類似検索
多くの機械学習アプリケーションでは、最も重要な要素の1つとして、最も近いベクトルを検索することが挙げられます。現代のニューラルネットワークは、オブジェクトをベクトルに変換するように訓練されており、ベクトル空間で近いオブジェクトは現実世界でも近いものとなります。例えば、意味が類似したテキスト、視覚的に類似した画像、または同じジャンルに属する曲などです。
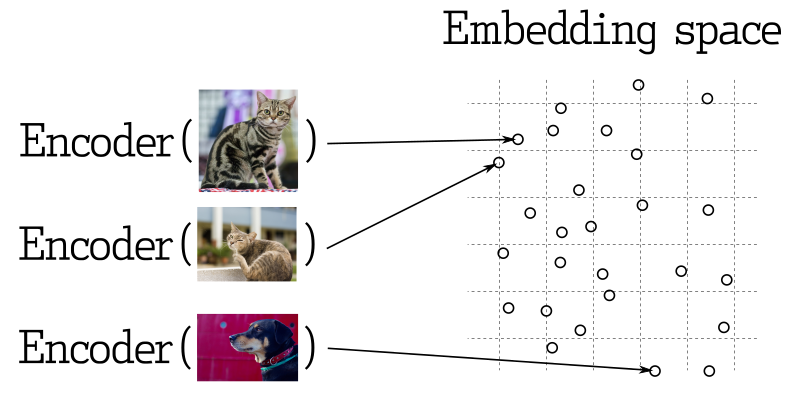
類似度測定
ベクトル間の類似度を評価するための多くの方法があります。Qdrantでは、これらの方法を類似度測定と呼んでいます。測定の選択は、特にニューラルネットワークエンコーダーのトレーニングに使用される方法に依存します。
Qdrantは、以下のよく使用される測定タイプをサポートしています:
- 内積:
Dot - コサイン類似度:
Cosine - ユークリッド距離:
Euclid
類似度学習モデルで最も一般的に使用される測定は、コサイン測定です。
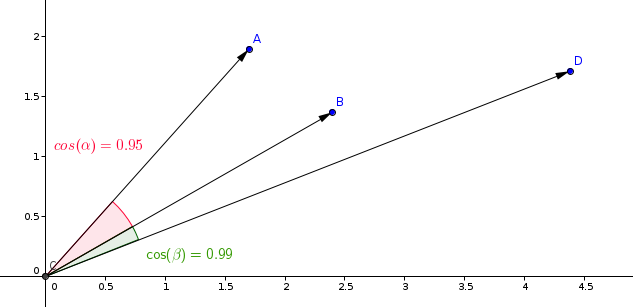
Qdrantは、2つのステップでこの測定を計算し、より高速な検索速度を実現しています。最初のステップは、ベクトルをコレクションに追加する際にベクトルを正規化することです。これは各ベクトルについて1回だけ行います。
2番目のステップは、ベクトル比較です。この場合、SIMDの高速な演算により、内積演算と同等です。
クエリプラン
検索で使用されるフィルタに応じて、クエリ実行にはいくつかの可能なシナリオがあります。Qdrantは、利用可能なインデックス、条件の複雑さ、およびフィルタされた結果の基数に基づいて、クエリ実行オプションの1つを選択します。このプロセスはクエリプランニングと呼ばれます。
戦略の選択プロセスはヒューリスティックアルゴリズムに依存し、バージョンによって異なる場合があります。ただし、一般的な原則は次のとおりです:
- 各セグメントに対してクエリプランを独立して実行します(セグメントの詳細については、ストレージを参照してください)。
- ポイントの数が少ない場合は、完全スキャンを優先します。
- 戦略を選択する前に、フィルタされた結果の基数を推定します。
- 基数が低い場合は、ペイロードインデックスを使用してポイントを取得します(インデックスを参照)。
- 基数が高い場合は、フィルタ可能なベクトルインデックスを使用します。
閾値は、構成ファイルを介して各コレクションごとに独立して調整できます。
検索API
検索クエリの例を見てみましょう。
REST API - APIスキーマ定義はここで見つけることができます。
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
この例では、ベクトル[0.2, 0.1, 0.9, 0.7]に類似するベクトルを探しています。パラメータlimit(またはその別名top)は、取得したい類似結果の数を指定します。
paramsキーの値は、カスタム検索パラメータを指定しています。現在利用可能なパラメータは以下の通りです:
-
hnsw_ef- HNSWアルゴリズムのefパラメータの値を指定します。 -
exact- 正確な(ANN)検索オプションを使用するかどうか。Trueに設定すると、完全なスキャンが実行されて正確な結果を取得するため、時間がかかる場合があります。 -
indexed_only- このオプションを使用すると、まだベクトルインデックスを構築していないセグメントでの検索を無効にすることができます。これは更新中の検索パフォーマンスへの影響を最小限に抑えるために役立ちます。このオプションを使用すると、コレクションが完全にインデックス化されていない場合に部分的な結果が得られる可能性がありますので、受け入れ可能な最終的な整合性が必要な場合にのみ使用してください。
filterパラメータが指定されているため、検索はフィルタリング基準を満たすポイントのみで実行されます。可能なフィルタとそれらの機能の詳細については、フィルタのセクションを参照してください。
このAPIのサンプル結果は以下のようになります:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
resultには、scoreでソートされた発見されたポイントのリストが含まれています。
