Ähnlichkeitssuche
In vielen Anwendungen des maschinellen Lernens ist die Suche nach den nächsten Vektoren ein zentraler Bestandteil. Moderne neuronale Netzwerke werden darauf trainiert, Objekte in Vektoren zu transformieren, wodurch Objekte, die im Vektorraum nahe beieinander liegen, auch in der realen Welt nah beieinander liegen. Zum Beispiel Texte mit ähnlicher Bedeutung, visuell ähnliche Bilder oder Lieder, die demselben Genre angehören.
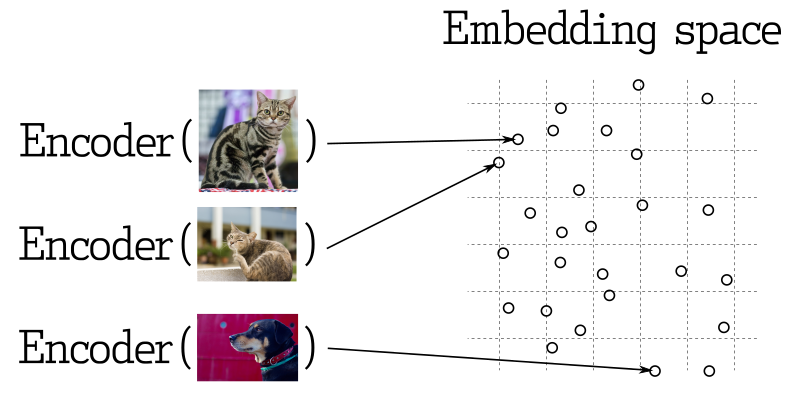
Ähnlichkeitsmessung
Es gibt viele Methoden, um die Ähnlichkeit zwischen Vektoren zu bewerten. In Qdrant werden diese Methoden als Ähnlichkeitsmessungen bezeichnet. Die Wahl der Messung hängt davon ab, wie die Vektoren erhalten werden, insbesondere von der Methode, die zur Schulung des neuronalen Netzwerkencoders verwendet wird.
Qdrant unterstützt die folgenden gängigsten Arten von Messungen:
- Skalarprodukt:
Skalar - Kosinusähnlichkeit:
Kosinus - Euklidischer Abstand:
Euklidisch
Die am häufigsten verwendete Messung in Ähnlichkeitslernmodellen ist die Kosinusmessung.
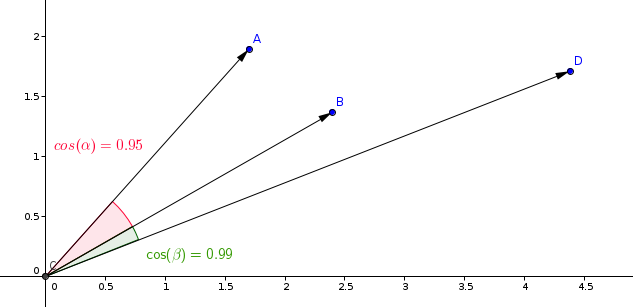
Qdrant berechnet diese Messung in zwei Schritten, um höhere Suchgeschwindigkeiten zu erzielen. Der erste Schritt besteht darin, die Vektoren zu normalisieren, wenn sie der Sammlung hinzugefügt werden. Dies geschieht nur einmal für jeden Vektor.
Der zweite Schritt ist der Vektorenvergleich. In diesem Fall entspricht dies einer Skalarproduktoperation aufgrund der schnellen SIMD-Operationen.
Abfrageplan
Je nach den in der Suche verwendeten Filtern gibt es mehrere mögliche Szenarien für die Abfrageausführung. Qdrant wählt eine der Abfrageausführungsoptionen auf der Grundlage verfügbarer Indizes, der Komplexität der Bedingungen und der Kardinalität der gefilterten Ergebnisse aus. Dieser Vorgang wird als Abfrageplanung bezeichnet.
Der Strategieauswahlprozess stützt sich auf heuristische Algorithmen und kann je nach Version variieren. Die allgemeinen Prinzipien sind jedoch:
- Führen Sie Abfragepläne unabhängig für jeden Segment aus (für detaillierte Informationen zu Segmenten siehe Speicher).
- Priorisieren Sie Vollscans, wenn die Anzahl der Punkte niedrig ist.
- Schätzen Sie die Kardinalität der gefilterten Ergebnisse, bevor Sie eine Strategie auswählen.
