Wyszukiwanie podobieństw
W wielu aplikacjach uczenia maszynowego wyszukiwanie najbliższych wektorów stanowi rdzeń działania. Nowoczesne sieci neuronowe są trenowane do przekształcania obiektów w wektory, co powoduje, że obiekty bliskie w przestrzeni wektorowej są również bliskie w rzeczywistości. Na przykład teksty o podobnym znaczeniu, wizualnie podobne obrazy lub piosenki należące do tego samego gatunku.
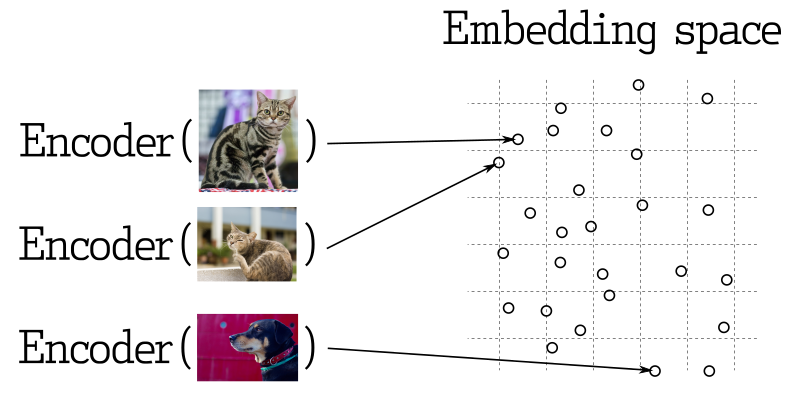
Pomiar podobieństwa
Istnieje wiele metod oceny podobieństwa między wektorami. W Qdrant te metody nazywane są pomiarami podobieństwa. Wybór metody zależy od sposobu uzyskania wektorów, w szczególności od metody użytej do trenowania kodera sieci neuronowej.
Qdrant obsługuje następujące najczęstsze typy pomiarów:
- Iloczyn skalarny:
Dot - Podobieństwo kosinusowe:
Cosine - Odległość euklidesowa:
Euclid
Najczęściej stosowanym pomiarem w modelach uczenia podobieństwa jest pomiar kosinusowy.
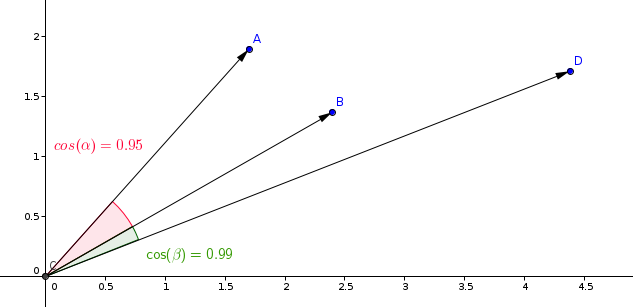
Qdrant oblicza ten pomiar w dwóch krokach, co pozwala osiągnąć wyższe prędkości wyszukiwania. Pierwszym krokiem jest znormalizowanie wektorów podczas dodawania ich do kolekcji. Jest to wykonywane tylko raz dla każdego wektora.
Drugim krokiem jest porównanie wektorów. W tym przypadku jest to równoważne operacji iloczynu skalarnego, ze względu na szybkie operacje SIMD.
Plan zapytania
W zależności od filtrów używanych w wyszukiwaniu, istnieje kilka możliwych scenariuszy wykonania zapytania. Qdrant wybiera jedną z opcji wykonania zapytania na podstawie dostępnych indeksów, złożoności warunków i kardynalności wyników filtrowania. Ten proces nazywany jest planowaniem zapytania.
Proces wyboru strategii polega na algorytmach heurystycznych i może się różnić w zależności od wersji. Ogólne zasady to:
- Wykonuj plany zapytań niezależnie dla każdego segmentu (dla szczegółowych informacji o segmentach, prosimy o odwołanie się do przechowywania).
- Priorytetyzuj pełne skanowania, jeśli liczba punktów jest niska.
- Szacuj kardynalność wyników filtrowania przed wyborem strategii.
- Użyj indeksów ładunków, aby pobrać punkty, jeśli kardynalność jest niska (patrz indeksy).
- Użyj indeksów wektorów przepuszczalnych, jeśli kardynalność jest wysoka.
Progi można dostosować niezależnie dla każdej kolekcji za pomocą pliku konfiguracyjnego.
Interfejs wyszukiwania
Przyjrzyjmy się przykładowemu zapytaniu wyszukiwania.
