ค้นหาความคล้ายคลึง
ในการประยุกต์ใช้งาน machine learning มีการค้นหาเวกเตอร์ที่ใกล้เคียงกันเป็นส่วนสำคัญ โดยโมเดิร์นเน็ตเวิร์กสมัยใหม่ถูกฝึกให้แปลงวัตถุเป็นเวกเตอร์ ทำให้วัตถุที่ใกล้เคียงกันในเวกเตอร์เชิงพื้นที่ เป็นเวกเตอร์ที่ใกล้เคียงกันในโลกแห่งความเป็นจริง เช่น ข้อความที่มีความหมายที่คล้ายกัน ภาพที่มีลักษณะทางสายตาที่คล้ายกัน หรือเพลงที่อยู่ในประเภทดนตรีเดียวกัน
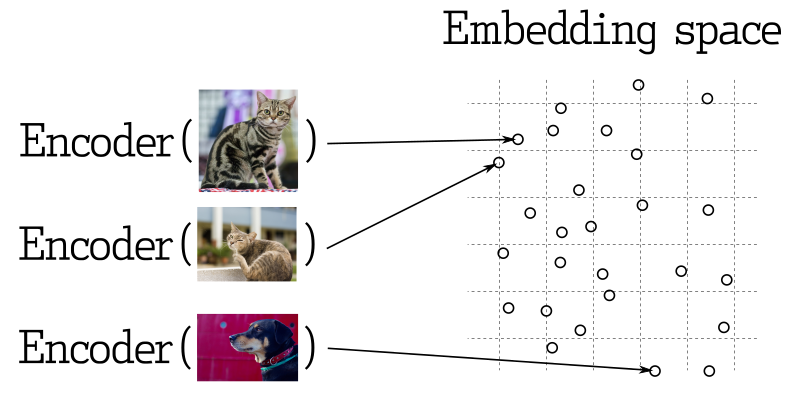
การวัดความคล้ายคลึง
มีหลายวิธีที่ใช้ในการประเมินความคล้ายคลึงระหว่างเวกเตอร์ ใน Qdrant วิธีเหล่านี้เรียกว่าการวัดความคล้ายคลึง การเลือกวัดนี้ขึ้นอยู่กับว่าเวกเตอร์ได้มาจากวิธีใดโดยเฉพาะ วิธีในการฝึกสอนประเภทของ neural network encoder
Qdrant รองรับประเภทการวัดที่เป็นที่นิยมต่อไปนี้:
- คณิตศาสตร์ดอต:
Dot - ความคล้ายคลึงโคไซน์:
Cosine - ระยะทางยูคลิด:
Euclid
วัดที่ใช้มากที่สุดในโมเดลการเรียนรู้ความคล้ายคลึง คือ การวัดคูลมิสต์
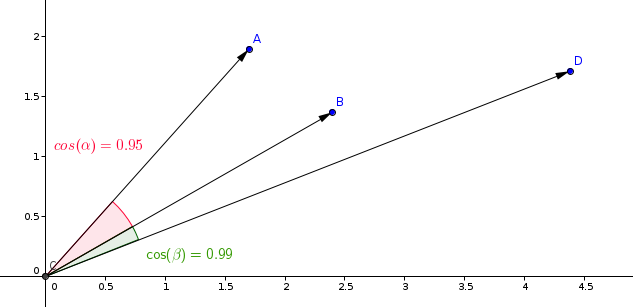
Qdrant คำนวณการวัดนี้ในขั้นตอนที่สอง ทำให้การค้นหาเป็นไปอย่างรวดเร็ว ขั้นตอนแรกคือการทำให้เวกเตอร์เป็นรูปแบบมาตรฐานเมื่อเพิ่มเข้าสู่คอลเลกชัน ทำเพียงแค่ครั้งเดียวสำหรับแต่ละเวกเตอร์
ขั้นตอนที่สองคือการเปรียบเทียบเวกเตอร์ ในกรณีนี้เทียบเท่ากับการดำเนินการดอตโปรดักตัดเพรส ด้วยเหตุนี้การทำงานเร็ว
แผนคิวรี่
ขึ้นอยู่กับตัวกรองที่ใช้ในการค้นหา มีสามสถานการณ์ที่เป็นไปได้สำหรับการดำเนินการคิวรี่ Qdrant เลือกหนึ่งในตัวเลือกดำเนินการคิวรี่ขึ้นอยู่กับดัชนีที่มีอยู่ ความซับซ้อนของเงื่อนไข และการความเป็นจำนวนของผลลัพธ์ที่ถูกกรอง กระบวนการนี้เรียกว่าแผนคิวรี่
กระบวนการเลือกกลยุทธ์พึงพอใจต่อการใช้แอลกอริทึมแบบคำนวณแบบประตูและอาจแปรผลต่างกันไปตามเวอร์ชัน อย่างไรก็ตามหลักการทั่วไปคือ:
