Pencarian Kesamaan
Dalam banyak aplikasi pembelajaran mesin, pencarian vektor terdekat adalah elemen inti. Jaringan saraf modern dilatih untuk mentransformasikan objek menjadi vektor, membuat objek yang dekat dalam ruang vektor juga dekat dalam dunia nyata. Misalnya, teks dengan makna yang mirip, gambar yang mirip secara visual, atau lagu-lagu yang termasuk dalam genre yang sama.
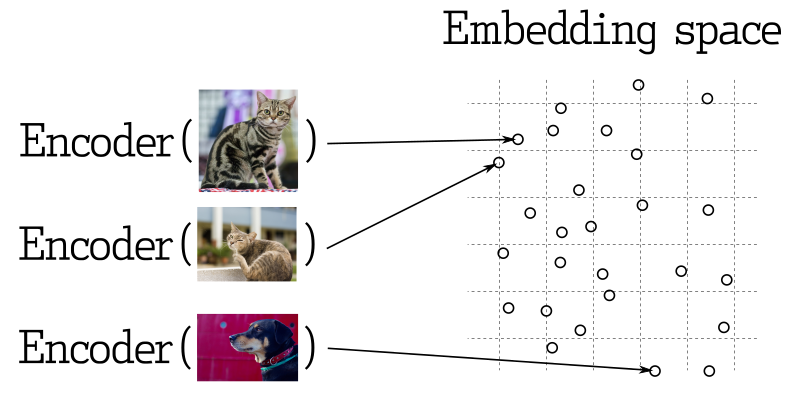
Pengukuran Kesamaan
Ada banyak metode untuk mengevaluasi kesamaan antara vektor. Dalam Qdrant, metode-metode ini disebut pengukuran kesamaan. Pemilihan pengukuran bergantung pada bagaimana vektor diperoleh, terutama metode yang digunakan untuk melatih enkoder jaringan saraf.
Qdrant mendukung jenis pengukuran yang paling umum:
- Produk titik:
Dot - Kesamaan kosinus:
Cosine - Jarak euclidean:
Euclid
Pengukuran yang paling umum digunakan dalam model pembelajaran kesamaan adalah pengukuran kosinus.
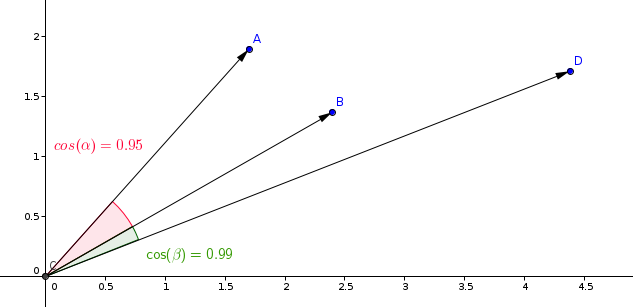
Qdrant menghitung pengukuran ini dalam dua langkah, sehingga mencapai kecepatan pencarian yang lebih tinggi. Langkah pertama adalah normalisasi vektor saat menambahkannya ke koleksi. Ini dilakukan hanya sekali untuk setiap vektor.
Langkah kedua adalah perbandingan vektor. Dalam hal ini, ini ekuivalen dengan operasi produk titik, karena operasi SIMD yang cepat.
Rencana Permintaan
Tergantung pada filter yang digunakan dalam pencarian, ada beberapa skenario yang mungkin untuk eksekusi permintaan. Qdrant memilih salah satu opsi eksekusi permintaan berdasarkan indeks yang tersedia, kompleksitas kondisi, dan kardinalitas hasil yang difilter. Proses ini disebut perencanaan permintaan.
Proses pemilihan strategi bergantung pada algoritma heuristik dan dapat bervariasi berdasarkan versi. Namun, prinsip-prinsip umumnya adalah:
- Jalankan rencana permintaan secara independen untuk setiap segmen (untuk informasi detail tentang segmen, silakan merujuk ke penyimpanan).
- Prioritaskan pemeriksaan penuh jika jumlah titik rendah.
- Perkirakan kardinalitas hasil yang difilter sebelum memilih strategi.
- Gunakan indeks payload untuk mengambil titik jika kardinalitasnya rendah (lihat indeks).
