Pesquisa de Similaridade
Em muitas aplicações de aprendizado de máquina, a busca pelos vetores mais próximos é um elemento essencial. As redes neurais modernas são treinadas para transformar objetos em vetores, tornando objetos próximos no espaço vetorial também próximos no mundo real. Por exemplo, textos com significados semelhantes, imagens visualmente semelhantes ou músicas pertencentes ao mesmo gênero.
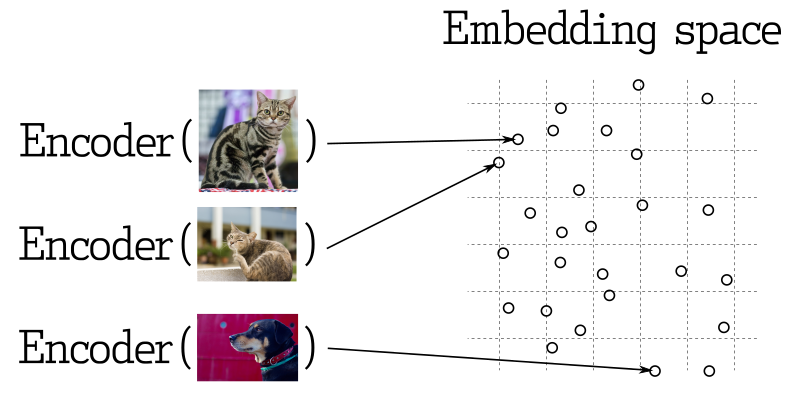
Medição de Similaridade
Existem muitos métodos para avaliar a similaridade entre vetores. No Qdrant, esses métodos são chamados de medições de similaridade. A escolha da medição depende de como os vetores são obtidos, especialmente o método usado para treinar o codificador da rede neural.
O Qdrant suporta os seguintes tipos mais comuns de medições:
- Produto escalar:
Dot - Similaridade cosseno:
Cosine - Distância euclidiana:
Euclid
A medição mais comumente utilizada em modelos de aprendizado de similaridade é a medição de cosseno.
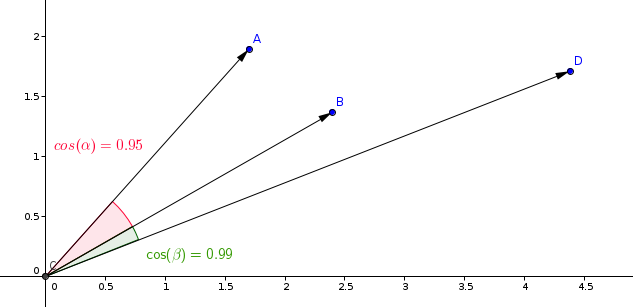
O Qdrant calcula esta medição em duas etapas, alcançando assim maiores velocidades de busca. A primeira etapa é normalizar os vetores ao adicioná-los à coleção. Isso é feito apenas uma vez para cada vetor.
A segunda etapa é a comparação de vetores. Neste caso, é equivalente a uma operação de produto escalar, devido às rápidas operações do SIMD.
Plano de Consulta
Dependendo dos filtros usados na pesquisa, existem vários cenários possíveis para a execução da consulta. O Qdrant seleciona uma das opções de execução de consulta com base nos índices disponíveis, na complexidade das condições e na cardinalidade dos resultados filtrados. Esse processo é chamado de planejamento de consulta.
O processo de seleção da estratégia baseia-se em algoritmos heurísticos e pode variar de acordo com a versão. No entanto, os princípios gerais são:
- Executar planos de consulta independentemente para cada segmento (para obter informações detalhadas sobre segmentos, consulte o armazenamento).
- Priorizar varreduras completas se o número de pontos for baixo.
- Estimar a cardinalidade dos resultados filtrados antes de selecionar uma estratégia.
- Utilizar índices de dados para recuperar pontos se a cardinalidade for baixa (consulte índices).
