
Um banco de dados de vetores é uma forma relativamente nova de interagir com representações de dados abstratos, que advêm de modelos de machine learning opacos, como estruturas de deep learning. Essas representações são comumente referidas como vetores ou vetores de incorporação, e são versões comprimidas dos dados usados para treinar modelos de machine learning a realizar tarefas como análise de sentimentos, reconhecimento de fala e detecção de objetos.
Esses novos bancos de dados têm mostrado um desempenho excepcional em muitas aplicações, como busca semântica e sistemas de recomendação.
O que é o Qdrant?
O Qdrant é um banco de dados de vetores de código aberto projetado para aplicações de IA de próxima geração. Ele é nativo da nuvem e fornece APIs RESTful e gRPC para gerenciar incorporações. O Qdrant possui recursos poderosos, oferecendo suporte à busca de imagens, voz e vídeo, bem como integração com motores de IA.
O que é um Banco de Dados de Vetores?
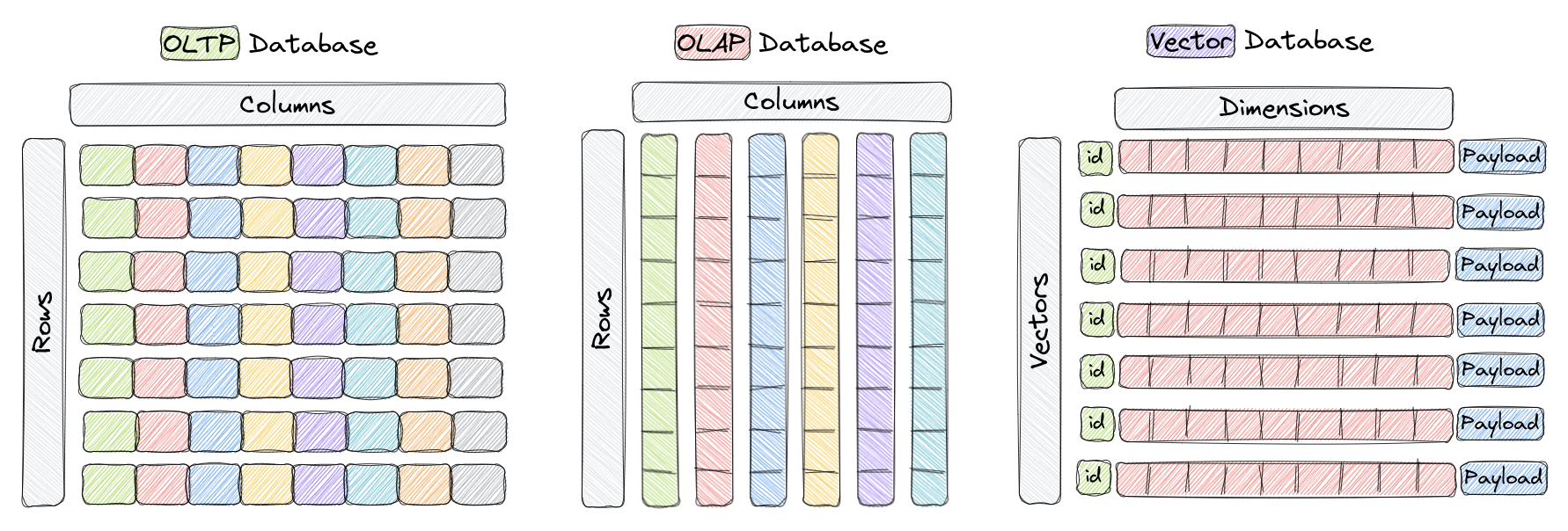
Um banco de dados de vetores é um tipo de banco de dados projetado especificamente para armazenamento eficiente e consulta de vetores de alta dimensionalidade. Em bancos de dados tradicionais OLTP e OLAP (conforme mostrado na figura acima), os dados são organizados em linhas e colunas (denominadas tabelas), e as consultas são baseadas nos valores dessas colunas. No entanto, em determinadas aplicações, como reconhecimento de imagens, processamento de linguagem natural e sistemas de recomendação, os dados frequentemente são representados na forma de vetores em um espaço de alta dimensionalidade. Esses vetores, juntamente com um ID e carga útil, constituem os elementos armazenados em bancos de dados de vetores como o Qdrant.
Neste contexto, um vetor é a representação matemática de um objeto ou ponto de dados, onde cada elemento do vetor corresponde a um atributo do objeto. Por exemplo, em um sistema de reconhecimento de imagens, um vetor pode representar uma imagem, sendo que cada elemento do vetor representa valores de pixel ou o recurso/descrição do pixel. Em um sistema de recomendação de música, cada vetor representa uma música, sendo que cada elemento do vetor representa um recurso da música, como ritmo, gênero, letras, etc.
