Similarity Search
In many applications of machine learning, searching for nearest vectors is a core element. Modern neural networks are trained to transform objects into vectors, making objects that are close in the vector space also close in the real world. For example, text with similar meanings, visually similar images, or songs belonging to the same genre.
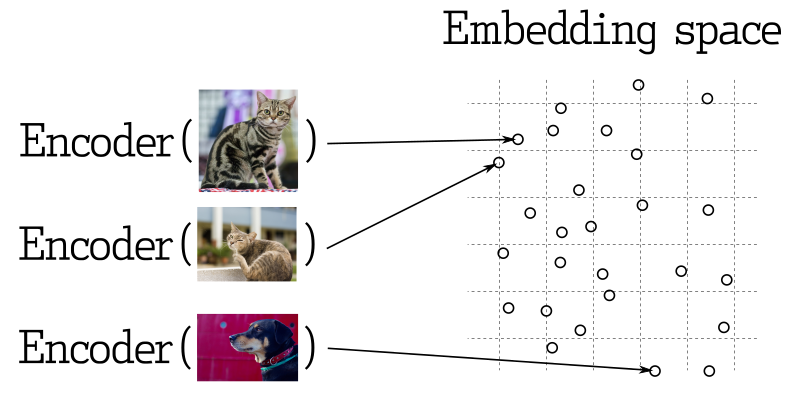
Similarity Measurement
There are many methods to evaluate the similarity between vectors. In Qdrant, these methods are called similarity measurements. The choice of measurement depends on how the vectors are obtained, especially the method used to train the neural network encoder.
Qdrant supports the following most common types of measurements:
- Dot product:
Dot - Cosine similarity:
Cosine - Euclidean distance:
Euclid
The most commonly used measurement in similarity learning models is cosine measurement.
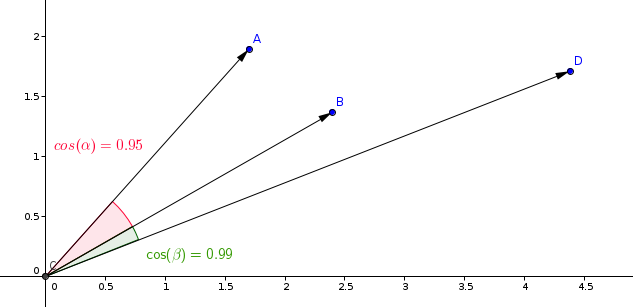
Qdrant calculates this measurement in two steps, thereby achieving higher search speeds. The first step is to normalize the vectors when adding them to the collection. This is done only once for each vector.
The second step is vector comparison. In this case, it is equivalent to a dot product operation, due to the fast operations of SIMD.
Query Plan
Depending on the filters used in the search, there are several possible scenarios for query execution. Qdrant selects one of the query execution options based on available indexes, complexity of conditions, and the cardinality of filtered results. This process is called query planning.
The strategy selection process relies on heuristic algorithms and may vary by version. However, the general principles are:
- Execute query plans independently for each segment (for detailed information about segments, please refer to storage).
- Prioritize full scans if the number of points is low.
- Estimate the cardinality of filtered results before selecting a strategy.
- Use payload indexes to retrieve points if the cardinality is low (see indexes).
- Use filterable vector indexes if the cardinality is high.
Thresholds can be adjusted independently for each collection through the configuration file.
Search API
Let's take a look at an example of a search query.
REST API - API schema definitions can be found here.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
In this example, we are looking for vectors similar to the vector [0.2, 0.1, 0.9, 0.7]. The parameter limit (or its alias top) specifies the number of most similar results we want to retrieve.
The values under the params key specify custom search parameters. The currently available parameters are:
-
hnsw_ef- specifies the value of theefparameter for the HNSW algorithm. -
exact- whether to use exact (ANN) search option. If set to True, the search may take a long time as it performs a complete scan to obtain exact results. -
indexed_only- using this option can disable searching in segments that have not yet built a vector index. This may be useful to minimize the impact on search performance during updates. Using this option may result in partial results if the collection is not fully indexed, so use it only in cases where acceptable eventual consistency is required.
Since the filter parameter is specified, the search is only performed among points that meet the filtering criteria. For more detailed information about possible filters and their functionalities, please refer to the Filters section.
A sample result for this API might look like this:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
The result contains a list of discovered points sorted by score.
Please note that by default, these results lack payload and vector data. Refer to the Payload and Vector in Results section for how to include payload and vectors in the results.
Available from version v0.10.0
If a collection is created with multiple vectors, the name of the vector to be used for searching should be provided:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
The search is only carried out between vectors with the same name.