デフォルトでは、これらの結果にはペイロードとベクトルのデータが含まれていません。結果にペイロードとベクトルを含める方法については、「結果のペイロードとベクトル」セクションを参照してください。
バージョンv0.10.0から利用可能
複数のベクトルでコレクションが作成された場合、検索に使用するベクトルの名前を指定する必要があります:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
検索は、同じ名前のベクトル間でのみ実行されます。
スコアによる結果のフィルタリング
ペイロードのフィルタリングに加えて、類似度スコアが低い結果をフィルタリングすることも有用です。たとえば、モデルの最小許容スコアを把握しており、しきい値以下の類似度結果を得たくない場合、検索クエリにscore_thresholdパラメータを使用できます。これにより、指定された値よりも低いスコアのすべての結果が除外されます。
このパラメータは、使用されるメトリックに応じて、低いスコアと高いスコアの両方を除外する可能性があります。たとえば、ユークリッド距離メトリックの場合、高いスコアはより遠くにあると見なされるため、除外されます。
結果でのペイロードとベクトル
デフォルトでは、検索方法はペイロードやベクトルなどの格納された情報を返しません。追加パラメータwith_vectorsおよびwith_payloadはこの動作を変更できます。
例:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
with_payloadパラメータは、特定のフィールドを含めるか除外するかにも使用できます:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
バッチ検索API
v0.10.0から利用可能
バッチ検索APIを使用すると、単一のリクエストを介して複数の検索リクエストを実行できます。
その意味は単純で、n個のバッチ検索リクエストはn個の別々の検索リクエストと同等です。
この方法にはいくつかの利点があります。論理的には、それ自体が有益である少ないネットワーク接続を必要とします。
さらに重要なことは、バッチリクエストが同じフィルタを持っている場合、クエリプランナーを介して効率的に処理および最適化されます。
これは、中間結果をリクエスト間で共有できるため、非自明なフィルタに対して待ち時間に重要な影響を与えます。
使用するには、単純に検索リクエストをパックしてください。もちろん、すべての通常の検索リクエスト属性が利用可能です。
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "ロンドン"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "ロンドン"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
このAPIの結果には、各検索リクエストごとの配列が含まれます。
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
おすすめのAPI
負のベクトルは実験的な機能であり、すべての種類の埋め込みとは動作が保証されていません。通常の検索に加えて、Qdrantではコレクションにすでに格納されている複数のベクトルに基づいて検索することも可能です。このAPIは、ニューラルネットワークエンコーダを介さずにエンコードされたオブジェクトのベクトル検索に使用されます。
おすすめのAPIを使用すると、複数の正および負のベクトルIDを指定でき、サービスはそれらを特定の平均ベクトルに結合します。
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
正のIDが1つだけ提供された場合、このリクエストはそのポイントのベクトルに対する通常の検索と同等です。
負のベクトルの値が大きいベクトル成分はペナルティを受けますが、正のベクトルの値が大きいベクトル成分は増幅されます。その平均ベクトルは、コレクション内の最も類似するベクトルを見つけるために使用されます。
REST APIのAPIスキーマ定義はこちらで見つけることができます。
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "ロンドン"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
