समानता खोज
मशीन लर्निंग के कई अनुप्रयोगों में, निकटतम वेक्टर्स की खोज एक मौलिक तत्त्व है। आधुनिक संज्ञानात्मक नेटवर्कों को वस्तुओं को वेक्टर्स में परिवर्तित करने के लिए प्रशिक्षित किया जाता है, जिससे वेक्टर स्पेस में निकट वस्तुएं वास्तविक दुनिया में भी निकट होती हैं। उदाहरण के लिए, समार्थ के साथ समान शब्द, दृश्य में समान छवियां, या एक ही प्रकार के गाने।
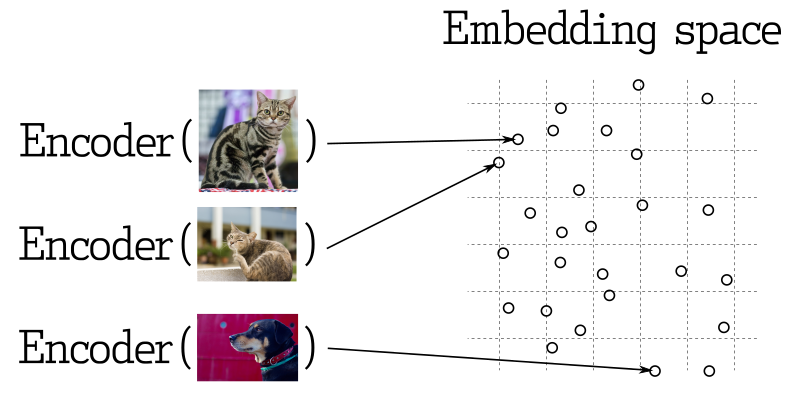
समानता मापन
वेक्टरों के बीच समानता को मापने के लिए कई तरीके हैं। Qdrant में, इन तरीकों को समानता मापन कहा जाता है। मापन की चुनौती वेक्टर कैसे प्राप्त किए गए हैं, विशेषकर न्यूरल नेटवर्क एनकोडर के प्रशिक्षण में उपयोग की गई विधि पर निर्भर करती है।
Qdrant निम्नलिखित सबसे सामान्य प्रकार के मापन का समर्थन करता है:
- डॉट उत्पाद:
Dot - कोसाइन समानता:
Cosine - यूक्लिडियन दूरी:
Euclid
समानता शिक्षण मॉडल में सबसे आमतौर पर उपयोग की जाने वाली मापन है कोसाइन मापन।
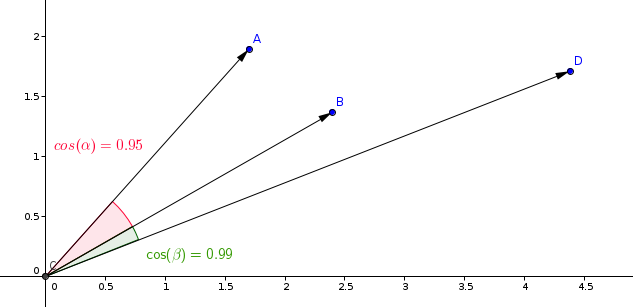
Qdrant इस मापन को दो चरणों में गणना करता है, और इस तरीके से अधिक तेज़ खोज गतियां प्राप्त करता है। पहला चरण वेक्टर्स को मूल्यांकन के समय में सामान्य करना है। यह केवल हर वेक्टर के लिए एक बार किया जाता है।
दूसरा चरण वेक्टर तुलना है। इस मामले में, यह SIMD की तेज क्रियाओं के कारण डॉट उत्पाद कार्य के समान होता है।
पूँजी योजना
खोज में उपयोग की जाने वाली फ़िल्टरों के आधार पर, क्वड्रांत में क्वेरी क्रियान्वयन के कई संभावित स्थितियां हो सकती हैं। Qdrant उपलब्ध इंडेक्स, संयोजन की जटिलता, और फ़िल्टर के परिणाम की कार्डिनैलिटी पर आधारित एक क्वेरी निष्क्रिय कार्रय विकल्प का चयन करता है। इस प्रक्रिया को क्वेरी नियोजन कहा जाता है।
रणनीति चयन प्रक्रिया हीयूरिस्टिक एल्गोरिदम पर निर्भर करती है, और संस्करण के अनुसार भिन्न हो सकती है। हालांकि, सामान्य सिद्धांत हैं:
- प्रत्येक सेगमेंट के लिए क्वेरी योजनाएँ स्वतंत्र रूप से क्रियान्वित करें (सेगमेंट के बारे में विस्तृत जानकारी के लिए, कृपया संग्रह को संदर्भित करें)।
- यदि बिंदुओं की संख्या कम हो, तो पूर्ण स्कैन को प्राथमिकता दें।
- प्राथमिकता देने से पहले फ़िल्टर के परिणाम की कार्डिनैलिटी का अनुमान लगाएं।
- यदि कार्डिनैलिटी कम है, तो प्वालोड इंडेक्स का उपयोग करके बिन्दुओं को पुनर्प्राप्त करें (इंडेक्स देखें)।
- यदि कार्डिनैलिटी अधिक है, तो फ़िल्टरयों संभावनात्मक वेक्टर इंडेक्स का प्रयोग करें।
प्रत्येक संग्रह के लिए अलग-अलग सेटिंग्स को कॉन्फ़िगरेशन फ़ाइल के माध्यम से समायोजित किया जा सकता है।
खोज API
चलो एक खोज क्वेरी का उदाहरण देखते हैं।
REST API - API स्कीमा परिभाषाएँ यहाँ उपलब्ध हैं।
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "लंदन"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
इस उदाहरण में, हम vector [0.2, 0.1, 0.9, 0.7] के समान वेक्टर ढूँढ रहे हैं। पैरामीटर limit (या इसका पर्याय top) स्पष्ट करता है कि हमें कितने सबसे समान परिणाम प्राप्त करना चाहिए।
