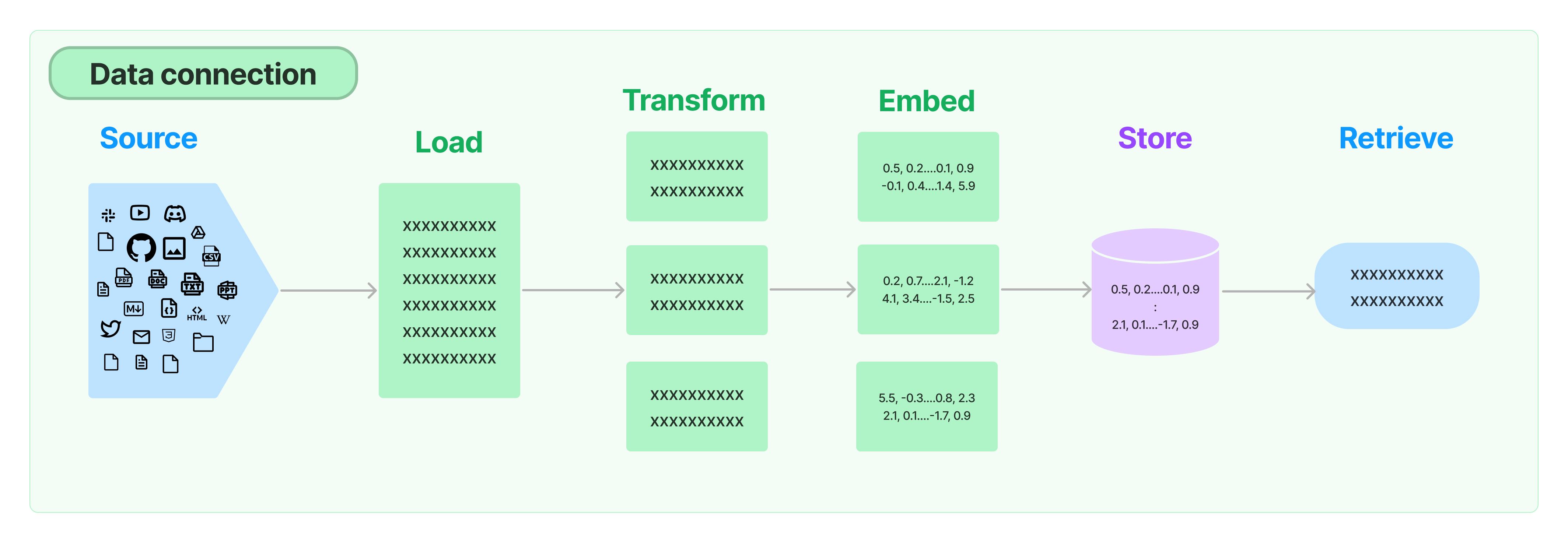
언어 모델 (LM)은 많은 정보를 알고 있지만 기업의 개인 데이터나 새로운 데이터에 대해 알지 못합니다. 많은 LM 응용 프로그램은 기업의 개인 데이터를 쿼리해야 하며, 그런 다음 개인 데이터를 프롬프트에 백그라운드 정보로 결합하여 대규모 모델에 공급하여 백그라운드 정보에 기반한 질문에 답변합니다. LangChain은 데이터로드, 변환, 저장 및 쿼리를 위한 프레임워크 구성 요소를 제공합니다.
LangChain의 개인 데이터 처리 구성 요소는 다음과 같습니다:
- 문서 로더: 다양한 소스에서 문서 데이터를 로드하는 기능을 지원합니다.
- 문서 컨버터: 문서를 분할하고, Q&A 형식으로 변환하며, 중복되는 문서를 제거합니다.
- 텍스트 임베딩 모델: 비구조화된 텍스트를 특징 벡터로 변환하여 질문과 유사한 콘텐츠를 쿼리하는 것을 지원합니다.
- 벡터 스토리지: 벡터 데이터를 저장하고 검색합니다.
- 리트리버: LangChain의 캡슐화된 유틸리티 클래스로, 편리하게 데이터를 쿼리할 수 있습니다.