このAPIのサンプル結果は以下のようになります:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
v0.10.0以降で利用可能
コレクションが複数のベクトルを使用して作成された場合、おすすめのリクエストで使用するベクトルの名前を指定する必要があります:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
usingパラメータはおすすめに使用する格納されたベクトルを指定します。
バッチ推奨 API
v0.10.0以降で利用可能
バッチ検索APIと同様に、類似の使用方法と利点を持つ、バッチで推奨要求を処理できます。
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
このAPIの結果には、各推奨要求ごとに配列が含まれます。
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
ページネーション
v0.8.3以降で利用可能
検索および推奨APIでは、検索の最初の数件をスキップし、特定のオフセットから結果を返すことができます。
例:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
これは、10レコードを1ページとして、11ページ目の取得と同等です。
大きなオフセット値を使用すると、パフォーマンスの問題が発生する可能性があり、ベクトルベースの検索方法は通常ページネーションをサポートしていません。最初のN個のベクトルを取得しないと、N番目に近いベクトルを取得することはできません。
ただし、オフセットパラメータを使用すると、ネットワークトラフィックやストレージへのアクセスを削減することでリソースを節約できます。
オフセットパラメータを使用する場合、内部的にはoffset + limitポイントを取得する必要がありますが、実際にストレージから返されたそれらのポイントのペイロードとベクトルにのみアクセスします。
グルーピングAPI
バージョンv1.2.0から利用可能
特定のフィールドに基づいて結果をグループ化することができます。同じアイテムに複数のポイントがある場合や結果に冗長なエントリを避けたい場合に非常に便利です。
例えば、大きなドキュメントを複数のチャンクに分割しており、各ドキュメントに基づいて検索や推奨をしたい場合、ドキュメントIDで結果をグループ化することができます。
ペイロードを持つポイントがあると仮定します:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
groups APIを使用すると、各ドキュメントのトップNポイントを取得できます。ポイントのペイロードにドキュメントIDが含まれていると仮定しています。もちろん、ポイントが不足している場合やクエリからの距離が比較的大きい場合には、最良のNポイントを満たすことができない場合があります。それぞれの場合において、group_sizeはlimitパラメータと同様に最善を尽くすパラメータです。
グループ検索
REST API (スキーマ):
POST /collections/{collection_name}/points/search/groups
{
// 通常の検索APIと同様
"vector": [1.1],
...,
// グループ化パラメータ
"group_by": "document_id", // グループ化に使用するフィールドパス
"limit": 4, // グループの最大数
"group_size": 2, // グループごとのポイントの最大数
}
グループ推薦
REST API(スキーマ):
POST /collections/{collection_name}/points/recommend/groups
{
// 通常の推薦APIと同様
"negative": [1],
"positive": [2, 5],
...,
// グループ化パラメータ
"group_by": "document_id", // グループ化の基準となるフィールドパス
"limit": 4, // グループ数の最大値
"group_size": 2, // グループごとのポイント数の最大値
}