Bancos de dados de vetores são otimizados para armazenamento eficiente e consulta de vetores de alta dimensionalidade, frequentemente utilizando estruturas de dados e técnicas de indexação especializadas, como Hierarchical Navigable Small World (HNSW) para busca aproximada de vizinho mais próximo e Quantização de Produto. Esses bancos de dados permitem que os usuários encontrem os vetores mais próximos de um vetor de consulta específico de acordo com uma determinada métrica de distância, possibilitando uma busca rápida de similaridade e semântica. As métricas de distância mais comumente usadas incluem distância euclidiana, similaridade de cosseno e produto escalar, todas totalmente suportadas no Qdrant.
Aqui está uma breve introdução a esses três algoritmos de similaridade de vetores:
- Similaridade de Cosseno - A similaridade de cosseno é uma medida de similaridade entre dois itens. Pode ser vista como uma régua usada para medir a distância entre dois pontos; no entanto, em vez de medir a distância, mede a similaridade entre dois itens. É comumente usada para comparar a similaridade entre dois documentos ou frases de texto. A faixa de saída da similaridade de cosseno é de 0 a 1, onde 0 indica completa dissimilaridade e 1 indica completa similaridade. É uma forma simples e eficaz de comparar dois itens!
- Produto Escalar - A similaridade do produto escalar é outra medida de similaridade entre dois itens, semelhante à similaridade de cosseno. Ao lidar com números, é frequentemente usada em machine learning e ciência de dados. A similaridade do produto escalar é calculada multiplicando os valores em dois conjuntos de números e depois somando esses produtos. Uma soma maior indica uma maior similaridade entre os dois conjuntos de números. É como uma escala que mede o grau de correspondência entre dois conjuntos de números.
- Distância Euclidiana - A distância euclidiana é uma forma de medir a distância entre dois pontos no espaço, semelhante à forma como medimos a distância entre dois lugares em um mapa. É calculada encontrando a raiz quadrada da soma dos quadrados das diferenças entre as coordenadas dos dois pontos. Este método de medição de distância é comumente usado em machine learning para avaliar a similaridade ou dissimilaridade de dois pontos de dados, em outras palavras, para entender quão distantes eles estão.
Agora que sabemos o que são bancos de dados de vetores e como eles diferem estruturalmente de outros bancos de dados, vamos entender por que são importantes.
Por que precisamos de um banco de dados de vetores?
Bancos de dados de vetores desempenham um papel crucial em várias aplicações que requerem busca por similaridade, como sistemas de recomendação, recuperação de imagens baseada em conteúdo e busca personalizada. Por meio da alavancagem de técnicas eficientes de indexação e busca, os bancos de dados de vetores podem recuperar dados não estruturados representados como vetores de forma mais rápida e precisa, apresentando os resultados mais relevantes para a consulta do usuário.
Além disso, outros benefícios de usar um banco de dados de vetores incluem:
- Armazenamento e indexação eficientes de dados de alta dimensionalidade.
- Capacidade de lidar com conjuntos de dados em grande escala com bilhões de pontos de dados.
- Suporte para análises e consultas em tempo real.
- Capacidade de lidar com vetores derivados de tipos de dados complexos, como imagens, vídeos e textos em linguagem natural.
- Melhoria no desempenho de aplicativos de aprendizado de máquina e inteligência artificial, ao mesmo tempo em que reduz a latência.
- Redução no tempo e nos custos de desenvolvimento e implantação em comparação com a construção de soluções personalizadas.
Por favor, observe que os benefícios específicos de usar um banco de dados de vetores podem variar dependendo dos casos de uso da sua organização e das funcionalidades de banco de dados escolhidas.
Agora, vamos fazer uma avaliação de alto nível da arquitetura do Qdrant.