- ดำเนินการแผนคิวรี่อิสระสำหรับแต่ละส่วน (สำหรับข้อมูลเพิ่มเติมเกี่ยวกับส่วน โปรดอ้างถึงการเก็บรักษา)
- ให้ลำดับความสำคัญในการสแกนทั้งหมดหากจำนวนจุดน้อย
- ประมาณความซับซ้อนของการกรองผลลัพธ์ก่อนเลือกกลยุทธ์
- ใช้ดัชนีพล้าย้งเพื่อเรียกคืนจุดถ้าจำนวนของผลลัพธ์ที่ถูกกรองน้อย (ดูดัชนี)
- ใช้ดัชนีเวกเตอร์ที่สามารถกรองได้ถ้าจำนวนของผลลัพธ์ที่ถูกกรองสูง
องค์ประกอบสามารถถูกปรับแต่งตามคอลเลกชันแต่ละส่วนผ่าน ไฟล์การกำหนดค่า.
ค้นหา API
เรามาดูตัวอย่างของคิวรีการค้นหากันบ้าง
REST API - คำจำกัดความของสกีมา API สามารถค้นหาได้ที่นี่ ที่นี่.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
ในตัวอย่างนี้ เรากำลังมองหาเวกเตอร์ที่คล้ายกับเวกเตอร์ [0.2, 0.1, 0.9, 0.7]. พารามิเตอร์ limit (หรือตัวย่อของมันคือ top) ระบุจำนวนผลลัพธ์ที่คล้ายกันที่เราต้องการดึงข้อมูลกลับมา.
ค่าที่อยู่ภายใต้คีย์ params ระบุพารามิเตอร์การค้นหาที่กำหนดเอง ปัจจุบันมีพารามิเตอร์ที่มีอยู่แล้วคือ:
-
hnsw_ef- ระบุค่าของพารามิเตอร์efสำหรับอัลกอริทึม HNSW -
exact- ระบุว่าจะใช้ตัวเลือกค้นหาแบบแม่น (ANN) หรือไม่ ถ้าตั้งค่าเป็น True การค้นหาอาจใช้เวลานานเนื่องจากมันทำการสแกนทั้งหมดเพื่อเอาผลลัพธ์ที่แม่นเป็นจริงออกมา -
indexed_only- การใช้ตัวเลือกนี้สามารถปิดการค้นหาในเซ็กเมนต์ที่ยังไม่ได้สร้างดัชนีเวกเตอร์ นี่อาจจะมีประโยชน์ในการลดผลกระทบต่อประสิทธิภาพการค้นหาในระหว่างการอัพเดต การใช้ตัวเลือกนี้อาจทำให้มีผลลัพธ์บางส่วนหากคอลเล็กชันยังไม่ได้สร้างดัชนีอย่างสมบูรณ์ ดังนั้นโปรดใช้เฉพาะในกรณีที่จำเป็นต้องการความสอดคล้องที่เกิดขึ้นเองที่ยอมรับได้
เนื่องจากกำหนดพารามิเตอร์ filter การค้นหาจะทำเฉพาะในจุดที่ตรงตามเงื่อนไขการกรอง สำหรับข้อมูลที่มีรายละเอียดมากขึ้นเกี่ยวกับตัวกรองที่เป็นไปได้และฟังก์ชันอาร์ติเรียได้รับกรุณาอ้างถึงส่วนของการกรอง.