- Verwenden Sie Payload-Indizes, um Punkte abzurufen, wenn die Kardinalität niedrig ist (siehe Indizes).
- Verwenden Sie filterbare Vektorindizes, wenn die Kardinalität hoch ist.
Die Schwellenwerte können unabhängig für jede Sammlung durch die Konfigurationsdatei angepasst werden.
Such-API
Lassen Sie uns ein Beispiel für eine Suchanfrage ansehen.
REST API - API-Schemadefinitionen finden Sie hier.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
In diesem Beispiel suchen wir nach Vektoren, die ähnlich dem Vektor [0.2, 0.1, 0.9, 0.7] sind. Der Parameter limit (oder sein Alias top) legt die Anzahl der ähnlichsten Ergebnisse fest, die wir abrufen möchten.
Die Werte unter dem Schlüssel params geben benutzerdefinierte Suchparameter an. Die derzeit verfügbaren Parameter sind:
-
hnsw_ef- legt den Wert des Parameterseffür den HNSW-Algorithmus fest. -
exact- legt fest, ob die exakte (ANN) Suchoption verwendet werden soll. Wenn auf True gesetzt, kann die Suche lange dauern, da sie einen vollständigen Scan durchführt, um exakte Ergebnisse zu erhalten. -
indexed_only- Durch die Verwendung dieser Option kann die Suche in Segmente, die noch keinen Vektorindex aufgebaut haben, deaktiviert werden. Dies kann dazu beitragen, die Auswirkungen auf die Suchleistung während Updates zu minimieren. Die Verwendung dieser Option kann zu teilweisen Ergebnissen führen, wenn die Sammlung noch nicht vollständig indiziert ist, daher sollte sie nur in Fällen verwendet werden, in denen eine akzeptable eventuelle Konsistenz erforderlich ist.
Da der filter-Parameter angegeben ist, wird die Suche nur unter Punkten durchgeführt, die den Filterkriterien entsprechen. Für genauere Informationen über mögliche Filter und deren Funktionalitäten, siehe den Abschnitt Filter.
Ein Beispielergebnis für diese API könnte so aussehen:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Das result enthält eine Liste der entdeckten Punkte, sortiert nach score.
Bitte beachten Sie, dass diese Ergebnisse standardmäßig keine Nutzlast- und Vektorinformationen enthalten. Siehe den Abschnitt Nutzlast und Vektor in Ergebnissen, um Informationen darüber zu erhalten, wie Nutzlasten und Vektoren in den Ergebnissen eingeschlossen werden können.
Verfügbar ab Version v0.10.0
Wenn eine Sammlung mit mehreren Vektoren erstellt wird, sollte der Name des Vektors, der für die Suche verwendet werden soll, angegeben werden:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
Die Suche wird nur zwischen Vektoren mit demselben Namen durchgeführt.
Ergebnisse nach Score filtern
Zusätzlich zur Nutzlastfilterung kann es auch nützlich sein, Ergebnisse mit niedrigen Ähnlichkeitswerten herauszufiltern. Zum Beispiel, wenn Sie den minimal akzeptablen Wert für einen Modell-Score kennen und keine Ähnlichkeitsergebnisse unterhalb des Schwellenwerts wünschen, können Sie den Parameter score_threshold für die Suchanfrage verwenden. Er schließt alle Ergebnisse aus, deren Score niedriger als der angegebene Wert ist.
Dieser Parameter kann je nach verwendeter Metrik sowohl niedrigere als auch höhere Scores ausschließen. Zum Beispiel werden höhere Scores in der euklidischen Metrik als weiter entfernt betrachtet und daher ausgeschlossen.
Nutzlast und Vektoren in Ergebnissen
Standardmäßig liefert die Abrufmethode keine gespeicherten Informationen wie Nutzlast und Vektoren zurück. Zusätzliche Parameter with_vectors und with_payload können dieses Verhalten ändern.
Beispiel:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
Der Parameter with_payload kann auch verwendet werden, um bestimmte Felder einzuschließen oder auszuschließen:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Batch Suche API
Verfügbar ab v0.10.0
Die Batch Suche API ermöglicht die Ausführung mehrerer Suchanfragen über eine einzelne Anfrage.
Die Semantik ist einfach, n Batch-Suchanfragen sind äquivalent zu n separaten Suchanfragen.