Visão Geral da Arquitetura do Qdrant
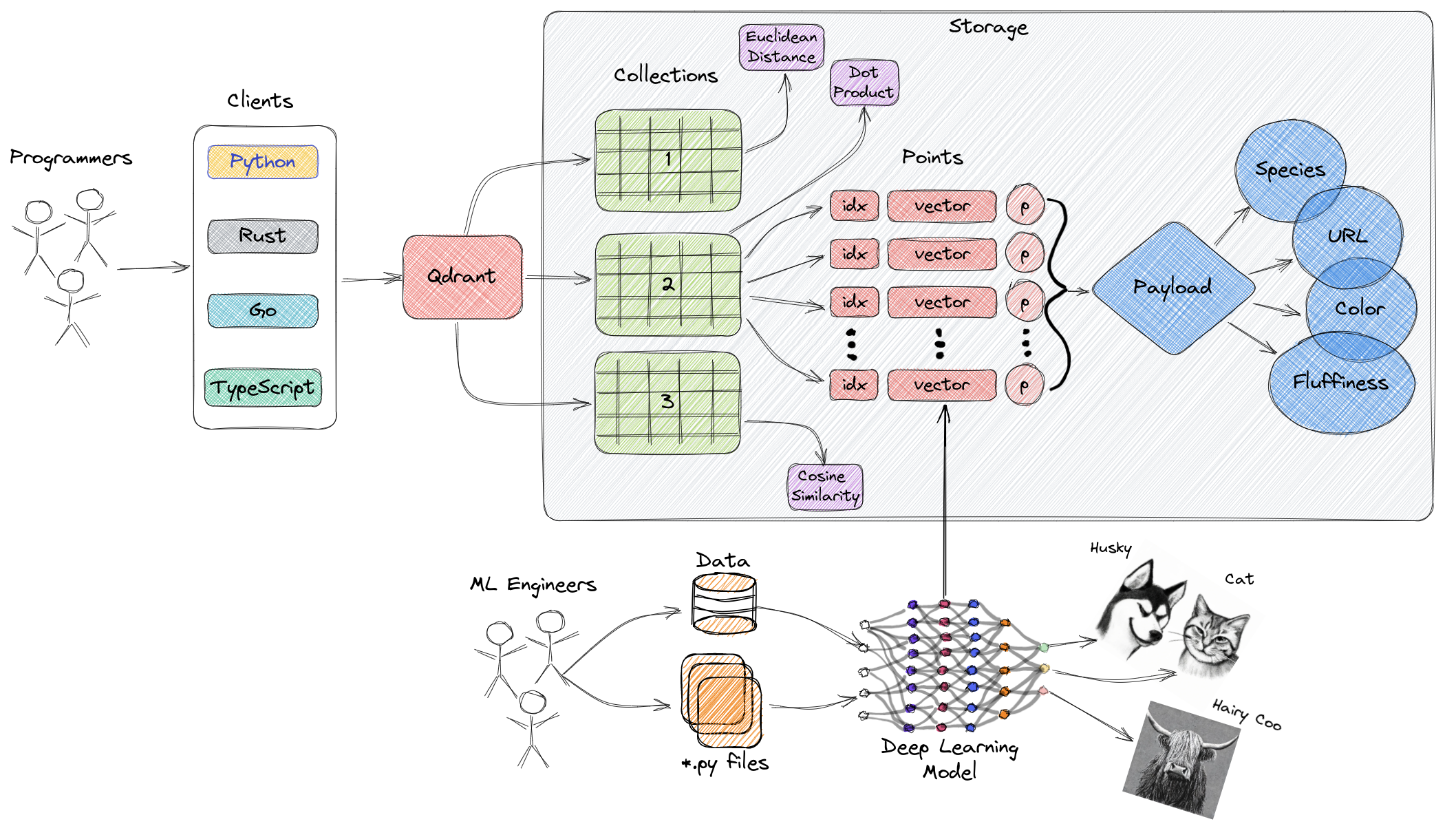
O diagrama acima fornece uma visão geral dos principais componentes do Qdrant. Os seguintes são termos-chave relacionados ao Qdrant:
- Coleções: Coleções são um grupo de pontos nomeados (vetores com cargas - essencialmente dados de vetor). Em termos mais simples, as coleções são semelhantes a tabelas no MySQL, e os pontos são semelhantes às linhas de dados dentro dessas tabelas. A busca pode ser realizada entre esses pontos. Cada vetor dentro da mesma coleção deve ter a mesma dimensão e ser comparado usando uma única métrica. Vetores nomeados podem ser usados para ter vários vetores em um único ponto, cada um com sua própria dimensão e requisitos métricos.
- Métrica: Uma medida usada para quantificar a similaridade entre vetores, que deve ser selecionada ao criar uma coleção. A escolha da métrica depende do método de aquisição de vetores, especialmente para redes neurais usadas para codificar novas consultas (a métrica é o algoritmo de similaridade que escolhemos).
- Pontos: Pontos são as entidades principais operadas pelo Qdrant, compostas por vetores, IDs opcionais e cargas (semelhante a linhas de dados em uma tabela MySQL).
- ID: Identificador único do vetor.
- Vetor: Representação de alta dimensionalidade de dados, como imagens, áudio, documentos, vídeos, etc.
- Carga: Um objeto JSON que pode ser adicionado ao vetor como dados adicionais (principalmente usado para armazenar propriedades comerciais associadas ao vetor).
- Armazenamento: O Qdrant pode utilizar duas opções de armazenamento - armazenamento em memória (todos os vetores armazenados na memória, fornecendo a maior velocidade, pois o acesso ao disco é usado apenas para persistência) e armazenamento Memmap (criando um espaço de endereço virtual associado a arquivos no disco).
- Clientes: Você pode se conectar ao Qdrant usando SDKs de linguagens de programação ou interagir diretamente com o Qdrant usando sua API REST.