params कुंजी के नीचे मौजूद मान स्वनिर्धारित खोज पैरामीटर स्पष्ट करते हैं। वर्तमान में उपलब्ध पैरामीटर हैं:
-
hnsw_ef- HNSW एल्गोरिदम के लिएefपैरामीटर का मान स्पष्ट करता है। -
exact- क्या सटीक (ANN) खोज विकल्प का उपयोग करना है। यदि यह सत्य है, तो खोज विश्वक्षिप्त परिणाम प्राप्त करने के लिए पूर्ण अंकवधान करता है, इसलिए खोज बहुत समय ले सकती है। -
indexed_only- इस विकल्प का उपयोग वेक्टर सूचीकरण नहीं किए गए सेगमेंटों में खोज को निष्क्रिय कर सकता है। इसे अपडेट के दौरान खोज प्रदर्शन पर गहरा प्रभाव कम करने के लिए उपयोगी हो सकता है। इस विकल्प का उपयोग करने से यदि संग्रह पूरी तरह से सूचीकृत नहीं है, तो आंशिक परिणाम हो सकते हैं, इसलिए इसे केवल उन मामलों में ही उपयोग करें जहां स्वीकार्य आनतरिक संगतता की आवश्यकता है।
filter पैरामीटर स्पष्ट किया गया है, इसलिए खोज केवल उन बिंदुओं के बीच की जाती है जो फ़िल्टरिंग मानदंडों को पूरा करते हैं। अधिक जानकारी के लिए संभावित फिल्टर और उनके कार्यक्षमताओं के लिए कृपया फ़िल्टर्स अनुभाग में संदर्भित करें।
इस API के लिए एक सैंपल परिणाम इस तरह से दिख सकता है:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result में score से छाँटे हुए पाये गए बिंदुओं की सूची है।
कृपया ध्यान दें कि डिफ़ॉल्ट रूप से, इन परिणामों में कोई परिष्कृत और वेक्टर डेटा नहीं होता है। परिणाम में पेलोड और वेक्टर कैसे शामिल किए जाएं, इसके लिए कृपया Payload और Vector in Results अनुभाग में संदर्भित करें।
संस्करण v0.10.0 से उपलब्ध है
यदि किसी संग्रह को एक से अधिक वेक्टरों के साथ बनाया गया है, तो खोज के लिए उपयोग किए जाने वाले वेक्टर का नाम प्रदान किया जाना चाहिए:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
यह खोज केवल उन वेक्टरों के बीच की जाती है जिनका नाम समान है।
स्कोर द्वारा परिणामों की फिल्टरिंग
पेलोड फिल्टरिंग के अलावा, समानता स्कोर कम होने वाले परिणामों को फिल्टर करना भी उपयुक्त हो सकता है। उदाहरण के लिए, यदि आपको एक मॉडल के लिए न्यूनतम स्वीकार्य स्कोर पता है और आप थ्रेशोल्ड से नीचे किसी भी समानता परिणामों को नहीं चाहते, तो खोज क्वेरी के लिए score_threshold पैरामीटर का उपयोग कर सकते हैं। यह दिये गए मान से कम स्कोर वाले सभी परिणामों को अप्राप्त करेगा।
यह पैरामीटर मेट्रिक पर निर्भर करके, न तो कम और न ही अधिक समानता को निष्क्रिय कर सकता है। उदाहरण के लिए, यूक्लिडियन मेट्रिक में अधिक समानता वाले स्कोर्स को दूर माना जाता है और इसलिए उन्हें निष्क्रिय कर दिया जाएगा।
पेलोड और परिणामों में वेक्टर
डिफ़ॉल्ट रूप से, प्राप्ति विधि किसी भी संग्रहित जानकारी, जैसे पेलोड और वेक्टर नहीं देता है। अतिरिक्त पैरामीटर with_vectors और with_payload इस व्यवहार को संशोधित कर सकते हैं।
उदाहरण:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