ผลลัพธ์ตัวอย่างสำหรับ API นี้อาจมีลักษณะดังนี้
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result ประกอบด้วยรายการของจุดที่ค้นพบเรียงตาม score.
โปรดทราบว่าโดยค่าเริ่มต้นผลลัพธ์เหล่านี้ขาดข้อมูลแพคเก็จและเวกเตอร์ โปรดอ้างถึงส่วนข้อมูลแพคเกจและเวกเตอร์ในผลลัพธ์เพื่อดูว่าจะรวมข้อมูลแพคเกจและเวกเตอร์ไปด้วยอย่างไร
ที่มีจากเวอร์ชั่น v0.10.0
หากมีการสร้างคอลเล็กชันด้วยเวกเตอร์หลายตัว จะต้องระบุชื่อเวกเตอร์ที่จะใช้ในการค้นหาได้ด้วย:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
การค้นหาจะทำเฉพาะระหว่างเวกเตอร์ที่มีชื่อเดียวกัน
การกรองผลลัพธ์โดยคะแนน
นอกจากการกรองแพคเกจอาจมีประโยชน์ในการกรองผลลัพธ์ที่มีคะแนนความคล้ายต่ำ ตัวอย่างเช่น หากคุณทราบค่าคะแนนที่ยอมรับได้ต่ำสุดสำหรับโมเดลและไม่ต้องการผลลัพธ์ความคล้ายที่ต่ำกว่าค่าที่กำหนดไว้คุณสามารถใช้พารามิเตอร์ score_threshold สำหรับคิวรีการค้นหา มันจะทำการข้ามผลลัพธ์ทั้งหมดที่มีคะแนนต่ำกว่าค่าที่กำหนดไว้
พารามิเตอร์นี้อาจทำการข้ามทั้งผลลัพธ์ที่มีคะแนนต่ำและสูง ขึ้นอยู่กับเมตริกที่ใช้ ตัวอย่างเช่น คะแนนที่สูงในเมตริกยูคลิดเดียนถือเป็นอยู่ที่ไกลและจึงจะถูกข้ามไป
แพคเกจและเวกเตอร์ในผลลัพธ์
โดยค่าเริ่มต้นวิธีการคืนค่าไม่รวมข้อมูลที่เก็บไว้ เช่น แพคเกจและเวกเตอร์ พารามิเตอร์เพิ่มเติม with_vectors และ with_payload สามารถปรับเปลี่ยนพฤษฯนี้
ตัวอย่าง:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
พารามิเตอร์ with_payload ยังสามารถใช้เพื่อรวมหรือตัดช่องเนื้อหาที่ให้เลือก:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
ชุดคำสั่ง API สำหรับการค้นหาแบบแบทช์
มีให้ใช้ตั้งแต่ v0.10.0
ชุดคำสั่ง API สำหรับการค้นหาแบบแบทช์ ช่วยให้เราสามารถทำคำสั่งค้นหาหลาย ๆ รายการผ่านคำสั่งเดียวกัน
ซึ่งหมายถึง n คำสั่งค้นหาแบบแบทช์ ก็เท่ากับ n คำสั่งค้นหาแยกต่างหาก
วิธีการใช้งานมีความเป็นระเบียบ มีการใช้การเชื่อมต่อเครือข่ายน้อยลงทำให้กำลังความจำมีประโยชน์ในตนเอง