- Utilizar índices de vetores filtráveis se a cardinalidade for alta.
Os limiares podem ser ajustados independentemente para cada coleção por meio do arquivo de configuração.
API de Busca
Vamos dar uma olhada em um exemplo de consulta de busca.
REST API - As definições de esquema da API podem ser encontradas aqui.
POST /collections/{nome_da_coleção}/points/search
{
"filter": {
"must": [
{
"key": "cidade",
"match": {
"value": "Londres"
}
}
]
},
"params": {
"hnsw_ef": 128,
"exact": false
},
"vector": [0.2, 0.1, 0.9, 0.7],
"limit": 3
}
Neste exemplo, estamos buscando vetores semelhantes ao vetor [0.2, 0.1, 0.9, 0.7]. O parâmetro limit (ou seu alias top) especifica o número de resultados mais similares que desejamos recuperar.
Os valores sob a chave params especificam parâmetros personalizados de busca. Os parâmetros atualmente disponíveis são:
-
hnsw_ef- especifica o valor do parâmetroefpara o algoritmo HNSW. -
exact- indica se deve ser usada a opção de busca exata (ANN). Se definido como True, a busca pode levar muito tempo, pois realiza uma varredura completa para obter resultados exatos. -
indexed_only- ao usar esta opção, é possível desativar a busca em segmentos que ainda não construíram um índice de vetor. Isso pode ser útil para minimizar o impacto no desempenho da busca durante as atualizações. O uso dessa opção pode resultar em resultados parciais se a coleção não estiver totalmente indexada, portanto, use-a apenas nos casos em que a consistência eventual aceitável seja necessária.
Como o parâmetro filter está especificado, a busca é realizada apenas entre os pontos que atendem aos critérios de filtragem. Para informações mais detalhadas sobre possíveis filtros e suas funcionalidades, consulte a seção Filtros.
Um resultado de exemplo para esta API pode se parecer com isto:
{
"result": [
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
"status": "ok",
"time": 0.001
}
O result contém uma lista de pontos descobertos ordenados por score.
Observe que, por padrão, esses resultados não incluem dados de carga útil e vetores. Consulte a seção Carga útil e Vetor em Resultados para saber como incluir carga útil e vetores nos resultados.
Disponível a partir da versão v0.10.0
Se uma coleção for criada com múltiplos vetores, o nome do vetor a ser usado para a busca deve ser fornecido:
POST /collections/{nome_da_coleção}/points/search
{
"vector": {
"name": "imagem",
"vector": [0.2, 0.1, 0.9, 0.7]
},
"limit": 3
}
A busca é realizada apenas entre vetores com o mesmo nome.
Filtrar Resultados por Score
Além da filtragem de carga útil, pode ser útil também filtrar resultados com baixos escores de similaridade. Por exemplo, se você conhece o escore mínimo aceitável para um modelo e não deseja quaisquer resultados de similaridade abaixo do limite, você pode usar o parâmetro score_threshold para a consulta de busca. Ele excluirá todos os resultados com escores inferiores ao valor especificado.
Este parâmetro pode excluir tanto escores mais baixos quanto mais altos, dependendo da métrica usada. Por exemplo, escores mais altos na métrica euclidiana são considerados mais distantes e, portanto, serão excluídos.
Carga Útil e Vetores em Resultados
Por padrão, o método de recuperação não retorna nenhuma informação armazenada, como carga útil e vetores. Parâmetros adicionais with_vectors e with_payload podem modificar esse comportamento.
Exemplo:
POST /collections/{nome_da_coleção}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true
}
O parâmetro with_payload também pode ser usado para incluir ou excluir campos específicos:
POST /collections/{nome_da_coleção}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_payload": {
"exclude": ["cidade"]
}
}
API de Busca em Lote
Disponível a partir da v0.10.0
A API de busca em lote permite a execução de múltiplas solicitações de busca por meio de uma única solicitação.