पैरामीटर with_payload का उपयोग विशेष क्षेत्रों को शामिल या बाहर करने के लिए भी किया जा सकता है:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
बैच सर्च एपीआई
v0.10.0 से उपलब्ध
बैच सर्च एपीआई एक ही अनुरोध के माध्यम से कई सर्च अनुरोधों को निष्पादित करने की अनुमति देती है।
इसका अर्थातात्विक तत्व सरल है, n बैच सर्च अनुरोध n अलग सर्च अनुरोधों के समान होते हैं।
इस विधि में कई फायदे हैं। तार्किक तौर पर, इसमें कम नेटवर्क कनेक्शन की आवश्यकता होती है, जो स्वयं में फायदेमंद होता है।
और भी महत्वपूर्ण है, अगर बैच अनुरोधों में समान फिल्टर हो, तो क्वेरी प्लानर के माध्यम से बैच अनुरोध को समर्पित तरीके से संचालित और अनुकूलित किया जाएगा।
यह अंतरज्ञानी फिल्टरों के लिए देरी के लिए एक प्रमुख प्रभाव होता है, क्योंकि द्वार्किक परिणामों को अनुरोधों के बीच साझा किया जा सकता है।
इसका उपयोग करने के लिए, आसानी से अपने सर्च अनुरोधों को साथ में पैक करें। बेशक, सभी सामान्य सर्च अनुरोध विशेषताएँ उपलब्ध हैं।
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "लंदन"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "लंदन"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
इस एपीआई के परिणाम में प्रत्येक सर्च अनुरोध के लिए एक ब्रैयरी होता है।
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
सिफारिशित एपीआई
नेगेटिव वेक्टर एक प्रायोगिक विशेषता है और यह सुनिश्चित नहीं किया जाता है कि यह सभी प्रकार के एम्बेडिंग्स के साथ काम करेगा। सामान्य सर्चों के अलावा, Qdrant आपको संग्रह में पहले से स्टोर किए गए मल्टीपल वेक्टर्स के आधार पर भी सर्च करने की अनुमति देता है। यह एपीआई न्यूरल नेटवर्क एन्कोडर को शामिल किए बिना एनकोड किए गए ऑब्जेक्ट्स के वेक्टर सर्च के लिए उपयोग होता है।
सिफारिशित एपीआई आपको विभिन्न सकारात्मक और नकारात्मक वेक्टर आईडी निर्दिष्ट करने की अनुमति देती है, और सेवा उन्हें एक विशेष औसत वेक्टर में मर्ज करेगी।
औसत_वेक्टर = avg(सकारात्मक_वेक्टर) + ( avg(सकारात्मक_वेक्टर) - avg(नकारात्मक_वेक्टर) )
अगर केवल एक सकारात्मक आईडी दिया गया है, तो यह अनुरोध उस बिंदु पर वेक्टर के लिए एक सामान्य सर्च के समान होता है।
नकारात्मक वेक्टर में बड़े मूल्य वाले वेक्टर घातीत होते हैं, जबकि सकारात्मक वेक्टर में बड़े मूल्य वाले वेक्टर बढ़ाए जाते हैं। फिर इस औसत वेक्टर का उपयोग संग्रह में सबसे समान वेक्टर्स खोजने के लिए किया जाता है।
REST एपीआई के लिए एपीआई स्कीमा परिभाषा यहाँ पाई जा सकती है यहाँ.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "लंदन"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
इस एपीआई के लिए नमूना परिणाम इस प्रकार होगा:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
उपलब्ध v0.10.0 के बाद
अगर संग्रह को एक से अधिक वेक्टरों का उपयोग करके बनाया गया है, तो सिफारिश के अनुरोध में इस्तेमाल होने वाले वेक्टरों के नाम निर्दिष्ट किए जाने चाहिए:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
