
ベクトルデータベースは、抽象的なデータ表現とのやり取りを行う比較的新しい方法であり、これらはディープラーニング構造などの不透明な機械学習モデルから来るものです。これらの表現は一般的にベクトルまたは埋め込みベクトルと呼ばれ、感情分析、音声認識、物体検出などのタスクを実行するために機械学習モデルのトレーニングに使用されるデータの圧縮バージョンです。
これらの新しいデータベースは、セマンティック検索や推薦システムなどの多くのアプリケーションで傑出したパフォーマンスを示しています。
Qdrantとは?
Qdrantは、次世代のAIアプリケーション向けに設計されたオープンソースのベクトルデータベースです。クラウドネイティブであり、埋め込みの管理のためのRESTfulおよびgRPC APIを提供しています。Qdrantは、画像、音声、ビデオ検索をサポートし、AIエンジンとの統合も可能です。
ベクトルデータベースとは?
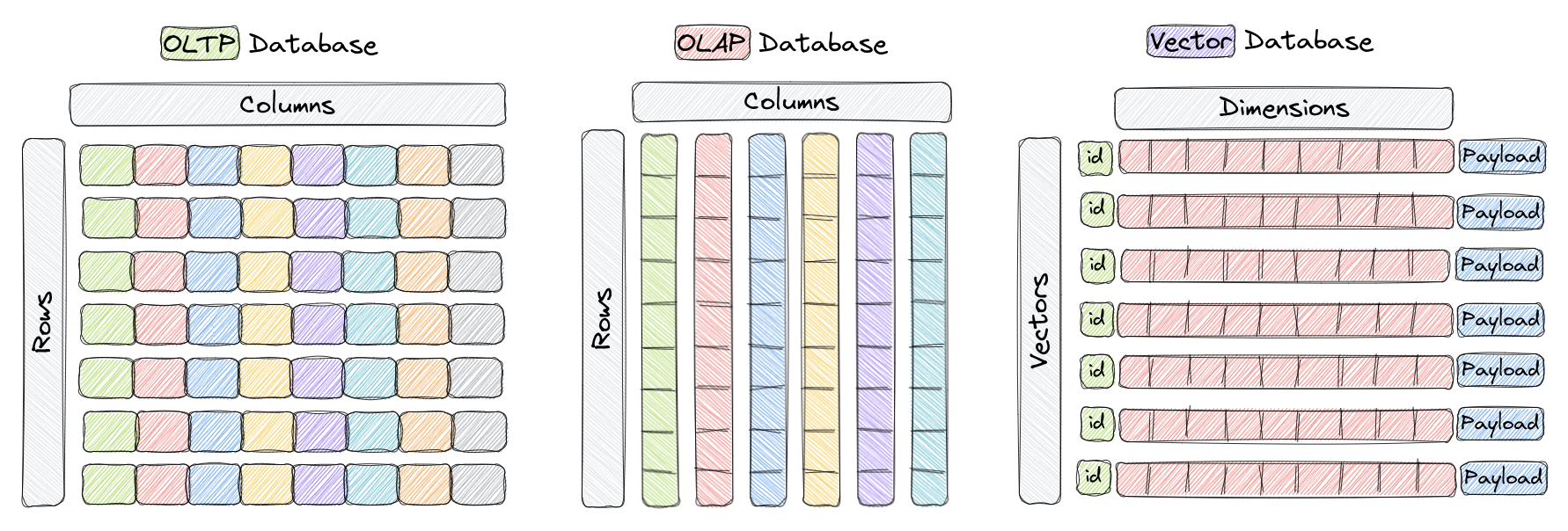
ベクトルデータベースは、高次元ベクトルの効率的な格納とクエリに特化したデータベースの一種です。従来のOLTPおよびOLAPデータベースでは、データは行と列(テーブルと呼ばれます)に組織され、クエリはこれらの列の値に基づいています(上図参照)。しかし、画像認識、自然言語処理、および推薦システムなどの特定のアプリケーションでは、データはしばしば高次元空間のベクトルの形で表されます。これらのベクトルは、IDとペイロードとともにQdrantのようなベクトルデータベースに格納される要素を構成します。
この文脈では、ベクトルはオブジェクトまたはデータポイントの数学的表現であり、ベクトルの各要素はオブジェクトの特徴または属性に対応しています。例えば、画像認識システムでは、ベクトルは画像を表し、ベクトルの各要素はピクセルの値またはピクセルの特徴/記述子を表します。音楽推薦システムでは、各ベクトルは曲を表し、ベクトルの各要素はリズム、ジャンル、歌詞などの曲の特徴を表します。
ベクトルデータベースは、高次元ベクトルの効率的な格納とクエリのために最適化されており、近似最近傍探索のためのHNSW(Hierarchical Navigable Small World)などの特殊なデータ構造とインデックス技術を利用しています。これらのデータベースは、特定の距離メトリクスに従って与えられたクエリベクトルに最も近いベクトルを見つけることを可能にし、高速な類似性や意味検索を実現します。最も一般的に使用される距離メトリクスには、ユークリッド距離、コサイン類似度、およびドット積などがあり、これらはすべてQdrantで完全にサポートされています。
以下は、これらの3つのベクトル類似アルゴリズムの簡単な紹介です:
- コサイン類似度 - コサイン類似度は、2つのアイテム間の類似性を測定します。2つの点の間の距離を測定する定規のようなものであり、距離を測るのではなく、2つのアイテムの類似性を測定します。この距離メトリクスは、テキスト内の2つのドキュメントまたは文章の類似性を比較するために一般的に使用されます。コサイン類似度の出力範囲は0から1で、0は完全な非類似性を、1は完全な類似性を示します。これは2つのアイテムを比較するための単純で効果的な方法です!