REST API - Definicje schematu API można znaleźć tutaj.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
W tym przykładzie szukamy wektorów podobnych do wektora [0.2, 0.1, 0.9, 0.7]. Parametr limit (lub jego alias top) określa liczbę najbardziej podobnych wyników, które chcemy pobrać.
Wartości pod kluczem params określają niestandardowe parametry wyszukiwania. Obecnie dostępne parametry to:
-
hnsw_ef- określa wartość parametruefdla algorytmu HNSW. -
exact- czy używać opcji dokładnego (ANN) wyszukiwania. Jeśli ustawiono na True, wyszukiwanie może zająć dużo czasu, ponieważ wykonuje kompletny skan w celu uzyskania dokładnych wyników. -
indexed_only- korzystanie z tej opcji może wyłączyć wyszukiwanie w segmentach, które jeszcze nie zbudowały indeksu wektorów. Może to być przydatne do minimalizacji wpływu na wydajność wyszukiwania podczas aktualizacji. Użycie tej opcji może skutkować częściowymi wynikami, jeśli kolekcja nie jest w pełni zindeksowana, dlatego należy jej używać tylko w przypadkach, gdy wymagana jest akceptowalna spójność wyników.
Ponieważ zastosowano parametr filter, wyszukiwanie odbywa się tylko wśród punktów spełniających kryteria filtru. Aby uzyskać bardziej szczegółowe informacje na temat możliwych filtrów i ich funkcjonalności, prosimy o odwołanie się do sekcji Filtry.
Przykładowy wynik tego interfejsu API może wyglądać tak:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
W result znajduje się lista odkrytych punktów posortowana według score.
Należy zauważyć, że domyślnie te wyniki nie zawierają danych ładunku i wektorów. Odnośnie do zawarcia ładunku i wektorów w wynikach, prosimy odwołać się do sekcji Wyniki.
Dostępne od wersji v0.10.0
Jeśli kolekcja jest utworzona z wieloma wektorami, należy podać nazwę wektora, który ma zostać użyty do wyszukiwania:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
Wyszukiwanie jest przeprowadzane tylko między wektorami o tej samej nazwie.
Filtracja wyników według wyniku
Oprócz filtracji ładunku, może być również przydatne wykluczenie wyników z niskimi wynikami podobieństwa. Na przykład, jeśli znasz minimalny akceptowalny wynik dla modelu i nie chcesz żadnych wyników podobieństwa poniżej progu, możesz użyć parametru score_threshold dla zapytania wyszukiwania. Wykluczy on wszystkie wyniki z wynikami niższymi niż podana wartość.
Parametr ten może wykluczyć zarówno niższe, jak i wyższe wyniki, w zależności od zastosowanej metryki. Na przykład wyższe wyniki w metryce euklidesowej są uważane za dalej położone i tym samym zostaną wykluczone.
Ładunek i Wektory w Wynikach
Domyślnie metoda wyszukiwania nie zwraca żadnych przechowywanych informacji, takich jak ładunek i wektory. Dodatkowe parametry with_vectors i with_payload mogą zmodyfikować to zachowanie.
Przykład:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
Parametr with_payload można również użyć do zawarcia lub wykluczenia konkretnych pól:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Batch Search API
Available since v0.10.0
API wsadowego wyszukiwania pozwala na wykonanie wielu żądań wyszukiwania za pomocą pojedynczego żądania.
Jego semantyka jest prosta - n żądań wyszukiwania wsadowego jest równoważne n osobnym żądaniom wyszukiwania.
Ta metoda ma kilka zalet. Logicznie rzecz biorąc, wymaga mniej połączeń sieciowych, co samo w sobie jest korzystne.
Co ważniejsze, jeśli żądania wsadowe mają ten sam filtr, żądanie wsadowe będzie efektywnie obsługiwane i zoptymalizowane przez planer zapytań.
Ma to znaczący wpływ na opóźnienia dla nietrywialnych filtrów, ponieważ wyniki pośrednie mogą być współużytkowane między żądaniami.
Aby go użyć, po prostu spakuj swoje żądania wyszukiwania razem. Oczywiście wszystkie zwykłe atrybuty żądania wyszukiwania są dostępne.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Wyniki tego interfejsu API zawierają tablicę dla każdego żądania wyszukiwania.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Recommended API
Ujemny wektor jest funkcją eksperymentalną i nie ma gwarancji, że będzie działać ze wszystkimi rodzajami osadzeń. Oprócz zwykłych wyszukiwań, Qdrant pozwala również na wyszukiwanie oparte na wielu wektorach już przechowywanych w kolekcji. To API służy do wyszukiwania wektorowego zakodowanych obiektów bez angażowania enkoderów sieci neuronowych.