สำคัญอย่างดีถ้าชุดคำสั่งค้นหาแบบแบทช์มีเงื่อนไข filter เหมือนกัน แบทช์คำสั่งค้นหาจะได้รับการจัดการและการปรับปรุงอย่างมีประสิทธิภาพผ่านตัวแบนเนอร์ของคำสั่ง
มีผลที่สำคัญในการล่าสูตรสำหรับตัวกรองที่ซับซ้อน การบรรลุผลลัพธ์แก้ไขระหว่างคำสั่งได้
สำหรับการใช้งาน การแพ็คคำสั่งค้นหาไว้ด้วยกันเท่านั้น แน่นอนว่าคุณสามารถใช้คุณสมบัติคำสั่งค้นหาปกติทั้งหมด
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
ผลลัพธ์ของชุดคำสั่ง API นี้จะมีอาร์เรย์สำหรับแต่ละคำสั่งค้นหา
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
ชุดคำสั่ง API ที่แนะนำ
เวกเตอร์ลบเป็นคุณสมบัติทดลองและไม่ได้รับการรับรองว่าจะใช้ได้กับประเภทของการฝังฐานข้อมูลทุกประเภท นอกจากการค้นหาปกติ Qdrant ยังอนุญาตให้คุณค้นหาโดยใช้เวกเตอร์หลายตัวที่เก็บไว้ในคอลเล็กชั่น ชุดคำสั่งนี้ใช้สำหรับการค้นหาเวกเตอร์ของวัตถุที่เข้ารหัสโดยไม่เกี่ยวข้องกับตัวเข้ารหัสของเครือข่ายประสาทเทียม
ชุดคำสั่ง API ที่แนะนำ ช่วยให้คุณสามารถระบุเวกเตอร์บวกและเวกเตอร์ลบหลาย ๆ ตัว และบริการจะผสานพวกเขาเข้าเป็นเวกเตอร์เฉลี่ยที่เฉพาะเจาะจง
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
ถ้ามีแค่เพียงเวกเตอร์บวกเดียว คำสั่งนี้เทียบเท่ากับคำสั่งค้นหาปกติสำหรับเวกเตอร์ณจุดนั้น
ส่วนปรับแต้มของเวกเตอร์ที่มีค่ามากในเวกเตอร์ลบถูกลดลง ในขณะที่ส่วนปรับแต้มของเวกเตอร์ที่มีค่ามากในเวกเตอร์บวกถูกเพิ่มขึ้นเวกเตอร์เฉลี่ยนี้จึงถูกใช้เพื่อค้นหาเวกเตอร์ที่ใกล้เคียงที่สุดในคอลเล็กชั่น
กำหนดค่าสเกลมา ณ. ที่ 0.001
การกำหนดค่าที่ใช้สำหรับ REST API สามารถพบได้ที่นี่ ซึ่งเป็นรูปแบบของ API สำหรับคำสั่งใหม่
POST /collections/{collection_name}/point/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
อย่างนี้จะเป็นค่าผลลัพธ์ตัวอย่างของชุดคำสั่งนี้
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
มีให้ใช้ตั้งแต่ v0.10.0 ไปเป็นต้นไป
ถ้าคอลเล็กชั่นถูกสร้างขึ้นโดยใช้เวกเตอร์หลายตัว ชื่อของเวกเตอร์ที่ใช้อยู่ควรระบุในคำสั่งค้นหา:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