Diese Methode hat mehrere Vorteile. Logischerweise erfordert sie weniger Netzwerkverbindungen, was an sich vorteilhaft ist.
Vor allem, wenn die Batch-Anfragen denselben Filter haben, wird die Batch-Anfrage effizient und optimiert durch den Abfrageplaner behandelt.
Dies hat einen erheblichen Einfluss auf die Latenz bei nicht trivialen Filtern, da Zwischenergebnisse zwischen Anfragen gemeinsam genutzt werden können.
Um sie zu verwenden, verpacken Sie einfach Ihre Suchanfragen zusammen. Natürlich sind alle regulären Attributen der Suchanfrage verfügbar.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Die Ergebnisse dieser API enthalten ein Array für jede Suchanfrage.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Empfohlene API
Der negative Vektor ist ein experimentelles Feature und es wird nicht garantiert, dass er mit allen Arten von Einbettungen funktioniert. Neben regulären Suchen erlaubt Qdrant auch die Suche basierend auf mehreren bereits in einer Sammlung gespeicherten Vektoren. Diese API wird für die Vektorsuche von codierten Objekten ohne Beteiligung von neuronalen Netzwerk-Encodern verwendet.
Die Empfohlene API ermöglicht es Ihnen, mehrere positive und negative Vektor-IDs anzugeben, und der Service wird diese zu einem spezifischen Durchschnittsvektor zusammenführen.
durchschnittlicher_vektor = avg(positive_vektoren) + ( avg(positive_vektoren) - avg(negative_vektoren) )
Wenn nur eine positive ID bereitgestellt wird, ist diese Anfrage äquivalent zu einer regulären Suche nach dem Vektor an diesem Punkt.
Komponenten des Vektors mit größeren Werten im negativen Vektor werden bestraft, während Komponenten des Vektors mit größeren Werten im positiven Vektor verstärkt werden. Dieser Durchschnittsvektor wird dann verwendet, um die ähnlichsten Vektoren in der Sammlung zu finden.
Die API-Schemadefinition für die REST-API finden Sie hier.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
Das Beispielergebnis für diese API lautet wie folgt:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Verfügbar ab v0.10.0 und später
Wenn die Sammlung mit mehreren Vektoren erstellt wird, müssen die Namen der verwendeten Vektoren in der Empfehlungsanfrage angegeben werden:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
Der Parameter using gibt den gespeicherten Vektor an, der für die Empfehlung verwendet werden soll.
Batch Empfohlene API
Verfügbar ab v0.10.0
Ähnlich wie die Batch-Such-API, mit ähnlicher Verwendung und ähnlichen Vorteilen, können Empfehlungsanfragen in Chargen verarbeitet werden.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
Das Ergebnis dieses API enthält ein Array für jede Empfehlungsanfrage.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Paginierung
Verfügbar ab Version v0.8.3
Die Such- und Empfehlungs-API ermöglicht das Überspringen der ersten Ergebnisse der Suche und liefert nur Ergebnisse ab einem bestimmten Offset.
Beispiel:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Dies entspricht dem Abrufen der 11. Seite mit jeweils 10 Datensätzen pro Seite.
Ein hoher Offset-Wert kann zu Leistungsproblemen führen, und die vektorbasierte Abrufmethode unterstützt in der Regel keine Paginierung. Ohne das Abrufen der ersten N Vektoren ist es nicht möglich, den N-ten nächsten Vektor abzurufen.
Die Verwendung des Offset-Parameters kann jedoch Ressourcen sparen, indem der Netzwerkverkehr und der Zugriff auf den Speicher reduziert werden.
Bei Verwendung des offset-Parameters ist es erforderlich, intern offset + limit Punkte abzurufen, jedoch nur auf die Nutzlast und Vektoren dieser Punkte zuzugreifen, die tatsächlich aus dem Speicher zurückgegeben werden.
Gruppierung API
Verfügbar ab Version v1.2.0
Ergebnisse können basierend auf einem bestimmten Feld gruppiert werden. Dies ist sehr nützlich, wenn Sie mehrere Punkte für dasselbe Element haben und redundanten Einträgen in den Ergebnissen vermeiden möchten.
Beispielsweise, wenn Sie ein großes Dokument in mehrere Abschnitte unterteilt haben und basierend auf jedem Dokument nachsuchen oder Empfehlungen abgeben möchten, können Sie die Ergebnisse nach der Dokumenten-ID gruppieren.
