جستجوی مشابهت
در بسیاری از برنامههای یادگیری ماشین، جستجوی بردارهای نزدیک یک عنصر اصلی است. شبکههای عصبی مدرن برای تبدیل اشیاء به بردارها آموزش دیده میشوند، به طوری که اشیاء نزدیک در فضای برداری نیز در جهان واقعی نزدیک باشند. به عنوان مثال، متنهای با معانی مشابه، تصاویر به طور بصری مشابه، یا آهنگهای تعلق گرفته به یک سبک موسیقی خاص.
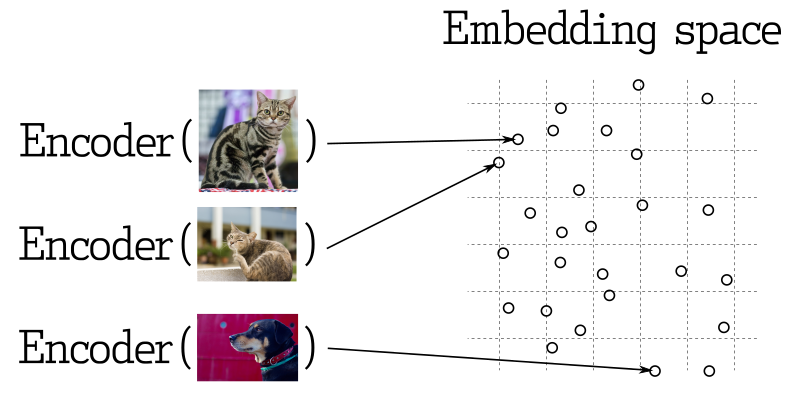
اندازهگیری مشابهت
روشهای زیادی برای ارزیابی مشابهت بین بردارها وجود دارد. در Qdrant، این روشها به اندازهگیری مشابهت معروف هستند. انتخاب اندازهگیری به ویژه از چگونگی به دست آوردن بردارها و به ویژه از روش استفاده شده برای آموزش رمزگذار شبکه عصبی وابسته است.
Qdrant از اندازهگیریهای شایع زیر پشتیبانی میکند:
- Dot product:
Dot - Cosine similarity:
Cosine - Euclidean distance:
Euclid
معمولاً اندازهگیری مشابهت های استفاده شده در مدلهای یادگیری مشابهت، اندازهگیری کسینوسی میباشد.
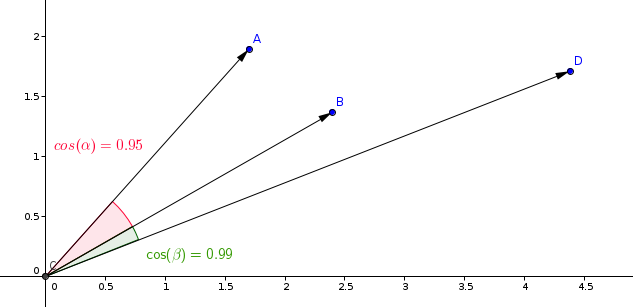
Qdrant این اندازهگیری را در دو مرحله محاسبه میکند، و این امر منجر به سرعت بالاتر جستجو میشود. مرحله اول نرمالسازی بردارها هنگام افزودن آنها به مجموعه است. این کار فقط یکبار برای هر بردار انجام میشود.
مرحله دوم مقایسه بردارهاست. در این حالت معادل یک عمل ضرب داخلی است، به دلیل عملیات سریع SIMD.
برنامه پرس و جو
به وابستگی به فیلترهای استفاده شده در جستجو، چندین سناریو ممکن برای اجرای پرس و جو وجود دارد. Qdrant یکی از گزینههای اجرای پرس و جو را بر اساس فهرستهای موجود، پیچیدگی شرایط و تعداد اعضای نتایج فیلتر شده انتخاب میکند. این فرآیند، برنامهریزی پرس و جو نام دارد.
فرآیند انتخاب استراتژی بر اساس الگوریتمهای هوریستیک وابسته به نسخه است و ممکن است بر اساس آن اختلاف داشته باشد. با این حال، اصول عمومی عبارتند از:
- اجرای برنامههای پرس و جو به صورت مستقل برای هر بخش (برای اطلاعات دقیق در مورد بخشها، لطفا به ذخیرهسازی مراجعه کنید).
- اولویت بخشهای کامل اگر تعداد نقاط کم باشد.
