ট পূরণ হতে পারে না বা অনুসন্ধান থেকে অবস্থানের প্রতিরোধের কারণে। প্রতিটি মামলায়, group_size হ'ল একটি সেরা-প্রচেষ্টা প্যারামিটার, limit প্যারামিটারের মত।
গ্রুপ অনুসন্ধান
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// নির্দিষ্ট সাধারণ অনুসন্ধান এপিআইর মত
"vector": [1.1],
...,
// গ্রুপ করার পরামিতি
"group_by": "document_id", // গ্রুপ করার ফিল্ড পাথ
"limit": 4, // সর্বাধিক গ্রুপের সংখ্যা
"group_size": 2, // প্রতি গ্রুপের সর্বাধিক নামবার
}
গ্রুপ প্রস্তাবনা
REST API (স্কিমা):
POST /collections/{collection_name}/points/recommend/groups
{
// সাধারণ প্রস্তাবনা API এর মত
"negative": [1],
"positive": [2, 5],
...,
// গ্রুপ প্যারামিটার
"group_by": "document_id", // গ্রুপ করার জন্য ফিল্ড পাথ
"limit": 4, // সর্বাধিক গ্রুপের সংখ্যা
"group_size": 2, // প্রতি গ্রুপের সর্বাধিক পয়েন্টের সংখ্যা
}
সার্চ বা প্রস্তাবনা হোক, আউটপুট ফলাফলগুলি নিম্নলিখিত হবে:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
গ্রুপগুলি প্রত্যাশিত শ্রেণিত হবে প্রতি গ্রুপের মধ্যে পয়েন্টগুলির সর্বোচ্চ স্কোর অনুযায়ী। প্রত্যেক গ্রুপে, পয়েন্টগুলি প্রস্তুতি অনুযায়ী শ্রেণিবদ্ধ হবে।
যদি একটি পয়েন্টের group_by ফিল্ড একটি অ্যারে হয় (উদাহরণস্বরূপ, "document_id": ["a", "b"]), তবে তারা একাধিক গ্রুপে অন্তর্ভুক্ত হতে পারে (উদাহরণস্বরূপ, "document_id": "a" এবং document_id: "b").
এই ফাংশনালিটি ভারপ্রাপ্তি করে প্রদত্ত group_by কী-তে ভরে যান। কার্যকরীতা উন্নত করতে, নিশ্চিত করুন যে এর জন্য একটি নিষ্ক্রিয় ইন্ডেক্স তৈরি করা হয়েছে। সীমাবদ্ধতা:
-
group_byপ্যারামিটারটি কেবল কীওয়ার্ড এবং ইন্টিজার পেলোড মান সমর্থন করে। অন্যান্য পেলোড মান উপেক্ষিত হবে। - বর্তমানে পেজিনেশন সমর্থন করে না যখন গ্রুপ ব্যবহার করা হয়, তাই
offsetপ্যারামিটারটি অনুমোদিত নয়।
গ্রুপ সার্চ
ভার্সন v1.3.0 পরবর্তী
এমন ক্ষেত্রে যেখানে একই আইটেমের বিভিন্ন অংশের জন্য একাধিক পয়েন্ট আছে, সেই সংরক্ষিত ডেটা সাধারণভাবে পুনরাবৃত্তি আনে। যদি পয়েন্টগুলির মধ্যে ভাগ করা তথ্য অত্যন্ত কম হয়, তাহলে এটা গ্রহণযোগ্য হতে পারে। তাছাড়া, যদি ভারী লোডের সাথে সমস্যা হয়, তবে এটি সমস্যাজনক হতে পারে, কারণ এটি পয়েন্টের জন্য সংরক্ষণের স্থান গণনা করবে পয়েন্টগুলির সংখ্যার উপরে ভিত্তি করে।