検索であろうと推薦であろうと、出力結果は次の通りです:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
グループは各グループ内のポイントの最高スコアによってソートされます。各グループ内でもポイントはソートされます。
ポイントのgroup_byフィールドが配列である場合(例:"document_id": ["a", "b"])、そのポイントは複数のグループに含まれる可能性があります(例: "document_id": "a" および document_id: "b")。
この機能は提供されたgroup_byキーに大きく依存しています。性能を向上させるためには、それに専用のインデックスを作成することを確認してください。制限事項:
-
group_byパラメータはキーワードおよび整数のペイロード値のみをサポートします。その他のペイロード値タイプは無視されます。 - 現在、groupsを使用する際のページネーションはサポートされていないため、
offsetパラメータは許可されていません。
グループ内の検索
v1.3.0 以降で利用可能
同じアイテムの異なる部分で複数のポイントがある場合、格納されたデータにはしばしば冗長性が導入されます。ポイント間で共有される情報が最小限であれば、これは許容されるかもしれません。しかし、グループ内のポイント数に基づいてポイントのために必要なストレージ領域を計算するため、負荷が大きい場合に問題が発生する可能性があります。
グループを使用する場合のストレージの最適化方法は、同じグループIDに基づいてポイント間で共有される情報を別のコレクション内の単一のポイントに格納することです。そして、groups APIを使用する際に、with_lookup パラメータを追加して各グループにこの情報を追加します。
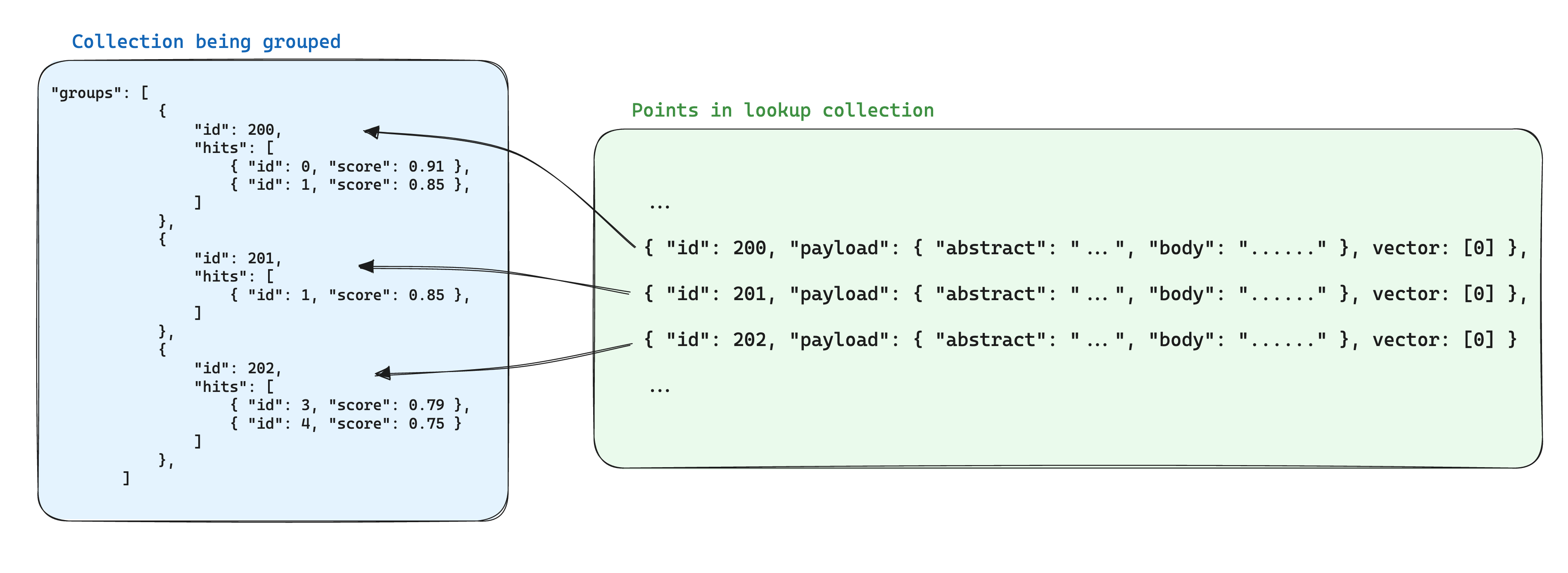
このアプローチの追加の利点は、グループ内の共有情報が変更された場合、単一のポイントのみを更新する必要があることです。
例えば、ドキュメントのコレクションがある場合、これらをチャンクに分割し、これらのチャンクに属するポイントを別のコレクションに保存し、ドキュメントに属するポイントIDがチャンクポイントのペイロードに保存されるようにすることができます。
このシナリオでは、ドキュメントから情報を取り込んで、ドキュメントIDでグループ化されたチャンクに情報を持ってくるために、with_lookup パラメータを使用することができます:
POST /collections/chunks/points/search/groups
{
// 通常の検索APIと同じパラメータ
"vector": [1.1],
...,
// グループ化パラメータ
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// 検索パラメータ
"with_lookup": {
// 検索するポイントのコレクション名
"collection": "documents",
// 検索ポイントのペイロードから取り込むコンテンツを指定するオプション、デフォルトは true
"with_payload": ["title", "text"],
// 検索ポイントのベクターから取り込むコンテンツを指定するオプション、デフォルトは true
"with_vectors": false
}
}
with_lookup パラメータでは、略記として with_lookup="documents" を使って、明示的に指定することなくペイロードとベクター全体を持ってくることも可能です。
検索結果は、各グループの下の lookup フィールドに表示されます。
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Document A",
"text": "これはドキュメントAです"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Document B",
"text": "これはドキュメントBです"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
ポイントIDを直接一致させて検索するため、存在しない(および有効でない)ポイントIDのグループIDは無視され、lookup フィールドは空になります。