Tìm kiếm tương đồng
Trong nhiều ứng dụng học máy, việc tìm kiếm các vectors gần nhất là một phần cốt lõi. Các mạng nơ-ron hiện đại được huấn luyện để biến đổi đối tượng thành vectors, làm cho các đối tượng gần nhau trong không gian vector cũng gần nhau trong thế giới thực. Ví dụ, văn bản có ý nghĩa tương tự, hình ảnh tương tự về mặt hình thức, hoặc các bài hát thuộc cùng thể loại.
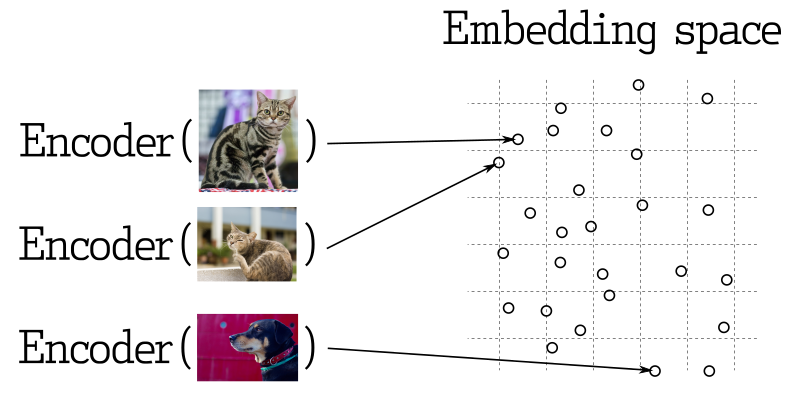
Đo lường sự tương đồng
Có nhiều phương pháp để đánh giá sự tương đồng giữa các vectors. Trong Qdrant, những phương pháp này được gọi là đo lường sự tương đồng. Lựa chọn của phương pháp phụ thuộc vào cách các vectors được thu được, đặc biệt là phương pháp sử dụng để huấn luyện bộ mã hóa mạng nơ-ron.
Qdrant hỗ trợ các loại đo lường sau đây phổ biến nhất:
- Tích vô hướng:
Dot - Tương đồng cosin:
Cosine - Khoảng cách Euclidean:
Euclid
Phương pháp đo lường phổ biến nhất trong các mô hình học tương đồng là đo lường cosin.
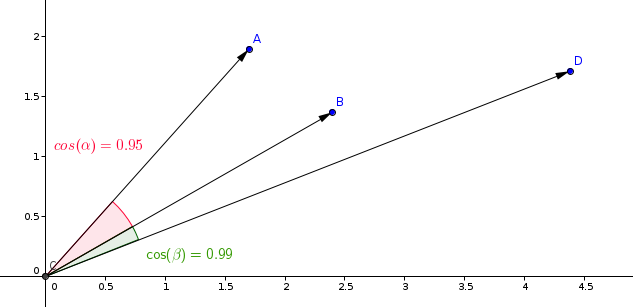
Qdrant tính toán đo lường này trong hai bước, từ đó đạt được tốc độ tìm kiếm cao hơn. Bước đầu tiên là chuẩn hóa các vectors khi thêm chúng vào bộ sưu tập. Điều này chỉ thực hiện một lần cho mỗi vector.
Bước thứ hai là so sánh vector. Trong trường hợp này, nó tương đương với một phép tính tích vô hướng, do các phép tính SIMD nhanh chóng.
Kế hoạch truy vấn
Tùy thuộc vào các bộ lọc được sử dụng trong tìm kiếm, có một số kịch bản truy vấn thực hiện có thể. Qdrant chọn một trong các tùy chọn thực hiện truy vấn dựa trên các chỉ số có sẵn, độ phức tạp của điều kiện và độ lớn của kết quả được lọc. Quá trình này được gọi là lập kế hoạch truy vấn.
Quá trình lựa chọn chiến lược dựa trên các thuật toán heuristic và có thể thay đổi theo phiên bản. Tuy nhiên, các nguyên tắc chung là:
- Thực hiện các kế hoạch truy vấn độc lập cho mỗi đoạn (để biết thông tin chi tiết về các đoạn, vui lòng tham khảo storage).
- Ưu tiên quét đầy đủ nếu số lượng điểm thấp.
- Ước lượng độ lớn của kết quả lọc trước khi chọn một chiến lược.