พารามิเตอร์ using ระบุว่าเวกเตอร์ที่เก็บไว้ควรใช้สำหรับการแนะนำ
การใช้ API แนะนำแบบ Batch
สามารถใช้ได้ตั้งแต่เวอร์ชัน v0.10.0 เป็นต้นไป
หลักการใช้ API นี้คล้ายกับ batch search API โดยสามารถประมวลผลคำขอแนะนำในรูปแบบ Batch ได้
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
ผลลัพธ์ของ API นี้จะประกอบด้วยอาร์เรย์สำหรับแต่ละคำขอแนะนำ
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
การแบ่งหน้า
สามารถใช้ได้ตั้งแต่เวอร์ชัน v0.8.3 เป็นต้นไป
API การค้นหาและแนะนำ อนุญาตให้ข้ามผลลัพธ์แรกของการค้นหาและเฉพาะคืนผลลัพธ์ที่เริ่มต้นที่ตำแหน่งเฉพาะ
ตัวอย่าง:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
นี่เทียบเท่ากับการเรียกดูหน้าที่ 11 โดยมี 10 รายการต่อหน้า
การมีค่า offset ที่สูงอาจทำให้เกิดปัญหาเรื่องประสิทธิภาพ และวิธีการดึงค่าโวเคตอร์โดยใช้วิธีการแบ่งหน้าโดยทั่วไปจะไม่สนับสนุนการค้นหาหน้า
อย่างไรก็ตาม การใช้พารามิเตอร์ offset สามารถประหยัดทรัพยากรได้โดยลดการส่งข้อมูลผ่านเครือข่ายและการเข้าถึงจัดเก็บ
เมื่อใช้พารามิเตอร์ offset จำเป็นต้องดึงข้อมูลภายในจากจะกี่จุด offset + limit แต่สามารถเข้าถึงข้อมูล payload และเวกเตอร์ของจุดเหล่านั้นที่จริงจากการจัดเก็บได้เท่านั้น
การจัดกลุ่ม API
มีจำหน่ายตั้งแต่เวอร์ชัน v1.2.0
ผลลัพธ์สามารถจัดกลุ่มตามฟิลด์ที่กำหนดได้ ซึ่งมีประโยชน์มากเมื่อคุณมีจุดหลายๆ จุดสำหรับรายการเดียวกันและต้องการหลีกเลี่ยงการส่งผลที่ไม่จำเป็นในผลลัพธ์
ตัวอย่างเช่น หากคุณมีเอกสารขนาดใหญ่ที่แบ่งเป็นชิ้นเล็กๆ และต้องการค้นหาหรือแนะนำโดยใช้เอกสารแต่ละชิ้น คุณสามารถจัดกลุ่มผลลัพธ์ตาม ID เอกสารได้
สมมติว่ามีจุดที่มี payload ดังนี้:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
โดยใช้ groups API, คุณจะสามารถเรียกดูจุด N อันดับสูงสุดสำหรับแต่ละเอกสาร โดยสมมติว่า payload ของจุดนั้น ๆ มี ID ของเอกสาร เพื่อให้การค้นหาบ่งชี้ถึงสถานการณ์ที่อันตรายสะสมและระยะทางที่ใหญ่จากการค้นหา