Angenommen, es gibt Punkte mit Nutzlasten:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Mit der groups API können Sie die top N Punkte für jedes Dokument abrufen, vorausgesetzt, dass die Nutzlast des Punktes die Dokumenten-ID enthält. Natürlich kann es Fälle geben, in denen die besten N Punkte aufgrund von Punktemangel oder relativ großer Entfernung von der Abfrage nicht erfüllt werden können. In jedem Fall ist group_size ein Best-Effort-Parameter, ähnlich dem limit-Parameter.
Gruppensuche
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// Gleich wie die reguläre Such-API
"vector": [1.1],
...,
// Gruppierungsparameter
"group_by": "document_id", // Der Feldpfad, nach dem gruppiert wird
"limit": 4, // Maximale Anzahl von Gruppen
"group_size": 2, // Maximale Anzahl von Punkten pro Gruppe
}
Gruppenempfehlung
REST-API (Schema):
POST /collections/{collection_name}/points/recommend/groups
{
// Gleich wie bei der regulären Empfehlungs-API
"negative": [1],
"positive": [2, 5],
...,
// Gruppierungsparameter
"group_by": "document_id", // Der Feldpfad nach dem gruppiert werden soll
"limit": 4, // Maximale Anzahl an Gruppen
"group_size": 2, // Maximale Anzahl an Punkten pro Gruppe
}
Unabhängig davon, ob es sich um eine Suche oder eine Empfehlung handelt, lauten die Ausgabenergebnisse wie folgt:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
Die Gruppen werden nach der höchsten Punktzahl der Punkte innerhalb jeder Gruppe sortiert. Innerhalb jeder Gruppe sind die Punkte ebenfalls sortiert.
Wenn das group_by-Feld eines Punktes ein Array ist (z. B. "document_id": ["a", "b"]), kann der Punkt in mehreren Gruppen enthalten sein (z. B. "document_id": "a" und document_id: "b").
Diese Funktionalität hängt stark von dem bereitgestellten group_by-Schlüssel ab. Zur Verbesserung der Leistung stellen Sie sicher, dass dafür ein dedizierter Index erstellt wird. Einschränkungen:
- Der Parameter
group_byunterstützt nur die Payload-Werttypen Keyword und Integer. Andere Payload-Werttypen werden ignoriert. - Derzeit wird die Paginierung nicht unterstützt, wenn Gruppen verwendet werden. Der Parameter
offsetist nicht erlaubt.
Suche innerhalb von Gruppen
Verfügbar seit v1.3.0
In Fällen, in denen es mehrere Punkte für verschiedene Teile desselben Elements gibt, wird häufig Redundanz in den gespeicherten Daten eingeführt. Wenn die gemeinsamen Informationen zwischen den Punkten minimal sind, kann dies akzeptabel sein. Es kann jedoch bei größeren Lasten problematisch werden, da der Speicherplatzbedarf für die Punkte auf der Anzahl der Punkte in der Gruppe basiert.
Eine Optimierung für die Speicherung bei Verwendung von Gruppen besteht darin, die gemeinsamen Informationen zwischen Punkten basierend auf derselben Gruppen-ID in einem einzelnen Punkt innerhalb einer anderen Sammlung zu speichern. Dann kann bei Verwendung der Gruppen-API das with_lookup-Parameter hinzugefügt werden, um diese Informationen für jede Gruppe hinzuzufügen.