- Gunakan indeks vektor yang dapat difilter jika kardinalitasnya tinggi.
Ambang batas dapat disesuaikan secara independen untuk setiap koleksi melalui berkas konfigurasi.
API Pencarian
Mari kita lihat contoh dari sebuah query pencarian.
REST API - Definisi skema API dapat ditemukan di sini.
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
Pada contoh ini, kita mencari vektor yang mirip dengan vektor [0.2, 0.1, 0.9, 0.7]. Parameter limit (atau aliasnya top) menentukan jumlah hasil yang paling mirip yang ingin kita ambil.
Nilai di bawah kunci params menentukan parameter pencarian kustom. Parameter yang saat ini tersedia adalah:
-
hnsw_ef- menentukan nilai dari parameterefuntuk algoritma HNSW. -
exact- apakah akan menggunakan opsi pencarian tepat (ANN). Jika diatur sebagai True, pencarian bisa memakan waktu lama karena melakukan pemindaian lengkap untuk memperoleh hasil yang tepat. -
indexed_only- menggunakan opsi ini dapat menonaktifkan pencarian di segmen yang belum membangun indeks vektor. Hal ini mungkin berguna untuk meminimalkan dampak pada kinerja pencarian selama pembaruan. Menggunakan opsi ini dapat menghasilkan hasil parsial jika koleksi belum sepenuhnya diindeks, jadi gunakan hanya dalam kasus di mana konsistensi eventual yang dapat diterima diperlukan.
Karena parameter filter telah ditentukan, pencarian hanya dilakukan di antara titik-titik yang memenuhi kriteria filter. Untuk informasi lebih detail tentang filter yang mungkin dan fungsionalitasnya, silakan merujuk ke bagian Filters.
Hasil contoh untuk API ini mungkin terlihat seperti ini:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
result berisi daftar titik yang ditemukan yang diurutkan berdasarkan score.
Harap diperhatikan bahwa secara default, hasil ini tidak memiliki payload dan data vektor. Lihat Payload dan Vektor dalam bagian Hasil untuk cara menyertakan payload dan vektor dalam hasil.
Tersedia mulai dari versi v0.10.0
Jika sebuah koleksi dibuat dengan beberapa vektor, nama vektor yang akan digunakan untuk pencarian harus disediakan:
POST /collections/{collection_name}/points/search
{
"vector": {
"name": "image",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
Pencarian hanya dilakukan di antara vektor-vektor dengan nama yang sama.
Menyaring Hasil berdasarkan Skor
Selain penyaringan payload, mungkin juga berguna untuk menyaring hasil dengan skor kesamaan rendah. Misalnya, jika Anda mengetahui skor minimum yang dapat diterima untuk sebuah model dan tidak ingin hasil kemiripan di bawah ambang batas, Anda dapat menggunakan parameter score_threshold untuk query pencarian. Ini akan mengeluarkan semua hasil dengan skor lebih rendah dari nilai yang diberikan.
Parameter ini dapat mengeluarkan baik skor lebih rendah maupun lebih tinggi, tergantung pada metrik yang digunakan. Misalnya, skor lebih tinggi dalam metrik Euclidean dianggap lebih jauh dan oleh karena itu akan dikecualikan.
Payload dan Vektor dalam Hasil
Secara default, metode pengambilan tidak mengembalikan informasi yang disimpan, seperti payload dan vektor. Parameter tambahan with_vectors dan with_payload dapat memodifikasi perilaku ini.
Contoh:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
Parameter with_payload juga dapat digunakan untuk menyertakan atau mengesampingkan field-field tertentu:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["city"]
}
}
Batch Search API
Tersedia sejak v0.10.0
API pencarian batch memungkinkan untuk mengeksekusi beberapa permintaan pencarian melalui satu permintaan tunggal.
Semantiknya sederhana, n permintaan pencarian batch setara dengan n permintaan pencarian terpisah.
Metode ini memiliki beberapa kelebihan. Secara logis, metode ini membutuhkan lebih sedikit koneksi jaringan, yang bermanfaat dalam dirinya sendiri.
Yang lebih penting, jika permintaan batch memiliki filter yang sama, permintaan batch akan ditangani dengan efisien dan dioptimalkan melalui perencana kueri.