การค้นหาแบบกลุ่ม
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// เหมือนกับ regular search API
"vector": [1.1],
...,
// พารามิเตอร์ในการจัดกลุ่ม
"group_by": "document_id", // ทางอย่างผ่านฟิลด์ที่จะจัดกลุ่ม
"limit": 4, // จำนวนสูงสุดของกลุ่ม
"group_size": 2, // จำนวนสูงสุดของจุดต่อกลุ่ม
}
การแนะนำกลุ่ม
REST API (Schema):
POST /collections/{collection_name}/points/recommend/groups
{
// เหมือนกับ API แนะนำทั่วไป
"negative": [1],
"positive": [2, 5],
...,
// พารามิเตอร์สำหรับการจัดกลุ่ม
"group_by": "document_id", // พาธของฟิลด์ที่ใช้สำหรับการจัดกลุ่ม
"limit": 4, // จำนวนสูงสุดของกลุ่ม
"group_size": 2, // จำนวนสูงสุดของจุดต่อกลุ่ม
}
ไม่ว่าเป็นการค้นหาหรือการแนะนำ ผลลัพธ์ที่ได้จะมีดังนี้:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
กลุ่มถูกเรียงตามคะแนนสูงสุดของจุดภายในแต่ละกลุ่ม ภายในแต่ละกลุ่ม จุดยังถูกเรียงลำดับด้วย
หากฟิลด์ group_by ของจุดเป็นอาร์เรย์ (เช่น "document_id": ["a", "b"]), จุดสามารถถูกรวมอยู่ในกลุ่มหลายๆ กลุ่ม (เช่น "document_id": "a" และ document_id: "b")
ฟังก์ชันนี้อาศัยอย่างยิ่งไปที่คีย์ group_by ที่ถูกส่งมา สำหรับการปรับปรุงประสิทธิภาพ ระวังให้สร้างดัชนีที่ประสบการณ์กันเพื่อการปรับปรุงประสิทธิภาพ ข้อจำกัด:
- พารามิเตอร์
group_byเฉพาะรองรับค่าพาหะและจำนวนเต็ม payload values เท่านั้น ค่าอื่นๆ จะถูกละเลย - ปัจจุบัน การแบ่งหน้า (pagination) ไม่ได้รับการสนับสนุนเมื่อใช้ กลุ่ม ดังนั้นพารามิเตอร์
offsetไม่ได้รับอนุญาต
การค้นหาภายในกลุ่ม
สามารถใช้ได้ตั้งแต่ v1.3.0
ในกรณีที่มีจุดหลายจุดสำหรับส่วนต่าง ๆ ของรายการเดียวกัน การซ้ำซ้อนมักจะเกิดขึ้นในข้อมูลที่เก็บไว้ หากข้อมูลที่ใช้ร่วมกันระหว่างจุดน้อยมาก นี่อาจเป็นไปได้ แต่มันอาจกลายเป็นปัญหาเมื่อมีโหลดที่หนัก เนื่องจากมันจะคำนวณพื้นที่จัดเก็บที่จำเป็นสำหรับจุดตามจำนวนของจุดในกลุ่ม