- Sử dụng chỉ số payload để truy xuất các điểm nếu độ lớn là thấp (xem chỉ số).
- Sử dụng chỉ số vector có thể lọc nếu độ lớn là cao.
Ngưỡng có thể được điều chỉnh độc lập cho mỗi bộ sưu tập thông qua tệp cấu hình.
Tìm kiếm API
Hãy xem xét một ví dụ về một truy vấn tìm kiếm.
REST API - Định nghĩa lược đồ API có thể được tìm thấy tại đây.
POST /collections/{tên_bộ_sưu_tập}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
Trong ví dụ này, chúng ta đang tìm kiếm các vector tương tự với vector [0.2, 0.1, 0.9, 0.7]. Tham số limit (hoặc bí danh của nó top) chỉ định số lượng kết quả tương tự nhất mà chúng ta muốn lấy về.
Các giá trị dưới khóa params chỉ định các tham số tìm kiếm tùy chỉnh. Các tham số hiện tại có sẵn là:
-
hnsw_ef- chỉ định giá trị của tham sốefcho thuật toán HNSW. -
exact- xác định liệu có sử dụng tùy chọn tìm kiếm chính xác (ANN) hay không. Nếu được đặt thành True, việc tìm kiếm có thể mất thời gian lâu vì nó thực hiện quét hoàn toàn để đạt được kết quả chính xác. -
indexed_only- sử dụng tùy chọn này có thể vô hiệu hóa việc tìm kiếm trong các đoạn chưa xây dựng chỉ mục vector. Điều này có thể hữu ích để làm giảm tác động đến hiệu suất tìm kiếm trong quá trình cập nhật. Sử dụng tùy chọn này có thể dẫn đến kết quả một phần nếu bộ sưu tập chưa được xác định chỉ mục hoàn toàn, vì vậy hãy sử dụng nó chỉ trong các trường hợp cần phải chấp nhận tính nhất quán cuối cùng.
Khi tham số filter được chỉ định, tìm kiếm chỉ được thực hiện giữa các điểm đáp ứng các tiêu chí lọc. Để biết thông tin chi tiết hơn về các bộ lọc có thể và chức năng của chúng, vui lòng tham khảo phần Bộ lọc.
Một kết quả mẫu cho API này có thể trông như sau:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result chứa một danh sách các điểm phát hiện được được sắp xếp theo score.
Vui lòng lưu ý rằng mặc định, các kết quả này không có dữ liệu payload và vector. Tham khảo phần Payload và Vector trong Kết quả để biết cách bao gồm payload và vectors trong kết quả.
Có từ phiên bản v0.10.0 trở lên
Nếu một bộ sưu tập được tạo ra với nhiều vector, tên của vector sẽ được sử dụng để tìm kiếm:
POST /collections/{tên_bộ_sưu_tập}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
Tìm kiếm chỉ được thực hiện giữa các vector có cùng tên.
Lọc Kết quả theo Điểm
Ngoài việc lọc payload, cũng có thể hữu ích để loại bỏ kết quả có điểm tương tự thấp. Ví dụ, nếu bạn biết điểm chấp nhận được tối thiểu cho một mô hình và không muốn bất kỳ kết quả tương tự nào dưới ngưỡng, bạn có thể sử dụng tham số score_threshold cho truy vấn tìm kiếm. Nó sẽ loại trừ tất cả các kết quả có điểm thấp hơn giá trị cho trước.
Tham số này có thể loại bỏ cả điểm thấp và điểm cao, tùy thuộc vào phép đo sử dụng. Ví dụ, điểm cao trong đo lường Euclidean được coi là xa cách và do đó sẽ bị loại trừ.
Payload và Vector trong Kết quả
Mặc định, phương thức truy xuất không trả về bất kỳ thông tin nào được lưu trữ, chẳng hạn như payload và vectors. Các tham số bổ sung with_vectors và with_payload có thể sửa đổi hành vi này.
Ví dụ:
POST /collections/{tên_bộ_sưu_tập}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
Tham số with_payload cũng có thể được sử dụng để bao gồm hoặc loại bỏ các trường cụ thể:
POST /collections/{tên_bộ_sưu_tập}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Batch Search API
Khả dụng từ phiên bản v0.10.0
Batch search API cho phép thực hiện nhiều yêu cầu tìm kiếm thông qua một yêu cầu duy nhất.