Hal ini memiliki dampak signifikan pada latensi untuk filter yang tidak sepele, karena hasil perantara dapat dibagikan di antara permintaan.
Untuk menggunakannya, cukup memasukkan permintaan pencarian ke dalam satu paket. Tentu saja, semua atribut permintaan pencarian reguler tersedia.
POST /collections/{collection_name}/points/search/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"vector": [0.5, 0.3, 0.2, 0.3],
"limit": 3
}
]
}
Hasil dari API ini berisi sebuah array untuk setiap permintaan pencarian.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
API Rekomendasi
Vektor negatif adalah fitur eksperimental dan tidak dijamin akan berfungsi dengan semua jenis embedding. Selain pencarian reguler, Qdrant juga memungkinkan Anda untuk mencari berdasarkan beberapa vektor yang sudah disimpan dalam sebuah koleksi. API ini digunakan untuk pencarian vektor objek terenkripsi tanpa melibatkan pengkode jaringan saraf.
API Rekomendasi memungkinkan Anda untuk menentukan beberapa ID vektor positif dan negatif, dan layanan akan menggabungkannya menjadi vektor rata-rata tertentu.
average_vector = avg(positive_vectors) + ( avg(positive_vectors) - avg(negative_vectors) )
Jika hanya satu ID positif yang diberikan, permintaan ini setara dengan pencarian reguler untuk vektor pada titik tersebut.
Komponen vektor dengan nilai lebih besar pada vektor negatif dikenai penalti, sementara komponen vektor dengan nilai lebih besar pada vektor positif diperkuat. Vektor rata-rata ini kemudian digunakan untuk menemukan vektor-vetor paling mirip di dalam koleksi.
Definisi skema API untuk REST API dapat ditemukan di sini.
POST /collections/{collection_name}/points/recommend
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
}
Hasil contoh untuk API ini akan sebagai berikut:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
Tersedia sejak v0.10.0
Jika koleksi dibuat menggunakan beberapa vektor, nama vektor yang digunakan harus dijelaskan dalam permintaan rekomendasi:
POST /collections/{collection_name}/points/recommend
{
"positive": [100, 231],
"negative": [718],
"using": "image",
"limit": 10
}
Parameter using menentukan vektor yang disimpan untuk digunakan dalam rekomendasi.
Batch Rekomendasi API
Tersedia mulai dari v0.10.0 ke atas
Mirip dengan API pencarian batch, dengan penggunaan dan manfaat yang serupa, API ini dapat memproses permintaan rekomendasi secara batch.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "London"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
Hasil dari API ini berisi array untuk setiap permintaan rekomendasi.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Pagination
Tersedia mulai dari versi v0.8.3
API pencarian dan rekomendasi memungkinkan untuk melewati beberapa hasil pencarian pertama dan hanya mengembalikan hasil dimulai dari offset tertentu.
Contoh:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Ini setara dengan mengambil halaman ke-11, dengan 10 catatan per halaman.
Memiliki nilai offset yang besar dapat menyebabkan masalah kinerja, dan metode pengambilan berbasis vektor umumnya tidak mendukung pembagian halaman. Tanpa mengambil vektor pertama, tidak mungkin untuk mengambil vektor terdekat ke-N.
Namun, menggunakan parameter offset dapat menghemat sumber daya dengan mengurangi lalu lintas jaringan dan akses ke penyimpanan.
Ketika menggunakan parameter offset, diperlukan untuk secara internal mengambil offset + limit titik, tetapi hanya mengakses payload dan vektor dari titik-titik tersebut yang benar-benar dikembalikan dari penyimpanan.
Pengelompokan API
Tersedia mulai dari versi v1.2.0
Hasil dapat dikelompokkan berdasarkan suatu field tertentu. Ini akan sangat berguna ketika Anda memiliki beberapa titik untuk item yang sama dan ingin menghindari entri yang redundan dalam hasil.
Sebagai contoh, jika Anda memiliki dokumen besar yang terbagi menjadi beberapa bagian dan ingin mencari atau merekomendasikan berdasarkan setiap dokumen, Anda dapat mengelompokkan hasil berdasarkan ID dokumen.
