
A vector database is a relatively new way of interacting with abstract data representations, which come from opaque machine learning models such as deep learning structures. These representations are commonly referred to as vectors or embedding vectors, and they are compressed versions of the data used to train machine learning models to perform tasks such as sentiment analysis, speech recognition, and object detection.
These new databases have shown outstanding performance in many applications, such as semantic search and recommendation systems.
What is Qdrant?
Qdrant is an open-source vector database designed for next-generation AI applications. It is cloud-native and provides RESTful and gRPC APIs for managing embeddings. Qdrant boasts powerful features, supporting image, voice, and video search, as well as integration with AI engines.
What is a Vector Database?
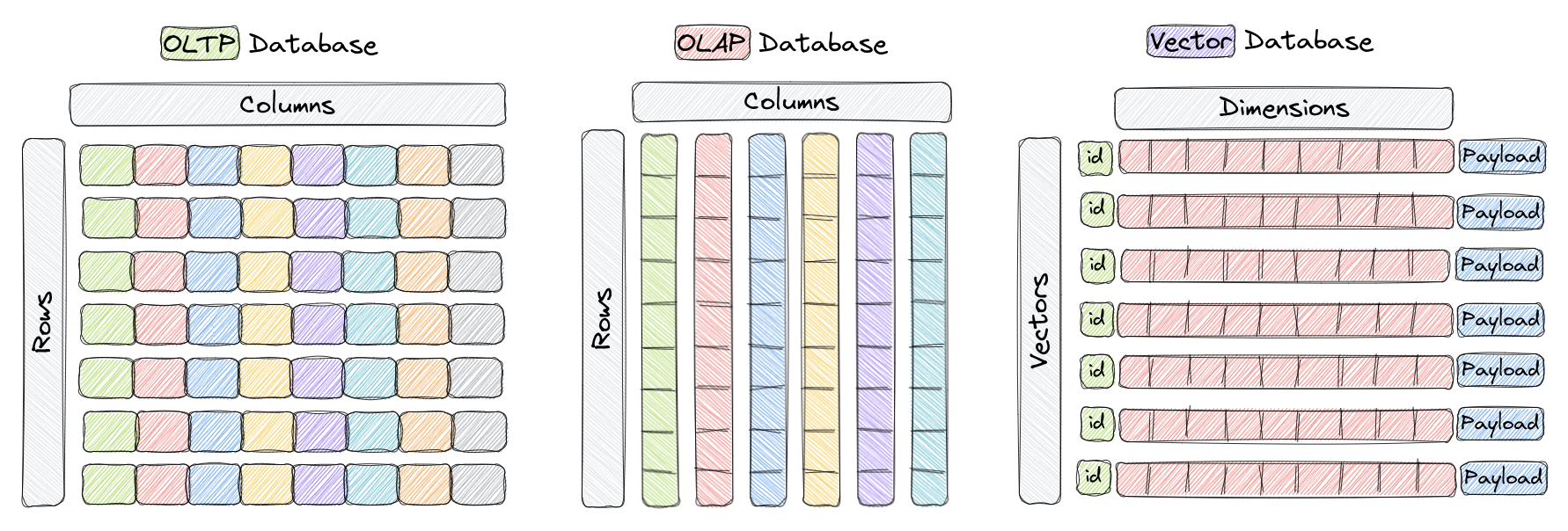
A vector database is a type of database specifically designed for efficient storage and querying of high-dimensional vectors. In traditional OLTP and OLAP databases (as shown in the above figure), data is organized in rows and columns (referred to as tables), and queries are based on the values in these columns. However, in certain applications such as image recognition, natural language processing, and recommendation systems, data is often represented in the form of vectors in high-dimensional space. These vectors, along with an ID and payload, constitute the elements stored in vector databases like Qdrant.
In this context, a vector is the mathematical representation of an object or data point, where each element of the vector corresponds to a feature or attribute of the object. For example, in an image recognition system, a vector can represent an image, with each element of the vector representing pixel values or the pixel's feature/descriptor. In a music recommendation system, each vector represents a song, with each element of the vector representing a feature of the song, such as rhythm, genre, lyrics, etc.