- ارزیابی تعداد اعضای نتایج فیلتر شده پیش از انتخاب یک راهبرد.
- استفاده از فهرستهای محتوا برای بازیابی نقاط اگر تعداد اعضای نتایج کم باشد (برای اطلاعات بیشتر به فهرستها مراجعه کنید).
- استفاده از فهرستهای بردارهای قابل فیلترینگ اگر تعداد اعضای نتایج بالا باشد.
با استفاده از فایل پیکربندی به صورت مستقل برای هر مجموعه، میتوان آستانهها را تنظیم کرد.
جستجو API
در اینجا یک مثال از یک جستجوی خاص را بررسی خواهیم کرد.
REST API - تعاریف اسکیمای API را میتوانید در اینجا پیدا کنید.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
در این مثال، ما به دنبال بردارهای مشابه بردار [0.2، 0.1، 0.9، 0.7] هستیم. پارامتر limit (یا همتا top) تعداد نتایج مشابه مورد نظری که میخواهیم بازیابی کنیم را مشخص میکند.
مقادیر زیر کلید params پارامترهای جستجوی سفارشی را مشخص میکنند. پارامترهای موجود در حال حاضر عبارتند از:
-
hnsw_ef- مقدار پارامترefبرای الگوریتم HNSW را مشخص میکند. -
exact- آیا از گزینه جستجوی دقیق (ANN) استفاده شود یا خیر. اگر به True تنظیم شود، جستجو ممکن است زمان زیادی طول بکشد زیرا یک اسکن کامل برای به دست آوردن نتایج دقیق انجام میدهد. -
indexed_only- استفاده از این گزینه میتواند جستجو در بخشهایی که هنوز یک اندیس بردار ساخته نشدهاند را غیرفعال کند. این ممکن است برای کمینه کردن تأثیر بروزرسانیها بر کارایی جستجو مفید باشد. استفاده از این گزینه ممکن است منجر به نتایج جزئی شود اگر مجموعه به طور کامل ایندکسنشده باشد پس فقط در مواردی از این گزینه استفاده کنید که تطبیق پذیری نهایی قابل قبول مورد نیاز باشد.
از آنجا که پارامتر filter مشخص شده است، جستجو فقط بین نقاطی انجام میشود که شرایط فیلتر کردن را برآورده میکنند. برای اطلاعات بیشتر درمورد فیلترهای ممکن و کارایی آنها، لطفا به بخش فیلترها مراجعه کنید.
نمونهای از نتیجه برای این API ممکن است مانند این باشد:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
کلید result شامل لیستی از نقاط کشف شده مرتب شده بر اساس score است.
لطفا توجه داشته باشید که به طور پیش فرض، این نتایج شامل دادههای باری و بردار نمیباشند. برای اینکه چگونگی اضافه کردن دادههای باری و بردار را در نتایج بررسی کنید، به بخش باری و بردار در نتایج مراجعه کنید.
در دسترس است از نسخه v0.10.0
اگر یک مجموعه با چند بردار ایجاد شود، نام برداری که برای جستجو استفاده شود باید ارائه شود:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
جستجو فقط بین بردارهایی با همان نام انجام میشود.
فیلتر کردن نتایج بر اساس امتیاز
به علاوه از فیلتر کردن باری، ممکن است مفید باشد نتایج با امتیازهای شباهت کم را حذف کرد. به عنوان مثال، اگر حداقل امتیاز قابل قبول برای یک مدل را میدانید و نمیخواهید هیچ نتایج شباهت زیر آستانه را داشته باشید، میتوانید از پارامتر score_threshold برای پرس و جوی جستجو استفاده کنید. این پارامتر همه نتایج با امتیاز کمتر از مقدار داده شده را حذف میکند.
این پارامتر ممکن است نتایجی را که امتیاز کمتر یا بیشتری دارند، بسته به معیار مورد استفاده، حذف کند. به عنوان مثال، امتیازهای بالاتر در معیار اقلیدسی به عنوان دورتر در نظر گرفته میشوند و بنابراین حذف میشوند.
باری و بردارها در نتایج
به طور پیش فرض، روش بازیابی هر گونه اطلاعات ذخیره شده مانند باری و بردار را بازنمیگرداند. پارامترهای اضافی with_vectors و with_payload میتوانند این رفتار را اصلاح کنند.