Misalkan terdapat titik-titik dengan payloads:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Dengan menggunakan API groups, Anda akan dapat mengambil N titik teratas untuk setiap dokumen, dengan asumsi payload titik tersebut berisi ID dokumen. Tentu saja, mungkin ada kasus di mana N titik terbaik tidak dapat dipenuhi karena kekurangan titik atau jarak yang relatif jauh dari query. Dalam setiap kasus, group_size adalah parameter upaya terbaik, mirip dengan parameter limit.
Pencarian Kelompok
REST API (Schema):
POST /collections/{collection_name}/points/search/groups
{
// Sama dengan API pencarian reguler
"vector": [1.1],
...,
// Parameter pengelompokan
"group_by": "document_id", // Path field untuk dikelompokkan
"limit": 4, // Jumlah maksimum kelompok
"group_size": 2, // Jumlah maksimum titik per kelompok
}
Rekomendasi Grup
REST API (Skema):
POST /collections/{collection_name}/points/recommend/groups
{
// Sama seperti API rekomendasi biasa
"negative": [1],
"positive": [2, 5],
...,
// Parameter Pengelompokan
"group_by": "document_id", // Jalur bidang untuk dikelompokkan
"limit": 4, // Jumlah maksimum grup
"group_size": 2, // Jumlah maksimum points per grup
}
Terlepas dari apakah itu pencarian atau rekomendasi, hasil output sebagai berikut:
{
"result": {
"groups": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"time": 0.001
}
Grup diurutkan berdasarkan skor tertinggi dari points di dalam setiap grup. Di dalam setiap grup, points juga diurutkan.
Jika bidang group_by dari sebuah point adalah array (misalnya, "document_id": ["a", "b"]), point dapat disertakan dalam beberapa grup (misalnya, document_id: "a" dan document_id: "b").
Fungsionalitas ini sangat bergantung pada kunci group_by yang disediakan. Untuk meningkatkan kinerja, pastikan index khusus telah dibuat untuk itu. Batasan:
- Parameter
group_byhanya mendukung nilai payload kata kunci dan integer. Jenis nilai payload lain akan diabaikan. - Saat ini, penomoran halaman tidak didukung saat menggunakan grup, sehingga parameter
offsettidak diizinkan.
Pencarian dalam Kelompok
Tersedia sejak v1.3.0
Dalam kasus di mana terdapat beberapa poin untuk bagian-bagian berbeda dari item yang sama, seringkali redundansi diperkenalkan dalam data yang disimpan. Jika informasi yang sama di antara poin-poin tersebut minimal, hal ini mungkin dapat diterima. Namun, hal ini dapat menjadi masalah ketika beban yang lebih berat, karena akan menghitung ruang penyimpanan yang diperlukan untuk poin-poin berdasarkan jumlah poin dalam kelompok.
Salah satu optimasi untuk penyimpanan saat menggunakan kelompok adalah dengan menyimpan informasi yang sama di antara poin-poin berdasarkan ID kelompok yang sama dalam satu poin di dalam kumpulan lain. Kemudian, saat menggunakan API groups, tambahkan parameter with_lookup untuk menambahkan informasi ini untuk setiap kelompok.