Ý nghĩa của nó đơn giản, n yêu cầu tìm kiếm theo lô tương đương với n yêu cầu tìm kiếm riêng biệt.
Phương pháp này có một số ưu điểm. Logic, nó chỉ yêu cầu ít kết nối mạng hơn, điều này đã có lợi.
Quan trọng hơn, nếu các yêu cầu lô có cùng bộ lọc, yêu cầu lô sẽ được xử lý một cách hiệu quả và tối ưu thông qua trình lập kế hoạch truy vấn.
Điều này ảnh hưởng đáng kể đến thời gian trễ đối với các bộ lọc không đơn giản, vì kết quả trung gian có thể được chia sẻ giữa các yêu cầu.
Để sử dụng nó, đơn giản là gói các yêu cầu tìm kiếm của bạn cùng nhau. Tất nhiên, tất cả các thuộc tính yêu cầu tìm kiếm thông thường đều có sẵn.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Kết quả của API này chứa một mảng cho mỗi yêu cầu tìm kiếm.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
API Tiếp Theo Được Khuyến Nghị
Vector âm là một tính năng thử nghiệm và không được đảm bảo hoạt động với tất cả các loại nhúng. Ngoài các tìm kiếm thông thường, Qdrant cũng cho phép bạn tìm kiếm dựa trên nhiều vector đã được lưu trữ trong một bộ sưu tập. API này được sử dụng cho tìm kiếm vector của các đối tượng mã hóa mà không cần sự tham gia của máy mã hóa mạng nơ-ron.
API Được Khuyến Nghị cho phép bạn xác định nhiều ID vector dương và âm, và dịch vụ sẽ kết hợp chúng thành một vector trung bình cụ thể.
vector_trung_bình = trung_bình(vector_dương) + ( trung_bình(vector_dương) - trung_bình(vector_âm) )
Nếu chỉ cung cấp một ID dương, yêu cầu này tương đương với một tìm kiếm thông thường cho vector tại điểm đó.
Các thành phần vector với giá trị lớn trong vector âm sẽ bị xử phạt, trong khi các thành phần vector với giá trị lớn trong vector dương sẽ được tăng cường. Vector trung bình này sau đó được sử dụng để tìm ra các vector tương tự nhất trong bộ sưu tập.
Định nghĩa lược đồ API cho REST API có thể được tìm thấy tại đây.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
Kết quả mẫu cho API này sẽ như sau:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Khả dụng từ phiên bản v0.10.0 trở đi
Nếu bộ sưu tập được tạo bằng nhiều vector, tên của các vector đang được sử dụng phải được chỉ định trong yêu cầu khuyến nghị:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
Tham số using chỉ định vector đã được lưu trữ sẽ được sử dụng cho khuyến nghị.
Gợi ý API Thành Lô
Có sẵn từ phiên bản v0.10.0 trở lên
Tương tự như API tìm kiếm theo lô, với cách sử dụng và lợi ích tương tự, nó có thể xử lý các yêu cầu gợi ý theo lô.
POST /collections/{tên_bộ_sưu_tập}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
Kết quả của API này chứa một mảng cho mỗi yêu cầu gợi ý.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Phân trang
Có sẵn từ phiên bản v0.8.3 trở lên
API tìm kiếm và gợi ý cho phép bỏ qua một số kết quả đầu tiên của tìm kiếm và chỉ trả về kết quả bắt đầu từ một vị trí cụ thể.
Ví dụ:
POST /collections/{tên_bộ_sưu_tập}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Điều này tương đương với việc truy xuất trang thứ 11, với 10 bản ghi mỗi trang.
Có giá trị offset lớn có thể dẫn đến vấn đề về hiệu suất, và phương pháp truy xuất dựa trên vector thường không hỗ trợ phân trang. Mà không truy xuất các vector đầu tiên, không thể lấy vector gần nhất thứ N.
Tuy nhiên, sử dụng tham số offset có thể tiết kiệm tài nguyên bằng cách giảm lưu lượng mạng và truy cập vào bộ nhớ.
Khi sử dụng tham số offset, cần phải truy xuất bên trong offset + limit điểm, nhưng chỉ truy cập vào dữ liệu trả về và vectors của những điểm đó thực sự được trả về từ bộ nhớ.