Vector databases are optimized for efficient storage and querying of high-dimensional vectors, often utilizing specialized data structures and indexing techniques such as Hierarchical Navigable Small World (HNSW) for approximate nearest neighbor search and Product Quantization. These databases can allow users to find the nearest vectors to a given query vector according to a certain distance metric, enabling fast similarity and semantic search. The most commonly used distance metrics include Euclidean distance, cosine similarity, and dot product, all fully supported in Qdrant.
Here is a brief introduction to these three vector similarity algorithms:
- Cosine Similarity - Cosine similarity is a measure of similarity between two items. It can be viewed as a ruler used to measure the distance between two points; however, instead of measuring distance, it measures the similarity between two items. It is commonly used in comparing the similarity between two documents or sentences in text. The output range of cosine similarity is from 0 to 1, where 0 indicates complete dissimilarity and 1 indicates complete similarity. It is a simple and effective way to compare two items!
- Dot Product - Dot product similarity is another measure of similarity between two items, similar to cosine similarity. In dealing with numbers, it is often used in machine learning and data science. Dot product similarity calculates by multiplying the values in two sets of numbers and then adding up these products. A higher sum indicates a higher similarity between the two sets of numbers. It is like a scale that measures the degree of matching between two sets of numbers.
- Euclidean Distance - Euclidean distance is a way of measuring the distance between two points in space, similar to how we measure the distance between two places on a map. It is calculated by finding the square root of the sum of the squares of the differences between the coordinates of the two points. This distance measurement method is commonly used in machine learning to assess the similarity or dissimilarity of two data points, in other words, to understand how far apart they are.
Now that we know what vector databases are and how they differ structurally from other databases, let's understand why they are important.
Why do we need a vector database?
Vector databases play a crucial role in various applications that require similarity search, such as recommendation systems, content-based image retrieval, and personalized search. By leveraging efficient indexing and search techniques, vector databases can retrieve unstructured data represented as vectors faster and more accurately, presenting the most relevant results to the user's query.