API Rekomendowane pozwala określić wiele pozytywnych i negatywnych identyfikatorów wektorów, a usługa pomiesza je w określony wektor średni.
wektor_sredni = avg(wektory_pozytywne) + ( avg(wektory_pozytywne) - avg(wektory_negatywne) )
Jeśli podany jest tylko jeden identyfikator pozytywny, to żądanie to jest równoważne zwykłemu wyszukiwaniu wektora w tym punkcie.
Składniki wektora z większymi wartościami w wektorze negatywnym są karane, podczas gdy składniki wektora z większymi wartościami w wektorze pozytywnym są wzmacniane. Następnie ten wektor średni jest używany do znalezienia najbardziej podobnych wektorów w kolekcji.
Definicja schematu interfejsu API REST można znaleźć tutaj.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
Przykładowy wynik dla tego interfejsu API będzie następujący:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Dostępne od wersji v0.10.0
Jeśli kolekcja jest tworzona przy użyciu wielu wektorów, nazwy używanych wektorów powinny być określone w żądaniu rekomendacji:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
Parametr using określa przechowywany wektor do użycia w rekomendacji.
API rekomendacji zbiorowej
Dostępne od wersji v0.10.0
Podobne do API wyszukiwania zbiorowego, z podobnym użyciem i korzyściami, może przetwarzać żądania rekomendacji zbiorowo.
POST /kolekcje/{nazwa_kolekcji}/punkty/rekomenduj/zbiorowo
{
"wyszukiwania": [
{
"filtr": {
"musi": [
{
"klucz": "miasto",
"pasuje": {
"wartość": "Londyn"
}
}
]
},
"negatywne": [718],
"pozytywne": [100, 231],
"limit": 10
},
{
"filtr": {
"musi": [
{
"klucz": "miasto",
"pasuje": {
"wartość": "Londyn"
}
}
]
},
"negatywne": [300],
"pozytywne": [200, 67],
"limit": 10
}
]
}
Wynik tego API zawiera tablicę dla każdego żądania rekomendacji.
{
"wynik": [
[
{ "id": 10, "wynik": 0.81 },
{ "id": 14, "wynik": 0.75 },
{ "id": 11, "wynik": 0.73 }
],
[
{ "id": 1, "wynik": 0.92 },
{ "id": 3, "wynik": 0.89 },
{ "id": 9, "wynik": 0.75 }
]
],
"status": "ok",
"czas": 0.001
}
Paginacja
Dostępne od wersji v0.8.3
API wyszukiwania i rekomendacji pozwala pominąć kilka pierwszych wyników wyszukiwania i zwrócić tylko wyniki zaczynając od określonego przesunięcia.
Przykład:
POST /kolekcje/{nazwa_kolekcji}/punkty/wyszukaj
{
"wektor": [0.2, 0.1, 0.9, 0.7],
"z_wektorami": true,
"z_danymi_wartości": true,
"limit": 10,
"przesunięcie": 100
}
To jest równoważne pobraniu 11. strony, z 10 rekordami na stronie.
Duże wartości przesunięcia mogą prowadzić do problemów wydajnościowych, a metoda pobierania oparta na wektorach zazwyczaj nie obsługuje paginacji. Bez pobierania pierwszych N wektorów nie jest możliwe pobranie N-tego najbliższego wektora.
Jednakże, korzystanie z parametru przesunięcie może oszczędzać zasoby poprzez ograniczenie ruchu sieciowego i dostępu do przechowywania.
Przy użyciu parametru przesunięcie, konieczne jest wewnętrzne pobranie przesunięcie + limit punktów, ale dostęp tylko do danych wartości i wektorów tych punktów, które faktycznie są zwracane z przechowywania.
Grupowanie interfejsu API
Dostępne od wersji v1.2.0
Wyniki mogą zostać pogrupowane na podstawie określonego pola. Będzie to bardzo przydatne, gdy będziesz miał wiele punktów dla tego samego elementu i będziesz chciał uniknąć nadmiarowych wpisów w wynikach.
Na przykład, jeśli masz duży dokument podzielony na kilka części i chcesz wyszukiwać lub rekomendować na podstawie każdego dokumentu, możesz pogrupować wyniki według identyfikatora dokumentu.