Sua semântica é simples, n solicitações de busca em lote são equivalentes a n solicitações de busca separadas.
Este método possui várias vantagens. Logicamente, requer menos conexões de rede, o que é benéfico por si só.
Mais importante ainda, se as solicitações em lote possuírem o mesmo filtro, a solicitação em lote será tratada de forma eficiente e otimizada pelo planejador de consultas.
Isso tem um impacto significativo na latência para filtros não triviais, pois os resultados intermediários podem ser compartilhados entre as solicitações.
Para usá-lo, basta agrupar suas solicitações de busca. Claro, todos os atributos regulares de solicitação de busca estão disponíveis.
POST /collections/{nome_da_colecao}/pontos/busca/em_lote
{
"buscas": [
{
"filtro": {
"deve": [
{
"chave": "cidade",
"correspondencia": {
"valor": "Londres"
}
}
]
},
"vetor": [0.2, 0.1, 0.9, 0.7],
"limite": 3
},
{
"filtro": {
"deve": [
{
"chave": "cidade",
"correspondencia": {
"valor": "Londres"
}
}
]
},
"vetor": [0.5, 0.3, 0.2, 0.3],
"limite": 3
}
]
}
Os resultados desta API contêm um array para cada solicitação de busca.
{
"resultado": [
[
{ "id": 10, "pontuacao": 0.81 },
{ "id": 14, "pontuacao": 0.75 },
{ "id": 11, "pontuacao": 0.73 }
],
[
{ "id": 1, "pontuacao": 0.92 },
{ "id": 3, "pontuacao": 0.89 },
{ "id": 9, "pontuacao": 0.75 }
]
],
"status": "ok",
"tempo": 0.001
}
API Recomendada
O vetor negativo é um recurso experimental e não é garantido que funcione com todos os tipos de embeddings. Além das buscas regulares, o Qdrant também permite a busca com base em múltiplos vetores já armazenados em uma coleção. Esta API é usada para busca vetorial de objetos codificados sem envolver codificadores de rede neural.
A API Recomendada permite que você especifique múltiplos IDs de vetores positivos e negativos, e o serviço irá mesclá-los em um vetor médio específico.
vetor_medio = avg(vetores_positivos) + ( avg(vetores_positivos) - avg(vetores_negativos) )
Se apenas um ID positivo for fornecido, esta solicitação é equivalente a uma busca regular pelo vetor daquele ponto.
Componentes do vetor com valores mais altos no vetor negativo são penalizados, enquanto os componentes do vetor com valores mais altos no vetor positivo são amplificados. Este vetor médio é então usado para encontrar os vetores mais semelhantes na coleção.
A definição da API de esquema para a API REST pode ser encontrada aqui.
POST /collections/{nome_da_colecao}/pontos/recomendar
{
"filtro": {
"deve": [
{
"chave": "cidade",
"correspondencia": {
"valor": "Londres"
}
}
]
},
"negativo": [718],
"positivo": [100, 231],
"limite": 10
}
O resultado da amostra para esta API será o seguinte:
{
"resultado": [
{ "id": 10, "pontuacao": 0.81 },
{ "id": 14, "pontuacao": 0.75 },
{ "id": 11, "pontuacao": 0.73 }
],
"status": "ok",
"tempo": 0.001
}
Disponível a partir da v0.10.0 em diante
Se a coleção for criada usando múltiplos vetores, os nomes dos vetores a serem usados devem ser especificados na solicitação de recomendação:
POST /collections/{nome_da_colecao}/pontos/recomendar
{
"positivo": [100, 231],
"negativo": [718],
"usando": "imagem",
"limite": 10
}
O parâmetro usando especifica o vetor armazenado a ser usado para a recomendação.
API Batch Recomendado
Disponível a partir da versão v0.10.0
Similar à API de pesquisa em lote, com uso e benefícios similares, pode processar solicitações de recomendação em lote.