Nhóm API
Có sẵn từ phiên bản v1.2.0
Kết quả có thể được nhóm theo một trường cụ thể. Điều này sẽ rất hữu ích khi bạn có nhiều điểm cho cùng một mục và muốn tránh các mục nhập dư thừa trong kết quả.
Ví dụ, nếu bạn có một tài liệu lớn chia thành nhiều phần và muốn tìm kiếm hoặc đề xuất dựa trên từng tài liệu, bạn có thể nhóm kết quả theo ID tài liệu.
Giả sử có các điểm với các tải trọng:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Sử dụng nhóm API, bạn sẽ có thể lấy N điểm hàng đầu cho mỗi tài liệu, giả sử tải trọng của điểm chứa ID tài liệu. Tất nhiên, có thể có trường hợp mà N điểm tốt nhất không thể đáp ứng do thiếu điểm hoặc khoảng cách tương đối lớn từ truy vấn. Trong mỗi trường hợp, group_size là một tham số nỗ lực tốt nhất, tương tự như tham số limit.
Tìm Kiếm Nhóm
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// Giống như API tìm kiếm thường
"vector": [1.1],
...,
// Tham số nhóm
"group_by": "document_id", // Đường dẫn trường để nhóm theo
"limit": 4, // Số nhóm tối đa
"group_size": 2, // Số điểm tối đa mỗi nhóm
}
Đề Xuất Nhóm
REST API (Schema):
POST /collections/{tên_bộ_sưu_tập}/points/recommend/groups
{
// Tương tự như API đề xuất thông thường
"negative": [1],
"positive": [2, 5],
...,
// Tham số nhóm
"group_by": "document_id", // Đường dẫn trường để nhóm theo
"limit": 4, // Số nhóm tối đa
"group_size": 2, // Số điểm tối đa trong mỗi nhóm
}
Bất kể đó là tìm kiếm hay đề xuất, kết quả đầu ra như sau:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
Các nhóm được sắp xếp theo điểm số cao nhất của các điểm trong mỗi nhóm. Trong mỗi nhóm, các điểm cũng được sắp xếp.
Nếu trường group_by của một điểm là một mảng (ví dụ, "document_id": ["a", "b"]), điểm đó có thể được bao gồm trong nhiều nhóm (ví dụ, "document_id": "a" và "document_id": "b").
Chức năng này phụ thuộc nặng vào khóa group_by được cung cấp. Để cải thiện hiệu suất, đảm bảo rằng một chỉ mục dành riêng cho nó được tạo. Hạn chế:
- Tham số
group_bychỉ hỗ trợ các giá trị payload từ khóa và số nguyên. Các loại giá trị payload khác sẽ bị bỏ qua. - Hiện tại, không hỗ trợ phân trang khi sử dụng nhóm, vì vậy tham số
offsetkhông được phép.
Tìm kiếm trong các nhóm
Có sẵn từ phiên bản v1.3.0
Trong những trường hợp có nhiều điểm cho các phần khác nhau của cùng một mục, sự trùng lặp thường được giới thiệu trong dữ liệu đã lưu trữ. Nếu thông tin chung giữa các điểm là tối thiểu, điều này có thể chấp nhận được. Tuy nhiên, đối với các tải trọng lớn hơn, điều này có thể trở thành vấn đề, vì nó sẽ tính toán không gian lưu trữ cần thiết cho các điểm dựa trên số lượng điểm trong nhóm.
Một phương pháp tối ưu hóa cho việc lưu trữ khi sử dụng các nhóm là lưu trữ thông tin chung giữa các điểm dựa trên cùng một ID nhóm trong một điểm duy nhất trong bộ sưu tập khác. Sau đó, khi sử dụng API nhóm, hãy thêm tham số with_lookup để thêm thông tin này cho mỗi nhóm.