Filtering Results by Score
In addition to payload filtering, it may also be useful to filter out results with low similarity scores. For example, if you know the minimum acceptable score for a model and do not want any similarity results below the threshold, you can use the score_threshold parameter for the search query. It will exclude all results with scores lower than the given value.
This parameter may exclude both lower and higher scores, depending on the metric used. For example, higher scores in the Euclidean metric are considered farther away and thus will be excluded.
Payload and Vectors in Results
By default, the retrieval method does not return any stored information, such as payload and vectors. Additional parameters with_vectors and with_payload can modify this behavior.
Example:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
The parameter with_payload can also be used to include or exclude specific fields:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Batch Search API
Available since v0.10.0
The batch search API allows executing multiple search requests through a single request.
Its semantics are simple, n batch search requests are equivalent to n separate search requests.
This method has several advantages. Logically, it requires fewer network connections, which is beneficial in itself.
More importantly, if the batch requests have the same filter, the batch request will be efficiently handled and optimized through the query planner.
This has a significant impact on latency for non-trivial filters, as intermediate results can be shared between requests.
To use it, simply pack your search requests together. Of course, all regular search request attributes are available.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
The results of this API contain an array for each search request.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Recommended API
The negative vector is an experimental feature and is not guaranteed to work with all types of embeddings. In addition to regular searches, Qdrant also allows you to search based on multiple vectors already stored in a collection. This API is used for vector search of encoded objects without involving neural network encoders.
The Recommended API allows you to specify multiple positive and negative vector IDs, and the service will merge them into a specific average vector.
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
If only one positive ID is provided, this request is equivalent to a regular search for the vector at that point.
Vector components with larger values in the negative vector are penalized, while vector components with larger values in the positive vector are amplified. This average vector is then used to find the most similar vectors in the collection.
The API schema definition for REST API can be found here.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
The sample result for this API will be as follows:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Available from v0.10.0 onwards
If the collection is created using multiple vectors, the names of the vectors being used should be specified in the recommend request:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
The using parameter specifies the stored vector to be used for recommendation.
Batch Recommended API
Available from v0.10.0 onwards
Similar to the batch search API, with similar usage and benefits, it can process recommendation requests in batch.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
The result of this API contains an array for each recommendation request.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Pagination
Available from version v0.8.3
The search and recommendation API allows skipping the first few results of the search and only returning results starting from a specific offset.
Example:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
This is equivalent to retrieving the 11th page, with 10 records per page.
Having a large offset value may lead to performance issues, and the vector-based retrieval method typically does not support pagination. Without retrieving the first N vectors, it is not possible to retrieve the Nth closest vector.
However, using the offset parameter can save resources by reducing network traffic and access to storage.
When using the offset parameter, it is necessary to internally retrieve offset + limit points, but only access the payload and vectors of those points that are actually returned from storage.
Grouping API
Available from version v1.2.0
Results can be grouped based on a specific field. This will be very useful when you have multiple points for the same item and want to avoid redundant entries in the results.
For example, if you have a large document divided into multiple chunks and want to search or recommend based on each document, you can group the results by document ID.
Suppose there are points with payloads:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Using the groups API, you will be able to fetch the top N points for each document, assuming the point's payload contains the document ID. Of course, there may be cases where the best N points cannot be satisfied due to a shortage of points or relatively large distance from the query. In each case, group_size is a best-effort parameter, similar to the limit parameter.
Group Search
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// Same as the regular search API
"vector": [1.1],
...,
// Grouping parameters
"group_by": "document_id", // The field path to group by
"limit": 4, // Maximum number of groups
"group_size": 2, // Maximum number of points per group
}
Group Recommendation
REST API (Schema):
POST /collections/{collection_name}/points/recommend/groups
{
// Same as the regular recommendation API
"negative": [1],
"positive": [2, 5],
...,
// Grouping parameters
"group_by": "document_id", // The field path to group by
"limit": 4, // Maximum number of groups
"group_size": 2, // Maximum number of points per group
}
Regardless of whether it's a search or recommendation, the output results are as follows:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
Groups are sorted by the highest score of the points within each group. Within each group, the points are also sorted.
If the group_by field of a point is an array (e.g., "document_id": ["a", "b"]), the point can be included in multiple groups (e.g., "document_id": "a" and document_id: "b").
This functionality heavily depends on the provided group_by key. To improve performance, ensure a dedicated index is created for it. Restrictions:
- The
group_byparameter only supports keyword and integer payload values. Other payload value types will be ignored. - Currently, pagination is not supported when using groups, so the
offsetparameter is not allowed.