using पैरामीटर स्थापित करता है कि सिफारिश के लिए स्टोर किए गए वेक्टर का उपयोग किया जाना चाहिए।
बैच सिफारिश API
v0.10.0 के बाद उपलब्ध
बैच खोज API के समान, इसके समान उपयोग और लाभ के साथ, यह बैच में सिफारिश अनुरोध को प्रसंस्कृत कर सकता है।
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "लंदन"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "लंदन"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
इस API का परिणाम प्रत्येक सिफारिश अनुरोध के लिए एक एरे में होता है।
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
पृष्ठांकन
v0.8.3 से उपलब्ध
खोज और सिफारिश API द्वारा पहले कुछ परिणामों को छोड़कर सिर्फ एक निश्चित ओफसेट से प्रारंभ होने वाले परिणामों को वापस लाने की अनुमति होती है।
उदाहरण:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
यह 11वें पृष्ठ को प्राप्त करने के सामान है, प्रति पृष्ठ 10 रिकॉर्ड होता है।
बड़े ओफसेट मूल्य का उपयोग करना प्रदर्शन समस्याओं में डाल सकता है, और वेक्टर-आधारित प्राप्ति विधि आमतौर पर पृष्ठांकन का समर्थन नहीं करती है। पहले N वेक्टरों को प्राप्त करने के बिना, N वेक्टर को प्राप्त करना संभव नहीं है।
हालांकि, ओफसेट पैरामीटर का उपयोग संसाधनों को कम करके नेटवर्क ट्रैफिक और संग्रह तक पहुंच को कम करके संसाधनों को बचाने में सक्षम हो सकता है।
जब offset पैरामीटर का उपयोग कर रहे होते हैं, तो आंतरिक रूप से offset + limit बिंदुओं को प्राप्त करना आवश्यक होता है, लेकिन केवल उन बिंदुओं के द्वारा प्रस्तुत किए गए पायलोड और वेक्टर्स तक ही पहुंच प्राप्त करने के लिए संग्रह से।
समूहीकरण एपीआई
संस्करण v1.2.0 से उपलब्ध
परिणाम एक विशिष्ट क्षेत्रानुसार समूहीकृत किए जा सकते हैं। यह जब बहुत से बिंदुओं के लिए आपके पास परिणामों में अव्यावशिष्ट प्रविष्टियों से बचना चाहते हैं, तो बहुत उपयोगी होगा।
उदाहरण के लिए, यदि आपके पास एक बड़े दस्तावेज की अनेक भागों में विभाजित एक या एक से अधिक नुक्ताइज़ हैं और हर दस्तावेज के आधार पर खोज या सिफारिश करना चाहते हैं, तो आप दस्ताव
समूह सिफारिश
REST API (स्कीमा):
POST /collections/{collection_name}/points/recommend/groups
{
// निशानेबाजी API के समान
"negative": [1],
"positive": [2, 5],
...,
// समूहीकरण पैरामीटर
"group_by": "document_id", // समूहीकरण के लिए फ़ील्ड पथ
"limit": 4, // समूहों की अधिकतम संख्या
"group_size": 2, // प्रति समूह की अधिकतम बिंदु संख्या
}
चाहे खोज हो या सिफारिश, उत्पादित परिणाम निम्नलिखित रहते हैं:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
समूह स्कोरिंग के अनुसार समूहों को क्रमबद्ध किया जाता है। प्रत्येक समूह में, बिंदुओं को भी क्रमबद्ध किया जाता है।
अगर किसी बिंदु का group_by फ़ील्ड एक सरणी है (जैसे, "document_id": ["a", "b"]), तो बिंदु को कई समूहों में शामिल किया जा सकता है (जैसे, "document_id": "a" और "document_id": "b").