- ドット積 - ドット積類似度は、コサイン類似度と同様に、2つのアイテム間の類似性を測定する別の尺度です。数値を扱う際には、機械学習やデータサイエンスでよく使用されます。ドット積類似度は、2つの数値セットの値を掛け合わせてその積を加算することによって計算されます。合計値が高いほど、2つの数値セットの間の類似性が高いことを示します。これは2つの数値セット間の一致度を測定するようなものです。
- ユークリッド距離 - ユークリッド距離は、空間内の2つの点間の距離を測定する方法であり、地図上の2つの場所の距離を測る方法に類似します。これは2つの点の座標の差の二乗の和の平方根を計算して求められます。この距離測定方法は、機械学習で、2つのデータポイントの類似性または非類似性を評価するために一般的に使用され、つまり、それらがどの程度離れているかを理解するために使用されます。
これで、ベクトルデータベースが何であり、その構造が他のデータベースとどのように異なるのかを理解しましたので、なぜそれらが重要なのかを理解しましょう。
ベクトルデータベースが必要な理由
ベクトルデータベースは、類似検索を必要とするさまざまなアプリケーションにおいて重要な役割を果たします。例えばレコメンデーションシステム、コンテンツベースの画像検索、個人向け検索などが挙げられます。効率的なインデックス付けと検索技術を活用することで、ベクトルデータベースは、ユーザーのクエリに最も関連性の高い結果をより速く正確に取得することができます。
さらに、ベクトルデータベースを使用することの他の利点には以下があります:
- 高次元データの効率的な保存とインデックス付け。
- 数十億のデータポイントを扱う大規模データセットの処理能力。
- リアルタイムな分析とクエリのサポート。
- 画像、ビデオ、自然言語テキストなどの複雑なデータ型から派生したベクトルの取り扱い。
- 機械学習および人工知能アプリケーションのパフォーマンス向上とレイテンシーの低減。
- カスタムソリューションの構築に比べて、開発と展開の時間とコストの削減。
ベクトルデータベースの具体的な利点は、組織のユースケースや選択したデータベースの機能に応じて異なることに留意してください。