Załóżmy, że istnieją punkty z ładunkami:
{
{
"id": 0,
"payload": {
"część_fragmentu": 0,
"identyfikator_dokumentu": "a",
},
"wektor": [0.91],
},
{
"id": 1,
"payload": {
"część_fragmentu": 1,
"identyfikator_dokumentu": ["a", "b"],
},
"wektor": [0.8],
},
{
"id": 2,
"payload": {
"część_fragmentu": 2,
"identyfikator_dokumentu": "a",
},
"wektor": [0.2],
},
{
"id": 3,
"payload": {
"część_fragmentu": 0,
"identyfikator_dokumentu": 123,
},
"wektor": [0.79],
},
{
"id": 4,
"payload": {
"część_fragmentu": 1,
"identyfikator_dokumentu": 123,
},
"wektor": [0.75],
},
{
"id": 5,
"payload": {
"część_fragmentu": 0,
"identyfikator_dokumentu": -10,
},
"wektor": [0.6],
},
}
Korzystając z interfejsu API groups, będziesz w stanie pobrać najlepsze N punktów dla każdego dokumentu, zakładając, że ładunek punktu zawiera identyfikator dokumentu. Oczywiście, mogą wystąpić przypadki, gdzie najlepsze N punktów nie mogą zostać zaspokojone z powodu braku punktów lub względnie dużej odległości od zapytania. W każdym przypadku parametr group_size jest parametrem próby najlepszego wysiłku, podobnie jak parametr limit.
Wyszukiwanie grupy
REST API (Schema):
POST /kolekcje/{nazwa_kolekcji}/punkty/szukaj/grupy
{
// To samo co zwykłe API wyszukiwania
"wektor": [1.1],
...,
// Parametry grupowania
"group_by": "identyfikator_dokumentu", // Ścieżka pola do pogrupowania
"limit": 4, // Maksymalna liczba grup
"group_size": 2, // Maksymalna liczba punktów na grupę
}
Rekomendacja grupowa
REST API (Schemat):
POST /kolekcje/{nazwa_kolekcji}/punkty/polec/grupy
{
// To samo co w zwykłym API rekomendacyjnym
"negatywne": [1],
"pozytywne": [2, 5],
...,
// Parametry grupowania
"grupuj_przez": "id_dokumentu", // Ścieżka pola do grupowania
"limit": 4, // Maksymalna liczba grup
"rozmiar_grupy": 2, // Maksymalna liczba punktów w grupie
}
Niezależnie od tego, czy jest to wyszukiwanie czy rekomendacja, wyniki wyjściowe przedstawiają się następująco:
{
"wynik": {
"grupy": [
{
"id": "a",
"trafienia": [
{ "id": 0, "wynik": 0.91 },
{ "id": 1, "wynik": 0.85 }
]
},
{
"id": "b",
"trafienia": [
{ "id": 1, "wynik": 0.85 }
]
},
{
"id": 123,
"trafienia": [
{ "id": 3, "wynik": 0.79 },
{ "id": 4, "wynik": 0.75 }
]
},
{
"id": -10,
"trafienia": [
{ "id": 5, "wynik": 0.6 }
]
}
]
},
"status": "ok",
"czas": 0.001
}
Grupy są sortowane według najwyższego wyniku punktów w każdej grupie. W ramach każdej grupy punkty są również sortowane.
Jeśli pole grupuj_przez punktu jest tablicą (np. "id_dokumentu": ["a", "b"]), punkt może być zawarty w wielu grupach (np. "id_dokumentu": "a" i id_dokumentu: "b").
Funkcjonalność ta w dużej mierze zależy od dostarczonego klucza grupuj_przez. Aby poprawić wydajność, upewnij się, że został utworzony dedykowany indeks. Ograniczenia:
- Parametr
grupuj_przezobsługuje wyłącznie wartości ładunku słowa kluczowego i całkowitoliczbowe. Inne typy wartości ładunku będą ignorowane. - Obecnie nie jest obsługiwana paginacja podczas korzystania z grup, więc parametr
offsetnie jest dozwolony.
Wyszukiwanie w obrębie grup
Dostępne od wersji v1.3.0
W przypadkach, gdy istnieje wiele punktów dla różnych części tego samego elementu, często wprowadzana jest nadmiarowość przechowywanych danych. Jeśli współdzielone informacje między punktami są minimalne, może to być akceptowalne. Jednakże może to być problematyczne przy większym obciążeniu, ponieważ zostanie obliczona przestrzeń przechowywania wymagana dla punktów w oparciu o liczbę punktów w grupie.
Optymalizacją przechowywania przy użyciu grup jest przechowywanie współdzielonych informacji między punktami na podstawie tego samego identyfikatora grupy w jednym punkcie w innej kolekcji. Następnie, przy użyciu interfejsu API grupy, dodaj parametr with_lookup, aby dodać te informacje dla każdej grupy.