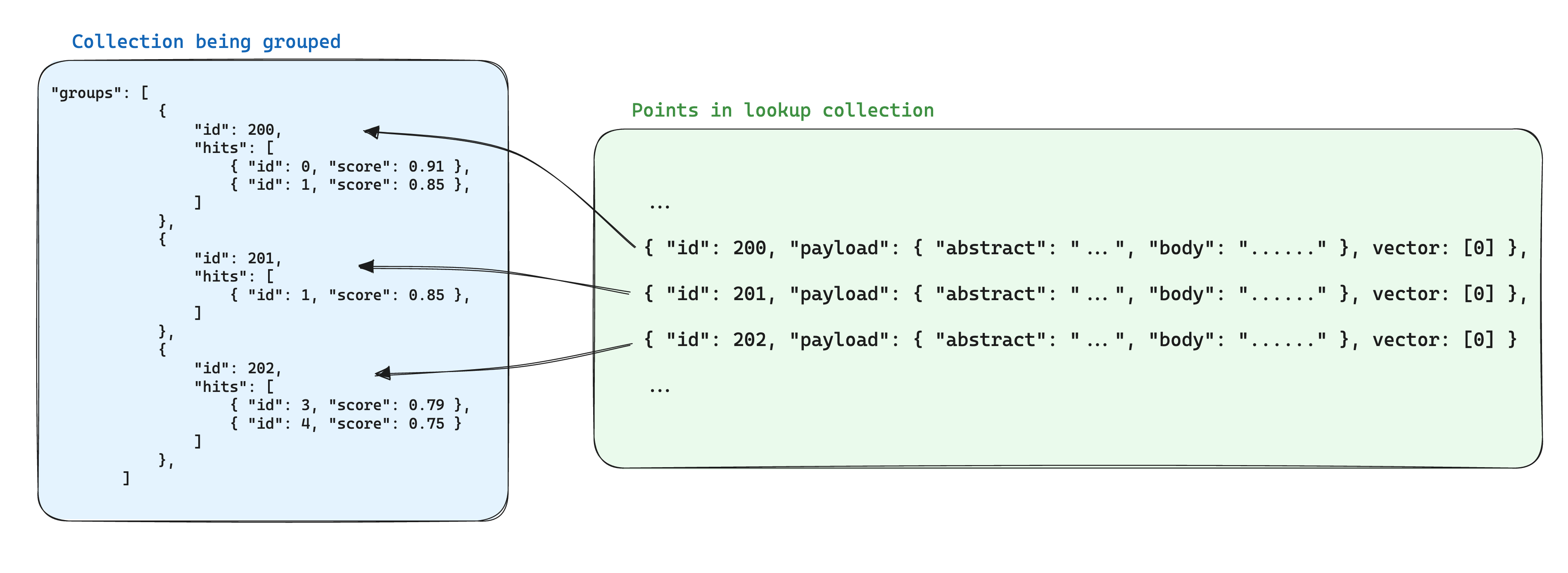
Ein zusätzlicher Vorteil dieses Ansatzes ist, dass bei Änderungen der gemeinsamen Informationen innerhalb der Gruppenpunkte nur der einzelne Punkt aktualisiert werden muss.
Wenn Sie beispielsweise eine Sammlung von Dokumenten haben, möchten Sie sie möglicherweise aufteilen und die Punkte, die zu diesen Abschnitten gehören, in einer separaten Sammlung speichern, um sicherzustellen, dass die zu den Dokumenten gehörenden Punkte-IDs in der Nutzlast des Abschnittspunkts gespeichert sind.
In diesem Szenario kann der with_lookup-Parameter verwendet werden, um die Informationen aus den Dokumenten in die nach Dokumenten-ID gruppierten Abschnitte zu bringen:
POST /collections/chunks/points/search/groups
{
// Gleiche Parameter wie in der regulären Such-API
"Vektor": [1.1],
...,
// Gruppierungsparameter
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Suchparameter
"with_lookup": {
// Name der Sammlung der zu durchsuchenden Punkte
"Sammlung": "Dokumente",
// Optionen, die den Inhalt aus der Nutzlast der zu suchenden Punkte bringen, Standard ist true
"with_payload": ["Titel", "Text"],
// Optionen, die den Inhalt aus den Vektoren der zu suchenden Punkte bringen, Standard ist true
"with_vectors": false
}
}
Für den with_lookup-Parameter kann auch ein Kurzzeichen with_lookup="Dokumente" verwendet werden, um die gesamte Nutzlast und Vektoren ohne explizite Angabe einzubringen.
Die Suchergebnisse werden im Feld lookup unter jeder Gruppe angezeigt.
{
"Ergebnis": {
"Gruppen": [
{
"id": 1,
"Treffer": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"Titel": "Dokument A",
"Text": "Das ist Dokument A"
}
}
},
{
"id": 2,
"Treffer": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"Titel": "Dokument B",
"Text": "Das ist Dokument B"
}
}
}
]
},
"Status": "ok",
"Zeit": 0.001
}
Da die Suche durch direktes Abgleichen der Punkt-IDs erfolgt, werden Gruppen-IDs, die keine vorhandenen (und gültigen) Punkt-IDs sind, ignoriert, und das lookup-Feld bleibt leer.