การปรับปรุงเพื่อจัดเก็บเมื่อใช้กลุ่มคือการเก็บข้อมูลที่ใช้ร่วมกันระหว่างจุดตาม ID กลุ่มเดียวกันในจุดเดียวภายในคอลเล็กชันอื่น ๆ จากนั้น เมื่อใช้ groups API ให้เพิ่มพารามิเตอร์ with_lookup เพื่อเพิ่มข้อมูลนี้สำหรับแต่ละกลุ่ม
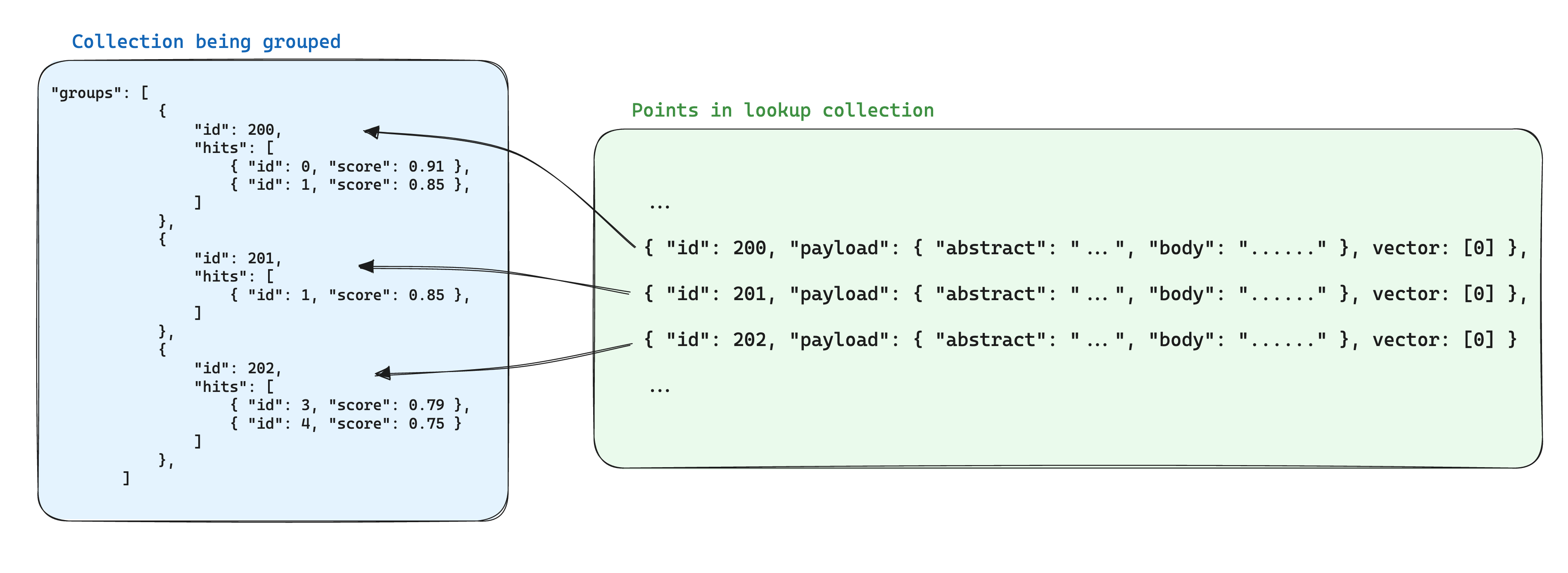
ประโยชน์เพิ่มเติมของวิธีนี้คือเมื่อข้อมูลที่ใช้ร่วมกันในจุดกลุ่มเปลี่ยนแปลง จะต้องอัปเดตเพียงจุดเดียวเท่านั้น
เช่น หากคุณมีคอลเล็กชันของเอกสาร คุณอาจต้องการแบ่งชิ้นข้อมูลและจัดเก็บจุดที่เป็นของชิ้นเหล่านี้ในคอลเล็กชันเฉพาะ โดยให้แน่ใจว่า ID ของจุดที่เป็นของเอกสารถูกเก็บไว้ใน payload ของจุดชิ้น
ในกรณีนี้ ในการนำข้อมูลจากเอกสารมาในชิ้นที่จัดกลุ่มโดย ID ของเอกสาร สามารถใช้พารามิเตอร์ with_lookup ได้:
POST /collections/chunks/points/search/groups
{
// พารามิเตอร์เดียวกับที่ใน regular search API
"vector": [1.1],
...,
// พารามิเตอร์ในการจัดกลุ่ม
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// พารามิเตอร์การค้นหา
"with_lookup": {
// ชื่อคอลเล็กชันของจุดที่ต้องการค้นหา
"collection": "documents",
// ตัวเลือกที่ระบุเนื้อหาที่ต้องการเข้ามาจาก payload ของจุดที่ค้นหา, ค่าเริ่มต้นคือ true
"with_payload": ["title", "text"],
// ตัวเลือกที่ระบุเนื้อหาที่ต้องการเข้ามาจากเวกเตอร์ของจุดที่ค้นหา, ค่าเริ่มต้นคือ true
"with_vectors": false
}
}
สำหรับพารามิเตอร์ with_lookup, สามารถใช้ with_lookup="documents" เพื่อเข้าถึง payload และเวกเตอร์โดยไม่ต้องระบุโดยชัดเจน
ผลลัพธ์การค้นหาจะถูกแสดงในฟิลด์ lookup ภายใต้แต่ละกลุ่ม
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "เอกสาร A",
"text": "นี่คือเอกสาร A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "เอกสาร B",
"text": "นี่คือเอกสาร B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
เนื่องจากการค้นหาทำโดยการจับคู่ ID จุดโดยตรง กลุ่ม ID ที่ไม่มีอยู่ (และ ID จุดที่ถูกต้อง) จะถูกละเว้น และฟิลด์ lookup จะเป็นว่างเปล่า