POST /collections/{collection_name}/points/recommend/batch
{
"searches": [
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"negative": [718],
"positive": [100, 231],
"limit": 10
},
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Londres"
}
}
]
},
"negative": [300],
"positive": [200, 67],
"limit": 10
}
]
}
O resultado desta API contém uma matriz para cada solicitação de recomendação.
{
"result": [
[
{ "id": 10, "score": 0.81 },
{ "id": 14, "score": 0.75 },
{ "id": 11, "score": 0.73 }
],
[
{ "id": 1, "score": 0.92 },
{ "id": 3, "score": 0.89 },
{ "id": 9, "score": 0.75 }
]
],
"status": "ok",
"time": 0.001
}
Paginação
Disponível a partir da versão v0.8.3
A API de pesquisa e recomendação permite pular os primeiros resultados da pesquisa e retornar apenas os resultados a partir de um deslocamento específico.
Exemplo:
POST /collections/{collection_name}/points/search
{
"vector": [0.2, 0.1, 0.9, 0.7],
"with_vectors": true,
"with_payload": true,
"limit": 10,
"offset": 100
}
Isso é equivalente a recuperar a 11ª página, com 10 registros por página.
Um grande valor de deslocamento pode levar a problemas de desempenho, e o método de recuperação baseado em vetores geralmente não oferece suporte à paginação. Sem recuperar os primeiros N vetores, não é possível recuperar o vetor mais próximo N.
No entanto, o uso do parâmetro de deslocamento pode economizar recursos, reduzindo o tráfego de rede e o acesso ao armazenamento.
Ao utilizar o parâmetro offset, é necessário recuperar internamente offset + limit pontos, mas somente acessar os paylods e vetores desses pontos que realmente são retornados do armazenamento.
API de Agrupamento
Disponível a partir da versão v1.2.0
Os resultados podem ser agrupados com base em um campo específico. Isso será muito útil quando você tiver vários pontos para o mesmo item e quiser evitar entradas redundantes nos resultados.
Por exemplo, se você tiver um documento grande dividido em vários pedaços e quiser pesquisar ou recomendar com base em cada documento, pode agrupar os resultados pelo ID do documento.
Suponha que haja pontos com cargas úteis:
{
{
"id": 0,
"payload": {
"chunk_part": 0,
"document_id": "a",
},
"vector": [0.91],
},
{
"id": 1,
"payload": {
"chunk_part": 1,
"document_id": ["a", "b"],
},
"vector": [0.8],
},
{
"id": 2,
"payload": {
"chunk_part": 2,
"document_id": "a",
},
"vector": [0.2],
},
{
"id": 3,
"payload": {
"chunk_part": 0,
"document_id": 123,
},
"vector": [0.79],
},
{
"id": 4,
"payload": {
"chunk_part": 1,
"document_id": 123,
},
"vector": [0.75],
},
{
"id": 5,
"payload": {
"chunk_part": 0,
"document_id": -10,
},
"vector": [0.6],
},
}
Usando a API groups, você poderá buscar os principais N pontos para cada documento, assumindo que a carga útil do ponto contenha o ID do documento. Claro, pode haver casos em que os melhores N pontos não possam ser satisfeitos devido à falta de pontos ou distância relativamente grande da consulta. Em cada caso, group_size é um parâmetro de melhor esforço, similar ao parâmetro limit.