Searching within Groups
Available since v1.3.0
In cases where there are multiple points for different parts of the same item, redundancy is often introduced in the stored data. If the shared information between the points is minimal, this may be acceptable. However, it can become problematic with heavier loads, as it will calculate the storage space required for the points based on the number of points in the group.
An optimization for storage when using groups is to store the shared information between points based on the same group ID in a single point within another collection. Then, when using the groups API, add the with_lookup parameter to add this information for each group.
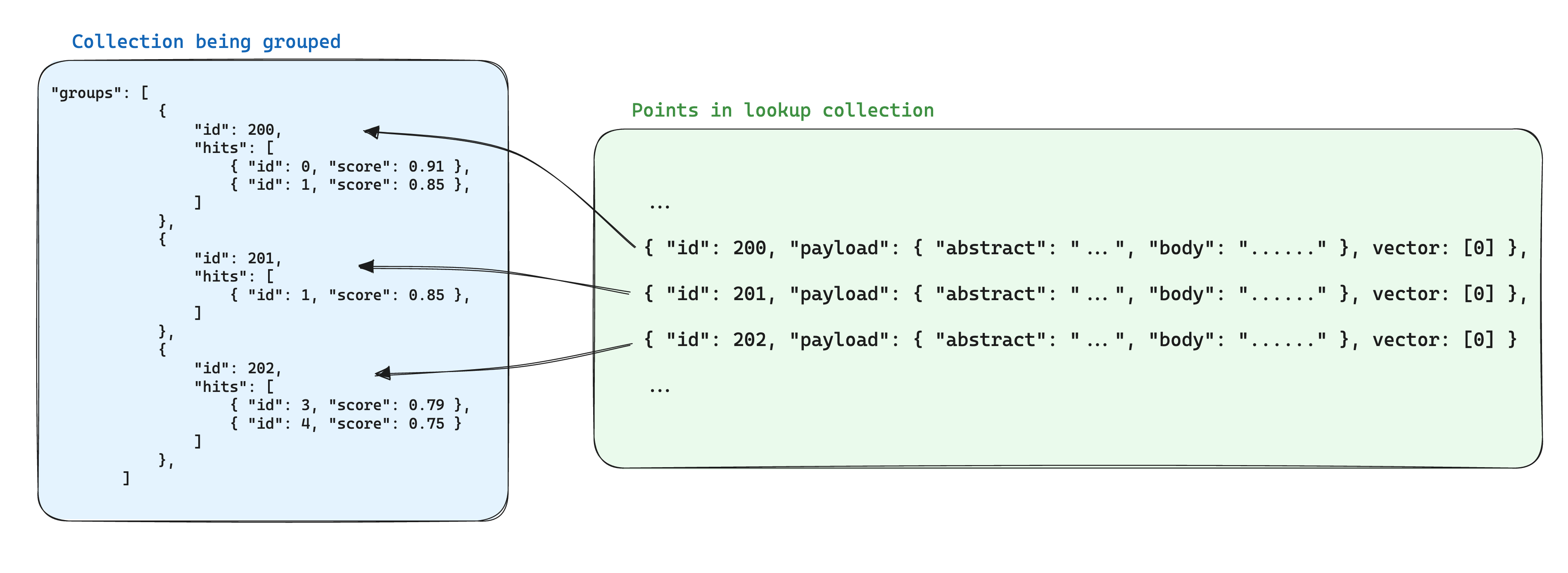
An additional benefit of this approach is that when the shared information within group points changes, only the single point needs to be updated.
For example, if you have a collection of documents, you may want to chunk them and store the points belonging to these chunks in a separate collection, ensuring that the point IDs belonging to the documents are stored in the chunk point's payload.
In this scenario, to bring the information from the documents into the chunks grouped by document ID, the with_lookup parameter can be used:
POST /collections/chunks/points/search/groups
{
// Same parameters as in the regular search API
"vector": [1.1],
...,
// Grouping parameters
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Search parameters
"with_lookup": {
// Collection name of the points to search
"collection": "documents",
// Options specifying the content to bring in from the search points' payload, default is true
"with_payload": ["title", "text"],
// Options specifying the content to bring in from the search points' vectors, default is true
"with_vectors": false
}
}
For the with_lookup parameter, a shorthand with_lookup="documents" can also be used to bring in the entire payload and vectors without explicitly specifying.
The search results will be displayed in the lookup field under each group.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Document A",
"text": "This is document A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Document B",
"text": "This is document B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
As the searching is done by directly matching the point IDs, any group IDs that are not existing (and valid) point IDs will be ignored, and the lookup field will be empty.