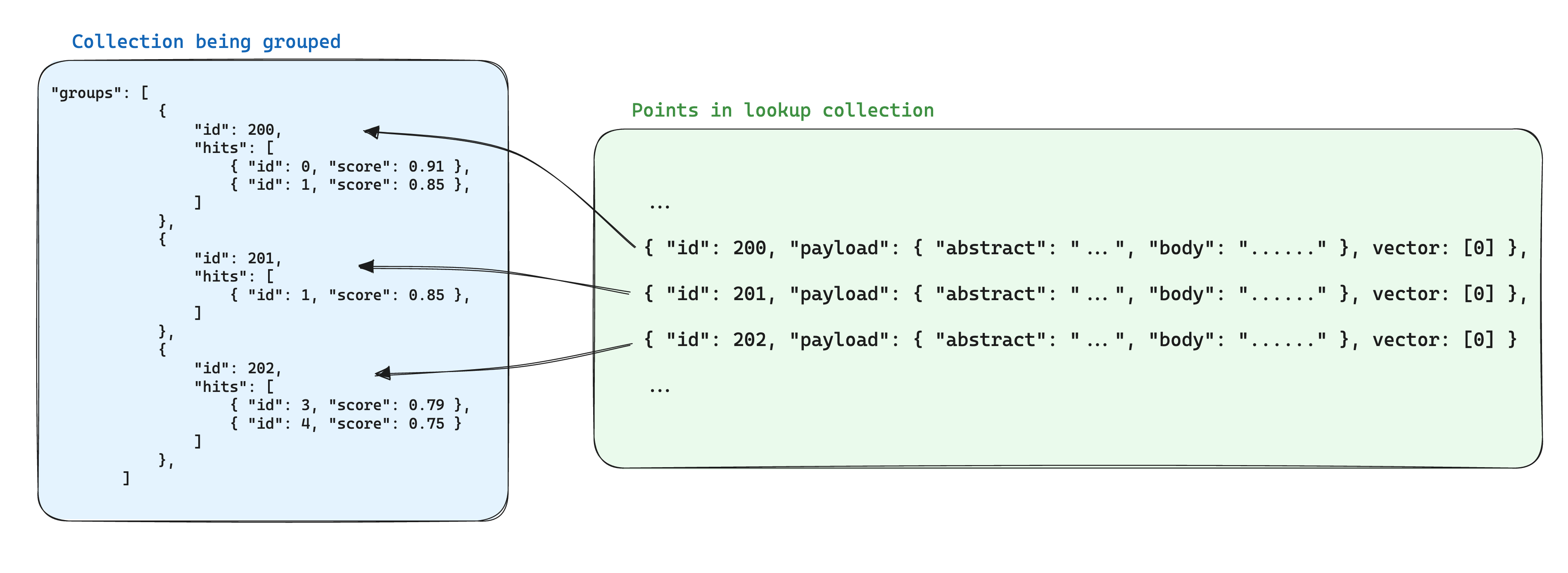
Dodatkową korzyścią tego podejścia jest to, że gdy współdzielona informacja w punktach grupy ulegnie zmianie, potrzebna będzie aktualizacja tylko jednego punktu.
Na przykład, jeśli masz kolekcję dokumentów, możesz chcieć podzielić je na kawałki i przechowywać punkty należące do tych kawałków w osobnej kolekcji, zapewniając, że identyfikatory punktów należące do dokumentów są przechowywane w ładunku punktu kawałka.
W tym scenariuszu, aby przynieść informacje z dokumentów do kawałków pogrupowanych według identyfikatora dokumentu, można użyć parametru with_lookup:
POST /collections/chunks/points/search/groups
{
// Takie same parametry jak w zwykłym interfejsie API wyszukiwania
"vector": [1.1],
...,
// Parametry grupowania
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Parametry wyszukiwania
"with_lookup": {
// Nazwa kolekcji punktów do wyszukiwania
"collection": "documents",
// Opcje określające zawartość do przyniesienia z ładunku punktów wyszukiwania, domyślnie true
"with_payload": ["title", "text"],
// Opcje określające zawartość do przyniesienia z wektorów punktów wyszukiwania, domyślnie true
"with_vectors": false
}
}
Dla parametru with_lookup, można również użyć skrótu with_lookup="documents", aby przynieść cały ładunek i wektory bez jawnego określania.
Wyniki wyszukiwania zostaną wyświetlone w polu lookup pod każdą grupą.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Dokument A",
"text": "To jest dokument A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Dokument B",
"text": "To jest dokument B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Ponieważ wyszukiwanie jest wykonywane poprzez bezpośrednie dopasowanie identyfikatorów punktów, wszelkie identyfikatory grup, które nie są istniejącymi (i prawidłowymi) identyfikatorami punktów, zostaną zignorowane, a pole lookup będzie puste.