それでは、Qdrantアーキテクチャの高レベルな評価を行ってみましょう。
Qdrantアーキテクチャの高レベルな概要
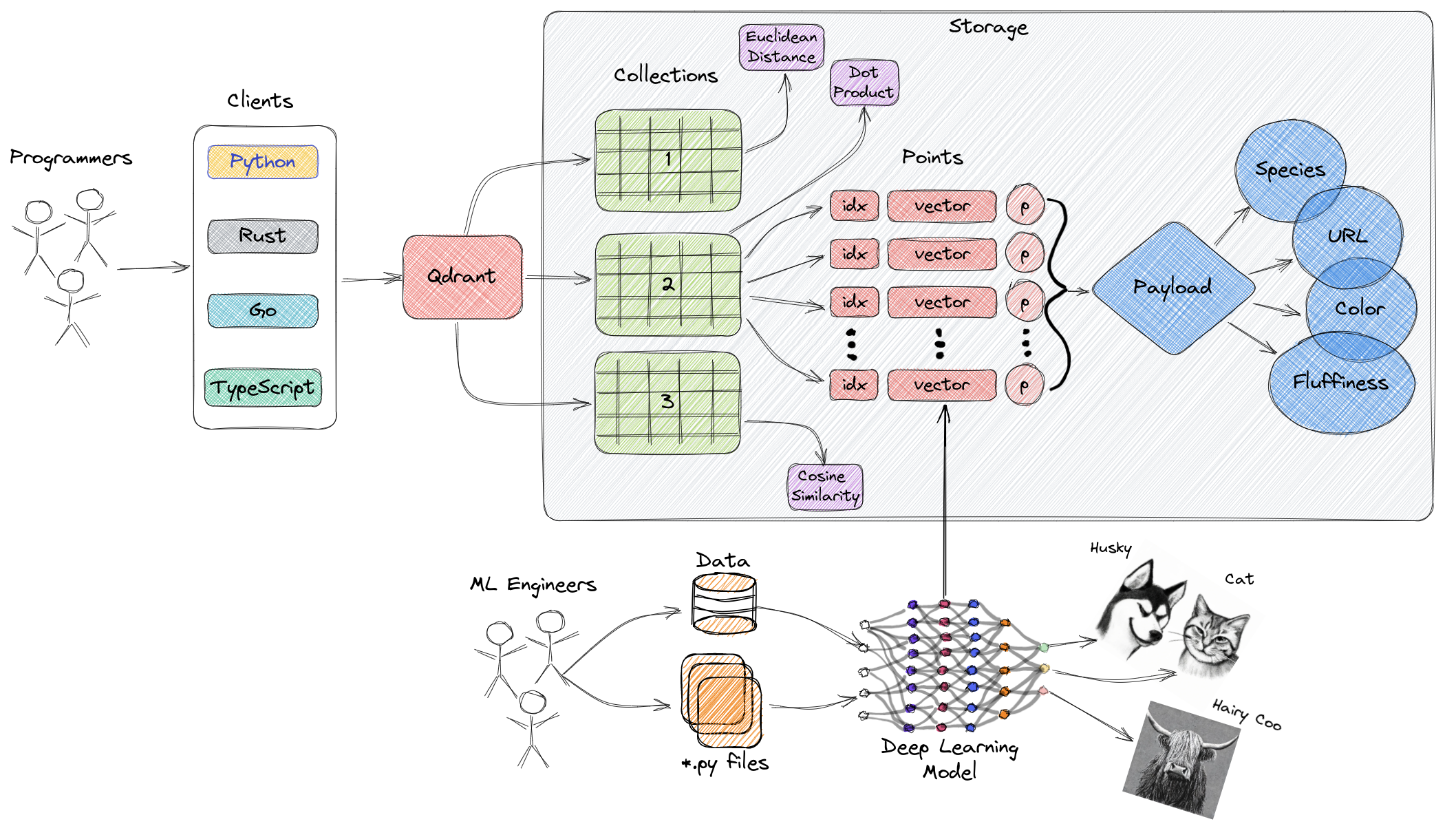
上記の図は、Qdrantの主要なコンポーネントの高レベルな概要を示しています。以下は、Qdrantに関連する主要な用語です:
- コレクション:コレクションは名前付きのポイント(ベクトルデータを含む)のグループです。単純に言えば、コレクションはMySQLのテーブルに類似し、ポイントはそれらのテーブル内のデータの行に類似します。これらのポイント間で検索が行われます。同じコレクション内の各ベクトルは同じ次元を持ち、単一のメトリックを使用して比較する必要があります。名前付きベクトルを使用すると、1つのポイント内に複数の次元とメトリック要件を持つ複数のベクトルを配置することができます。
- メトリック:ベクトル間の類似性を定量化するために使用される尺度で、コレクションを作成する際に選択する必要があります。メトリックの選択は、特に新しいクエリをエンコードするために使用されるニューラルネットワークの方法に依存します(メトリックは選択した類似性アルゴリズムです)。
- ポイント:ポイントはQdrantが操作する中核的なエンティティで、ベクトル、オプションのID、ペイロード(MySQLテーブル内のデータの行に類似)から構成されています。
- ID:ベクトルの一意の識別子。
- ベクトル:画像、音声、ドキュメント、ビデオなどのデータの高次元表現。
- ペイロード:ベクトルに追加データとして追加できるJSONオブジェクト(主にベクトルに関連するビジネスプロパティを格納するために使用)。
- ストレージ:Qdrantは2つのストレージオプションを利用できます― インメモリ ストレージ(すべてのベクトルをメモリ内に保存し、永続性のためにディスクアクセスが使用されるため、最も高速)および Memmap ストレージ(ディスク上のファイルに関連付けられた仮想アドレス空間を作成)。
- クライアント:プログラミング言語のSDKを使用してQdrantに接続するか、REST APIを使って直接Qdrantとやり取りすることができます。