مثال:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
پارامتر with_payload همچنین میتواند برای اضافه یا حذف فیلدهای خاص استفاده شود:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Batch Search API
در دسترس از نسخه v0.10.0 به بعد
دسترسی به این API امکان اجرای چندین درخواست جستجو را از طریق یک درخواست تنها فراهم می کند.
معنای آن ساده است، n درخواست جستجوی دسته ای معادل با n درخواست جستجوی جداگانه است.
این روش دارای چندین مزیت است. به طور منطقی، نیاز به اتصالات شبکه کمتری دارد که خودش مزیتی است.
به طور مهمتر، اگر درخواست های دسته یکسان فیلتر داشته باشند، درخواست دسته به طور کارآمد و بهینه از طریق برنامه ریزی پرس و جو به حالت بهینه انجام می شود.
این تأثیر قابل توجهی بر روی تاخیر برای فیلتر های غیرمعمول دارد، زیرا نتایج میانی می توانند بین درخواست ها به اشتراک گذاشته شود.
برای استفاده از آن، به سادگی درخواست های جستجوی خود را یکجا بسته بندی کنید. البته، همه ویژگی های معمول درخواست جستجو در دسترس هستند.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
نتایج این API شامل یک آرایه برای هر درخواست جستجویی است.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Recommended API
با وجود اینکه بردار منفی یک ویژگی آزمایشی است و تضمینی برای کار با همه انواع تعبیه ها ندارد، علاوه بر جستجوهای معمولی، کرانت همچنین به شما اجازه می دهد که بر اساس چندین بردار موجود در یک مجموعه جستجو کنید. این API برای جستجوی بردار اشیاء کدگذاری شده بدون درگیری از کدگذارهای شبکه عصبی استفاده می شود.
API توصیه شده به شما امکان می دهد که شناسه های چندین بردار مثبت و منفی را مشخص کنید و سرویس آنها را به یک بردار میانگین خاص ترکیب می کند.
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
اگر تنها یک شناسه مثبت ارائه شود، این درخواست معادل یک جستجوی معمول برای بردار در آن نقطه است.
اجزای برداری با مقادیر بزرگتر در بردار منفی مجازات می شوند، در حالی که اجزای برداری با مقادیر بزرگتر در بردار مثبت تقویت می شوند. سپس از این بردار میانگین برای یافتن بردارهای مشابهترین در مجموعه استفاده می شود.
تعریف طرح API برای REST API را می توانید در اینجا پیدا کنید.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
نمونه نتیجه برای این API به صورت زیر خواهد بود:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
در دسترس از نسخه v0.10.0 به بعد
اگر مجموعه با استفاده از چند بردار ایجاد شده باشد، نام بردارهای استفاده شده باید در درخواست توصیه داده شود:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "تصویر",
"limit": 10
}
پارامتر using بردار ذخیره شده را برای توصیه مشخص می کند.
پیشنهاد API دستهای
از نسخه v0.10.0 به بعد در دسترس است
مشابه API جستجوی دستهای، با استفاده و مزایای مشابه، قادر به پردازش درخواستهای پیشنهاد در دسته میباشد.
POST /collections/{نام_مجموعه}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "لندن"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
نتیجه این API شامل یک آرایه برای هر درخواست پیشنهاد میباشد.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
صفحهبندی
در نسخه v0.8.3 در دسترس است
API جستجو و پیشنهاد امکان صرف نظر کردن از نتایج اولیه جستجو و فقط بازگرداندن نتایج از یک آفست خاص را فراهم میکند.
مثال:
POST /collections/{نام_مجموعه}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
این معادل با بازیابی صفحه یازدهم، با ۱۰ رکورد در هر صفحه است.
استفاده بیش از حد از آفست ممکن است منجر به مشکلات عملکردی شود و متد بازیابی بردار معمولاً از صفحهبندی پشتیبانی نمیکند. بدون بازیابی اولین N بردار، امکان بازیابی N امین بردار نزدیک وجود ندارد.
با این حال، استفاده از پارامتر آفست میتواند با کاهش ترافیک شبکه و دسترسی به ذخیره سازی، منابع را صرفهجویی کند.
در استفاده از پارامتر آفست، ضروری است که داخلیاً آفست + محدودیت نقاط بازیابی شود، اما تنها به دست آوردن نهاندار و بردارهای آن نقاطی که در واقع از ذخیره سازی بازگردانده میشوند.