Pesquisa de Grupo
API REST (Esquema):
POST /collections/{collection_name}/points/search/groups
{
// Mesmo que a API de pesquisa regular
"vector": [1.1],
...,
// Parâmetros de agrupamento
"group_by": "document_id", // O caminho do campo para agrupar por
"limit": 4, // Número máximo de grupos
"group_size": 2, // Número máximo de pontos por grupo
}
Recomendação de Grupo
API REST (Esquema):
POST /coleções/{nome_da_coleção}/pontos/recomendar/grupos
{
// Mesmo que a API de recomendação regular
"negativo": [1],
"positivo": [2, 5],
...,
// Parâmetros de agrupamento
"agrupar_por": "id_do_documento", // O caminho do campo para agrupar
"limite": 4, // Número máximo de grupos
"tamanho_do_grupo": 2 // Número máximo de pontos por grupo
}
Independentemente de ser uma pesquisa ou recomendação, os resultados de saída são os seguintes:
{
"resultado": {
"grupos": [
{
"id": "a",
"hits": [
{ "id": 0, "score": 0.91 },
{ "id": 1, "score": 0.85 }
]
},
{
"id": "b",
"hits": [
{ "id": 1, "score": 0.85 }
]
},
{
"id": 123,
"hits": [
{ "id": 3, "score": 0.79 },
{ "id": 4, "score": 0.75 }
]
},
{
"id": -10,
"hits": [
{ "id": 5, "score": 0.6 }
]
}
]
},
"status": "ok",
"tempo": 0.001
}
Os grupos são classificados pelo maior score dos pontos dentro de cada grupo. Dentro de cada grupo, os pontos também são classificados.
Se o campo agrupar_por de um ponto for um array (por exemplo, "id_do_documento": ["a", "b"]), o ponto pode ser incluído em vários grupos (por exemplo, "id_do_documento": "a" e id_do_documento: "b").
Esta funcionalidade depende fortemente da chave agrupar_por fornecida. Para melhorar o desempenho, garanta que seja criado um índice dedicado para ele. Restrições:
- O parâmetro
agrupar_porsuporta apenas valores de carga útil de palavra-chave e inteiro. Outros tipos de valores de carga útil serão ignorados. - Atualmente, a paginação não é suportada ao usar grupos, portanto o parâmetro
offsetnão é permitido.
Pesquisa dentro de Grupos
Disponível desde a versão v1.3.0
Nos casos em que há vários pontos para diferentes partes do mesmo item, a redundância geralmente é introduzida nos dados armazenados. Se a informação compartilhada entre os pontos for mínima, isso pode ser aceitável. No entanto, pode se tornar problemático com cargas mais pesadas, pois irá calcular o espaço de armazenamento necessário para os pontos com base no número de pontos no grupo.