Additionally, other benefits of using a vector database include:
- Efficient storage and indexing of high-dimensional data.
- Capability to handle large-scale datasets with billions of data points.
- Support for real-time analysis and queries.
- Ability to handle vectors derived from complex data types such as images, videos, and natural language texts.
- Improvement in the performance of machine learning and artificial intelligence applications while reducing latency.
- Reduction in development and deployment time and costs compared to building custom solutions.
Please note that the specific benefits of using a vector database may vary depending on your organization's use cases and the chosen database functionalities.
Now, let's take a high-level assessment of the Qdrant architecture.
High-Level Overview of Qdrant Architecture
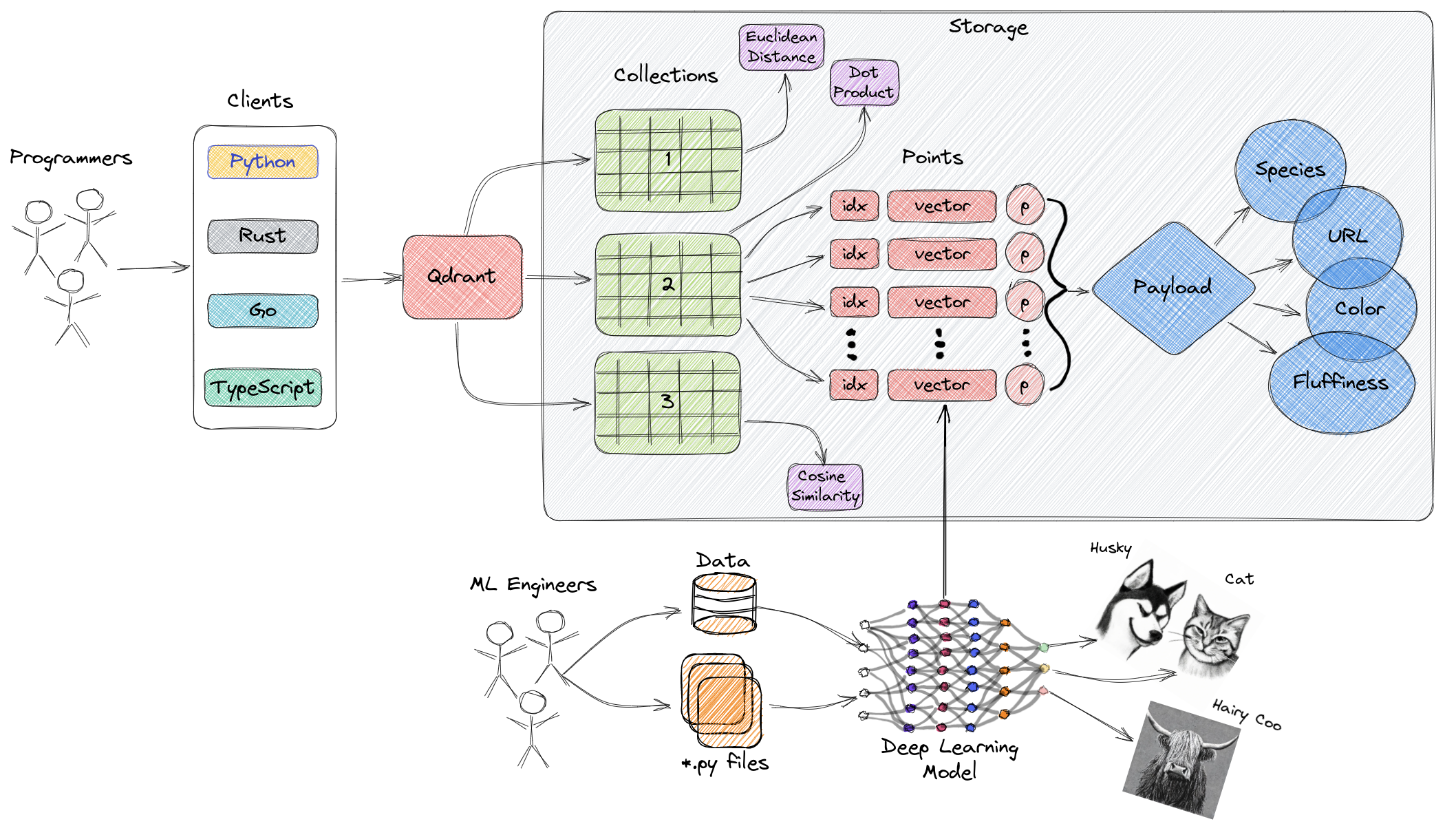
The above diagram provides a high-level overview of the main components of Qdrant. The following are key terms related to Qdrant:
- Collections: Collections are a group of named points (vectors with payloads—essentially vector data). In simpler terms, collections are similar to tables in MySQL, and points are similar to the rows of data within those tables. Searching can be performed among these points. Each vector within the same collection must have the same dimension and be compared using a single metric. Named vectors can be used to have multiple vectors in a single point, each with its own dimension and metric requirements.
- Metric: A measure used to quantify the similarity between vectors, which must be selected when creating a collection. The choice of metric depends on the method of vector acquisition, particularly for neural networks used to encode new queries (the metric is the similarity algorithm we choose).
- Points: Points are the core entities operated on by Qdrant, composed of vectors, optional IDs, and payloads (akin to rows of data in a MySQL table).
- ID: Unique identifier of the vector.
- Vector: High-dimensional representation of data, such as images, audio, documents, videos, etc.
- Payload: A JSON object that can be added to the vector as additional data (primarily used for storing business properties associated with the vector).
- Storage: Qdrant can utilize two storage options—in-memory storage (all vectors stored in memory, providing the highest speed, as disk access is only used for persistence) and Memmap storage (creating a virtual address space associated with files on disk).
- Clients: You can connect to Qdrant using programming language SDKs or directly interact with Qdrant using its REST API.