گروهبندی API
قابل دسترسی از نسخه v1.2.0
نتایج میتوانند بر اساس یک فیلد خاص گروهبندی شوند. این امر بسیار مفید است زمانی که شما چندین نقطه برای یک مورد دارید و میخواهید ورودیهای تکراری در نتایج را از بین ببرید.
به عنوان مثال، اگر یک سند بزرگ را به چندین قطعه تقسیم کرده و میخواهید بر اساس هر سند جستجو یا پیشنهاد دهید، میتوانید نتایج را بر اساس شناسه سند گروهبندی کنید.
فرض کنید نقاطی با بستههای انتقال زیر وجود دارد:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
با استفاده از API groups، شما میتوانید برترین N نقطه برای هر سند را با فرض اینکه بستهای حاوی شناسه سند دارد، بازیابی کنید. البته ممکن است مواردی وجود داشته باشد که به دلیل کمبود نقاط یا فاصله نسبتاً بزرگ از پرسو سهیم، بهترین N نقاط را نتوانید برآورده کنید. در هر مورد، group_size یک پارامتر تلاش بهینه است، مشابه پارامتر limit.
جستجوی گروهی
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// همانند API جستجوی معمولی
"vector": [1.1],
...,
// پارامترهای گروهبندی
"group_by": "document_id", // مسیر فیلد برای گروهبندی
"limit": 4, // حداکثر تعداد گروهها
"group_size": 2, // حداکثر تعداد نقاط در هر گروه
}
توصیه گروهی
REST API (Schema):
POST /collections/{collection_name}/points/recommend/groups
{
// همانند API توصیه معمولی
"negative": [1],
"positive": [2, 5],
...,
// پارامترهای گروهبندی
"group_by": "document_id", // مسیر فیلد برای گروهبندی
"limit": 4, // حداکثر تعداد گروهها
"group_size": 2, // حداکثر تعداد نقاط در هر گروه
}
بهطور مستقل از اینکه این یک جستجو باشد یا یک توصیه، نتایج خروجی به صورت زیر است:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
گروهها براساس بالاترین امتیاز نقاط در هر گروه مرتب میشوند. در هر گروه، نقاط نیز مرتب میشوند.
اگر فیلد group_by یک نقطه یک آرایه باشد (برای مثال، "document_id": ["a", "b"]، نقطه میتواند در چند گروه نیز قرار گیرد (برای مثال، "document_id": "a" و document_id: "b").
این قابلیت بسیار به کلید group_by ارائهشده وابسته است. برای بهبود عملکرد، اطمینان حاصل شود که یک فهرست مخصوص برای آن ایجاد شده باشد. محدودیتها:
- پارامتر
group_byتنها از انواع مقادیر کلمهکلیدی و عددی پشتیبانی میکند. سایر انواع مقادیر پشتیبانی نمیشود. - در حال حاضر، صفحهبندی هنگام استفاده از گروهها پشتیبانی نمیشود، بنابراین پارامتر
offsetمجاز نیست.
جستجو داخل گروهها
در دسترس از نسخه v1.3.0
در مواردی که برای قسمتهای مختلف یک مورد، چندین نقطه وجود دارد، اغلب اطلاعات تکراری به دیتابیس اضافه میشود. اگر اطلاعات مشترک بین نقاط به حداقل میزان باشد، این امر ممکن است قابل قبول باشد. اما در بارهای سنگین، ممکن است مشکلساز شود زیرا فضای ذخیرهسازی بر اساس تعداد نقاط در گروه محاسبه میشود.
بهینهسازی برای فضای ذخیرهسازی هنگام استفاده از گروهها، این است که اطلاعات مشترک بین نقاط مبتنی بر همان شناسه گروه را در یک نقطه دیگر در یک مجموعه دیگر ذخیره کنیم. سپس، هنگام استفاده از واحد API، پارامتر with_lookup را برای هر گروه اضافه کنیم تا این اطلاعات برای هر گروه اضافه شود.