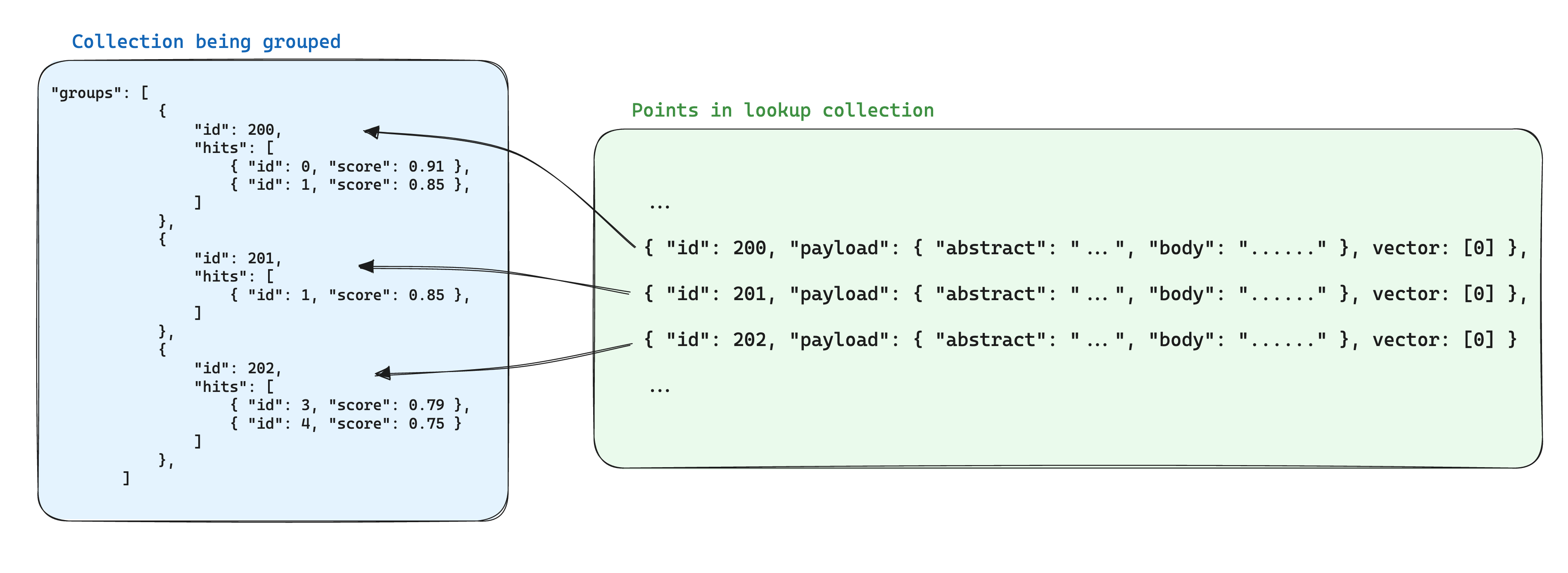
Một lợi ích khác của cách tiếp cận này là khi thông tin chung trong các điểm nhóm thay đổi, chỉ cần cập nhật điểm duy nhất.
Ví dụ, nếu bạn có một bộ sưu tập tài liệu, bạn có thể muốn chia nhỏ chúng và lưu trữ các điểm thuộc về những phần này trong một bộ sưu tập riêng biệt, đảm bảo rằng các ID điểm thuộc về tài liệu được lưu trong dữ liệu của điểm phần này.
Trong kịch bản này, để đưa thông tin từ các tài liệu vào các phần đã phân loại theo ID tài liệu, tham số with_lookup có thể được sử dụng:
POST /collections/chunks/points/search/groups
{
// Cùng các tham số như trong API tìm kiếm thông thường
"vector": [1.1],
...,
// Tham số phân nhóm
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Tham số tìm kiếm
"with_lookup": {
// Tên bộ sưu tập của những điểm cần tìm kiếm
"collection": "documents",
// Các tùy chọn chỉ định nội dung được đưa vào từ dữ liệu của điểm tìm kiếm, mặc định là true
"with_payload": ["title", "text"],
// Các tùy chọn chỉ định nội dung được đưa vào từ vector của các điểm tìm kiếm, mặc định là true
"with_vectors": false
}
}
Đối với tham số with_lookup, có thể sử dụng viết tắt with_lookup="documents" để đưa toàn bộ dữ liệu và vector mà không cần chỉ định rõ ràng.
Kết quả tìm kiếm sẽ được hiển thị trong trường lookup dưới mỗi nhóm.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Tài liệu A",
"text": "Đây là tài liệu A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Tài liệu B",
"text": "Đây là tài liệu B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Khi tìm kiếm được thực hiện bằng cách trực tiếp khớp các ID điểm, bất kỳ ID nhóm nào không tồn tại (và hợp lệ) như một ID điểm sẽ bị bỏ qua, và trường lookup sẽ rỗng.