Uma otimização para o armazenamento ao usar grupos é armazenar a informação compartilhada entre os pontos com base no mesmo ID de grupo em um único ponto dentro de outra coleção. Em seguida, ao utilizar a API de grupos, adicione o parâmetro with_lookup para adicionar essa informação para cada grupo.
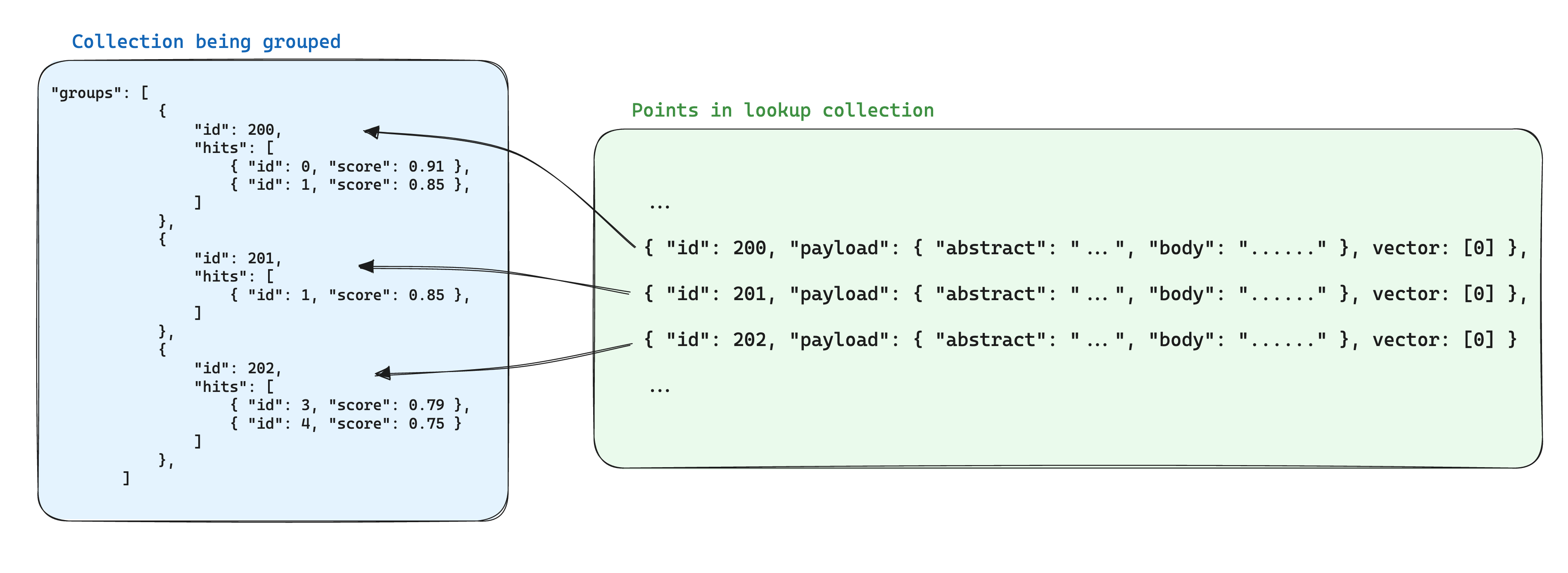
Um benefício adicional dessa abordagem é que, quando a informação compartilhada dentro dos pontos do grupo muda, apenas o ponto único precisa ser atualizado.
Por exemplo, se você tem uma coleção de documentos, pode querer dividi-los e armazenar os pontos pertencentes a esses pedaços em uma coleção separada, garantindo que os IDs dos pontos pertencentes aos documentos sejam armazenados na carga útil do ponto do pedaço.
Nesse cenário, para trazer as informações dos documentos para os pedaços agrupados pelo ID do documento, o parâmetro with_lookup pode ser usado:
POST /coleções/pedaços/pontos/pesquisa/grupos
{
// Mesmos parâmetros que na API de pesquisa regular
"vetor": [1.1],
...,
// Parâmetros de agrupamento
"agrupar_por": "id_do_documento",
"limite": 2,
"tamanho_do_grupo": 2,
// Parâmetros de pesquisa
"with_lookup": {
// Nome da coleção dos pontos a serem pesquisados
"coleção": "documentos",
// Opções especificando o conteúdo para trazer da carga útil dos pontos de pesquisa, o padrão é true
"com_carga_útil": ["título", "texto"],
// Opções especificando o conteúdo para trazer dos vetores dos pontos de pesquisa, o padrão é true
"com_vetores": false
}
}
Para o parâmetro with_lookup, também pode ser usada a forma abreviada with_lookup="documentos" para trazer toda a carga útil e vetores sem especificar explicitamente.
Os resultados da pesquisa serão exibidos no campo lookup embaixo de cada grupo.
{
"resultado": {
"grupos": [
{
"id": 1,
"resultados": [
{ "id": 0, "pontuação": 0.91 },
{ "id": 1, "pontuação": 0.85 }
],
"lookup": {
"id": 1,
"carga_útil": {
"título": "Documento A",
"texto": "Este é o documento A"
}
}
},
{
"id": 2,
"resultados": [
{ "id": 1, "pontuação": 0.85 }
],
"lookup": {
"id": 2,
"carga_útil": {
"título": "Documento B",
"texto": "Este é o documento B"
}
}
}
]
},
"status": "ok",
"tempo": 0.001
}
Como a pesquisa é feita correspondendo diretamente os IDs dos pontos, quaisquer IDs de grupo que não sejam IDs de pontos existentes (e válidos) serão ignorados, e o campo lookup ficará vazio.