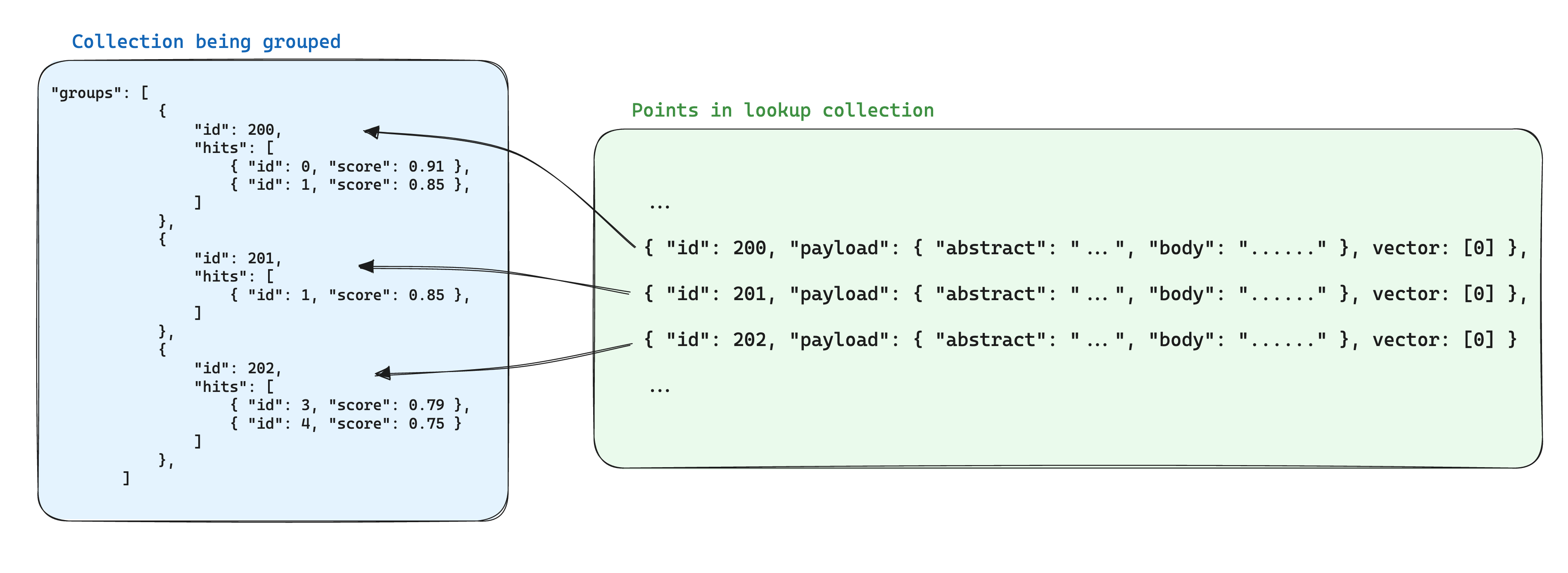
یک مزیت اضافی این رویکرد این است که هنگام تغییر اطلاعات مشترک داخل نقاط گروه، تنها نقطه تکی نیاز به بهروزرسانی دارد.
به عنوان مثال، اگر یک مجموعه از اسناد دارید، ممکن است بخواهید آنها را به بخشها تقسیم کرده و نقاط مربوط به این بخشها را در یک مجموعه جداگانه ذخیره کنید تا اطمینان حاصل کنید که شناسههای نقاط مربوط به اسناد در باره نقطه بخش ذخیره میشوند.
در این سناریو، برای احضار اطلاعات از اسناد به بخشهای گروهبندی شده بر اساس شناسه اسناد، میتوان از پارامتر with_lookup استفاده کرد:
POST /collections/chunks/points/search/groups
{
// پارامترهای مشابه جستجوی معمولی API
"vector": [1.1],
...,
// پارامترهای گروهبندی
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// پارامترهای جستجو
"with_lookup": {
// نام مجموعه نقاط برای جستجو
"collection": "documents",
// گزینههای مشخص کردن محتوایی که از payload نقاط جستجویی احضار میشود، مقدار پیشفرض true است
"with_payload": ["عنوان", "متن"],
// گزینههای مشخص کردن محتوایی که از بردارهای نقاط جستجویی احضار میشود، مقدار پیشفرض true است
"with_vectors": false
}
}
برای پارامتر with_lookup، میتوان از یک اختصار بهشرح with_lookup="documents" نیز استفاده کرد تا کل payload و بردارها را بدون اشاره مستقیم اضافه کند.
نتایج جستجو در فیلد lookup زیر هر گروه نمایش داده میشوند.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"عنوان": "اسناد A",
"متن": "این اسناد A است"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"عنوان": "اسناد B",
"متن": "این اسناد B است"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
زیرا جستجو به صورت مستقیم با همسان سازی شناسه نقطهها انجام میشود، هر گروه با شناسههای نقطههای موجود (و معتبر) ترکیب خواهد شد و فیلد lookup خالی خواهد بود.