यह कार्यक्षमता केवल प्रदान की गई group_by कुंजी पर अत्यधिक निर्भर करती है। प्रदर्शन बेहतर बनाने के लिए सुनिश्चित करें कि इसके लिए एक विशेष निर्देशिका बनाया गया है। प्रतिबंध:
-
group_byपैरामीटर केवल कीवर्ड और पूर्णांक पेयलोड मानों का समर्थन करता है। अन्य पेयलोड मान प्रविष्टियों को नजरअंदाज किया जाएगा। - वर्तमान में, groups का उपयोग करते समय पृष्ठांकन का समर्थन नहीं है, इसलिए
offsetपैरामीटर की अनुमति नहीं है।
समूहों के भीतर खोज
v1.3.0 से उपलब्ध
ऐसे मामलों में जहां एक ही आइटम के विभिन्न हिस्सों के लिए कई बिंदुओं का होता है, तो संग्रहित डेटा में अक्सर अतिरिक्तता उत्पन्न हो जाती है। यदि बिंदुओं के बीच साझा जानकारी न्यूनतम है, तो यह स्वीकार्य हो सकता है। हालांकि, इस व्यवस्था से भारी भावनात्मक बोझ होने पर, समस्याएँ उत्पन्न हो सकती हैं, क्योंकि यह समूह में बिंदुओं की संख्या के आधार पर बिंदुओं के लिए आवश्यक स्टोरेज स्थान की गणना करेगा।
समूहों का उपयोग करते समय स्टोरेज के लिए एक अनुकूलन साझा जानकारी को एक ही समूह पहले किसी अन्य संग्रह में किसी एकल बिंदु में स्टोर करना है जिसका समूह आईडी समान हो। फिर, समूहों API का उपयोग करते समय, प्रत्येक समूह के लिए इस जानकारी को जोड़ने के लिए with_lookup पैरामीटर जोड़ें।
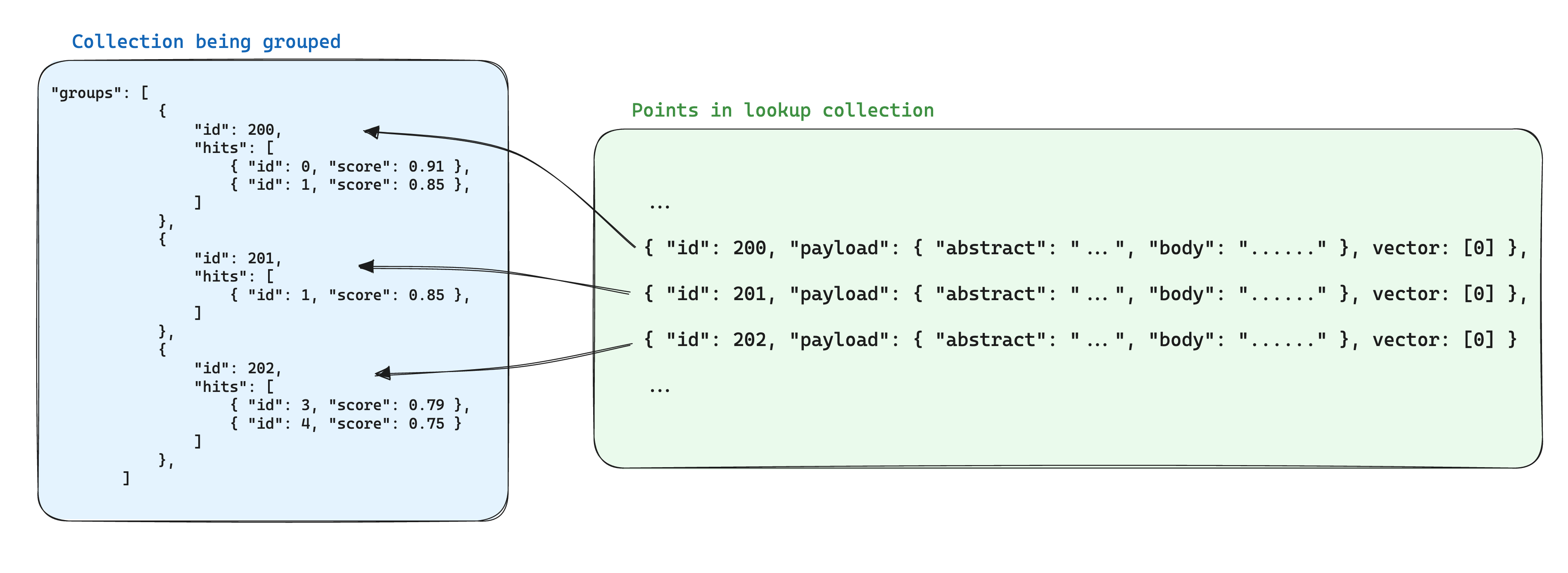
इस दृष्टिकोण से एक अतिरिक्त फायदा यह है कि जब समूह बिंदुओं के भीतर साझा जानकारी बदलती है, तो केवल एक एकल बिंदु को अपड