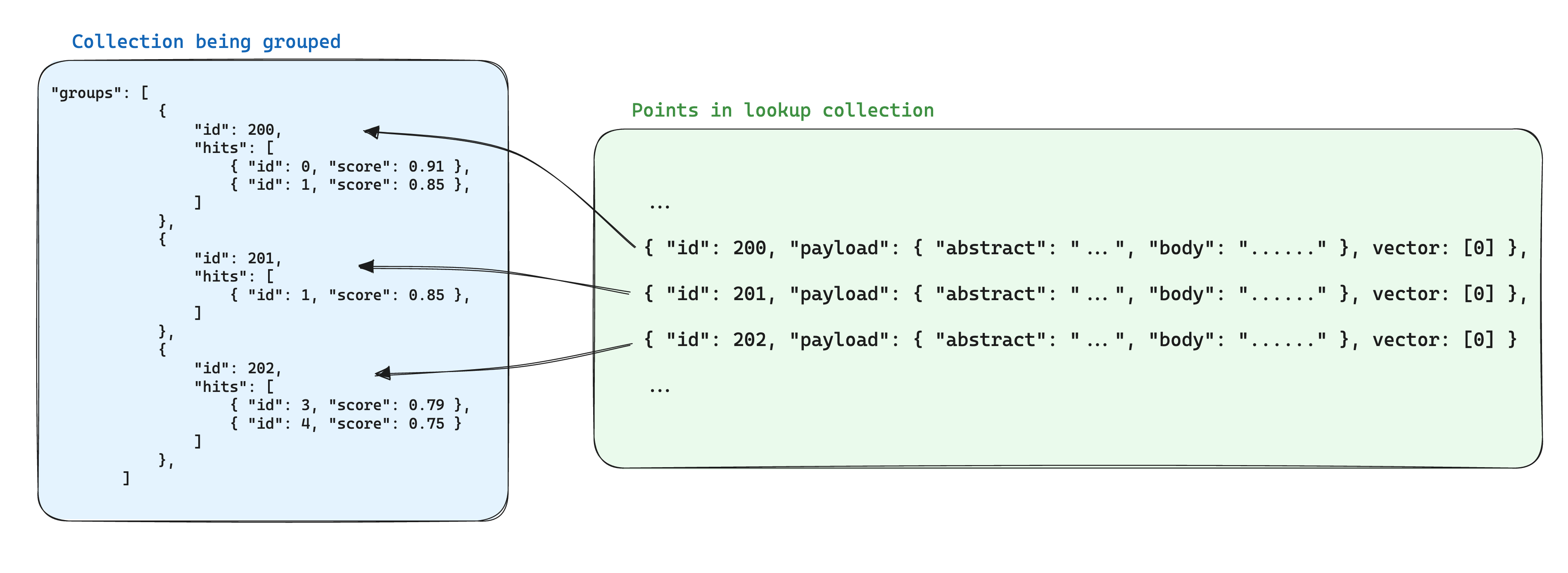
Keuntungan tambahan dari pendekatan ini adalah bahwa ketika informasi bersama di antara poin-poin kelompok berubah, hanya poin tunggal perlu diperbarui.
Sebagai contoh, jika Anda memiliki koleksi dokumen, Anda mungkin ingin membagi-bagi mereka dan menyimpan poin-poin yang dimiliki oleh bagian-bagian ini di dalam koleksi terpisah, memastikan bahwa ID poin yang dimiliki dokumen disimpan di dalam muatan poin bagi bagian-bagian ini.
Dalam skenario ini, untuk membawa informasi dari dokumen ke dalam bagian-bagian yang dikelompokkan berdasarkan ID dokumen, parameter with_lookup dapat digunakan:
POST /collections/chunks/points/search/groups
{
// Sama dengan parameter dalam API pencarian reguler
"vector": [1.1],
...,
// Parameter pengelompokan
"group_by": "document_id",
"limit": 2,
"group_size": 2,
// Parameter pencarian
"with_lookup": {
// Nama koleksi poin-poin yang akan dicari
"collection": "documents",
// Opsi yang menentukan konten yang akan dibawa dari muatan poin-poin pencarian, default adalah true
"with_payload": ["title", "text"],
// Opsi yang menentukan konten yang akan dibawa dari vektor poin-poin pencarian, default adalah true
"with_vectors": false
}
}
Untuk parameter with_lookup, singkatan with_lookup="documents" juga dapat digunakan untuk membawa seluruh muatan dan vektor tanpa menyebutkan secara eksplisit.
Hasil pencarian akan ditampilkan di dalam bidang lookup di bawah setiap kelompok.
{
"result": {
"groups": [
{
"id": 1,
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 1,
"payload": {
"title": "Dokumen A",
"text": "Ini adalah dokumen A"
}
}
},
{
"id": 2,
"hits": [
{ "id": 1, "score": 0.85 }
],
"lookup": {
"id": 2,
"payload": {
"title": "Dokumen B",
"text": "Ini adalah dokumen B"
}
}
}
]
},
"status": "ok",
"time": 0.001
}
Karena pencarian dilakukan dengan mencocokkan langsung ID poin, segala ID kelompok yang tidak ada (dan valid) sebagai ID poin akan diabaikan, dan bidang lookup akan menjadi kosong.