গ্রুপ ব্যবহার করার সময় সংরক্ষণ জন্য একটি অপটিমাইজেশন হ'ল একই গ্রুপ আইডি ভিত্তিক পয়েন্টগুলির মধ্যে যে তথ্য ভাগক্ষেত্র করা হয়, এটি অন্য একটি কালেকশনে একটি একক পয়েন্টে সংরক্ষণ করা। তারপর, groups API ব্যবহার করার সময়, প্রতিটি গ্রুপের জন্য এই তথ্য যোগ করতে with_lookup প্যারামিটার যোগ করুন।
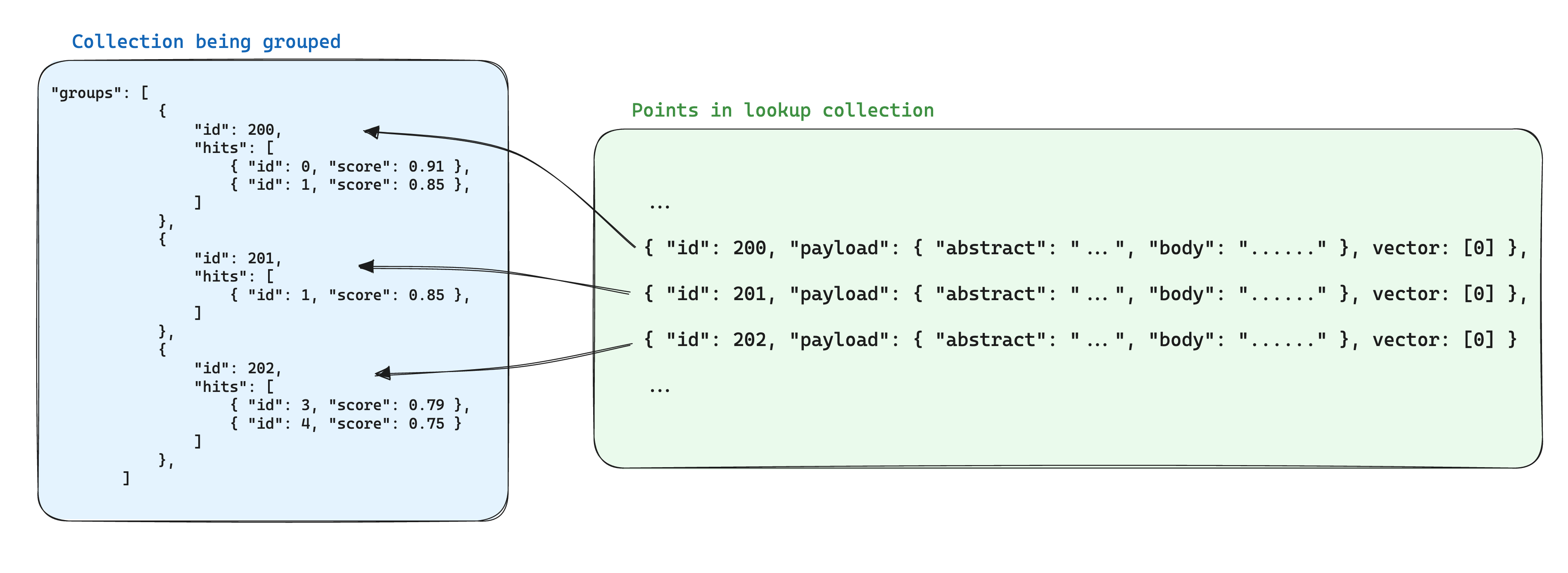
এই পদক্ষেপের একটি অতিরিক্ত সুবিধা হল যেখানে গ্রুপ পয়েন্টের মধ্যে ভাগক্ষেত্রের তথ্য পরিবর্তন হয়, কেবল একটি একক পয়েন্টটি আপডেট করা প্রয়োজন।
উদাহরণস্বরূপ, যদি আপনার কাগজপত্রের একটি সংগ্রহ থাকে, তবে আপনি তাদেরকে টুকরো করে এবং এই চুঙকগুলি প্যারাগ্রাফে, আপনি যে পয়েন্টগুলি জমাটানো হয়েছে তা আলাদা একটি সংগ্রহে স্টোর করতে চাইতে পারেন।
এই স্কেনারিতে, দস্তাবেজের তথ্যগুলি চুঙ্কের মধ্যে নিয়ে আনা এবং দস্তাবেজের তথ্যগুলি দস্তাবেজ আইডি দ্বারা গ্রুপভুক্ত করার জন্য with_lookup প্যারামিটারটি ব্যবহার করা যেতে পারে:
POST /collections/chunks/points/search/groups
{
// সাধারণ সার্চ API এবং একই প্যারামিটার সমান মান
"vector": [1.1],
...,
// গ্রুপিং প্যারামিটার
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// খোঁজ প্যারামিটার
"with_lookup": {
// খোঁজ পয়েন্টের প্যারামিটার কালেকশনের নাম
"collection": "documents",
// খোঁজ পয়েন্টের পেলোড থেকে যে বিষয়গুলি নিয়ে আনা হবে, অপশন ডিফল্ট হল সত্য
"with_payload": ["title", "text"],
// খোঁজ পয়েন্টের ভেক্টর থেকে যে বিষয়গুলি নিয়ে আনা হবে, অপশন ডিফল্ট হল সত্য
"with_vectors": false
}
}
with_lookup প্যারামিটারের জন্য, শর্টহ্যান্ড with_lookup="documents" ব্যবহার করা যেতে পারে যেগুলি স্পষ্টভাবে নির্দিষ্ট না করে সম্পূর্ণ পেলোড এবং ভেক্টর নিয়ে আসতে।
খোঁজের ফলাফলগুলি প্রত্যেক গ্রুপের অন্তর্ভুক্ত হবে লুকআপ ফিল্ডে।
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "ডকুমেন্ট A",
"text": "এটা ডকুমেন্ট A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "ডকুমেন্ট B",
"text": "এটা ডকুমেন্ট B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
পয়েন্ট আইডিগুলির সরাসরি ম্যাচিং করার মাধ্যমে খোঁজ করা হয়েছে, এমনকি যেকোনো গ্রুপ আইডিগুলি যেগুলি বিদ্যমান নয় এবং বৈধ পয়েন্ট আইডিগুলি বুঝা হয়নি, সেগুলি অগ্রাহ্য হবে এবং লুকআপ ফিল্ডটি ফাঁকা থাকবে।