
Sebuah basis data vektor adalah cara yang relatif baru untuk berinteraksi dengan representasi data abstrak, yang berasal dari model pembelajaran mesin yang sangat rahasia seperti struktur pembelajaran mendalam. Representasi ini umumnya disebut sebagai vektor atau vektor penggelembungan, dan mereka adalah versi yang terkompresi dari data yang digunakan untuk melatih model pembelajaran mesin untuk melakukan tugas-tugas seperti analisis sentimen, pengenalan ucapan, dan deteksi objek.
Basis data baru ini telah menunjukkan kinerja yang luar biasa dalam banyak aplikasi, seperti pencarian semantik dan sistem rekomendasi.
Apa itu Qdrant?
Qdrant adalah basis data vektor sumber terbuka yang dirancang untuk aplikasi Kecerdasan Buatan generasi mendatang. Ini adalah berbasis awan dan menyediakan API RESTful dan gRPC untuk mengelola penanaman. Qdrant memiliki fitur yang kuat, mendukung pencarian gambar, suara, dan video, serta integrasi dengan mesin AI.
Apa itu Basis Data Vektor?
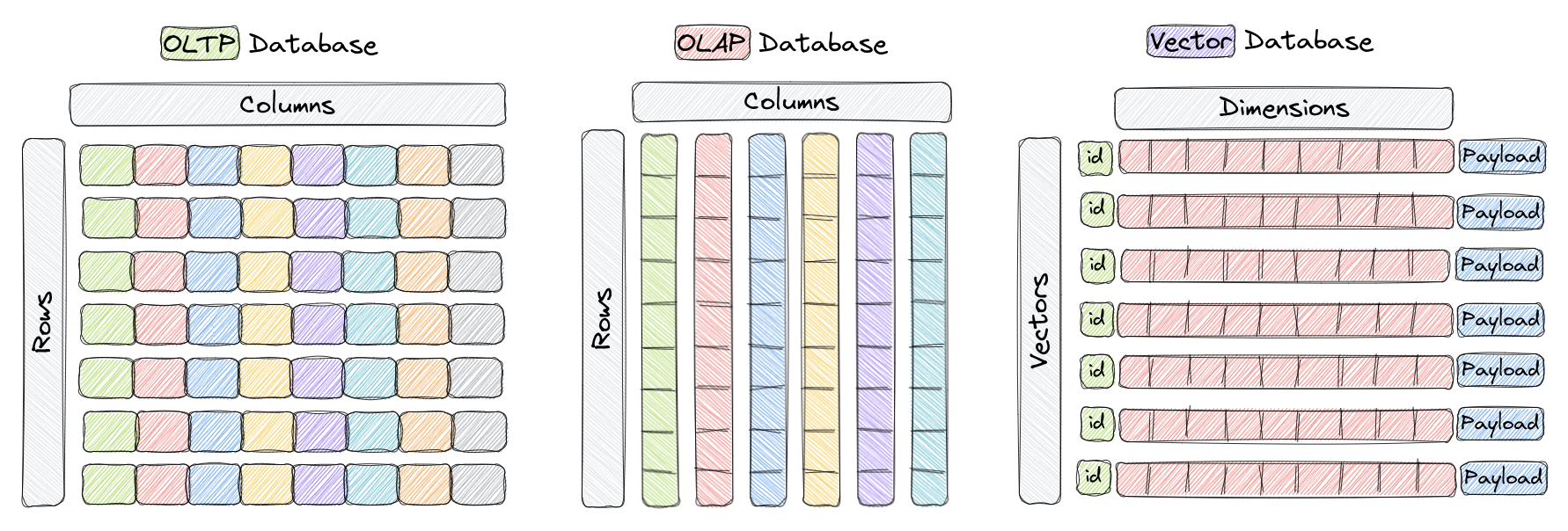
Basis data vektor adalah jenis basis data yang dirancang khusus untuk penyimpanan dan pencarian vektor berdimensi tinggi dengan efisien. Dalam basis data OLTP dan OLAP tradisional (seperti yang ditunjukkan dalam gambar di atas), data diatur dalam baris dan kolom (disebut sebagai tabel), dan kueri didasarkan pada nilai-nilai di kolom-kolom ini. Namun, dalam beberapa aplikasi seperti pengenalan gambar, pemrosesan bahasa alami, dan sistem rekomendasi, data sering kali direpresentasikan dalam bentuk vektor di ruang berdimensi tinggi. Vektor-vektor ini, bersama dengan ID dan muatannya, merupakan elemen yang disimpan dalam basis data vektor seperti Qdrant.
Dalam konteks ini, vektor adalah representasi matematika dari objek atau titik data, di mana setiap elemen vektor sesuai dengan fitur atau atribut dari objek tersebut. Sebagai contoh, dalam sistem pengenalan gambar, vektor dapat merepresentasikan gambar, dengan setiap elemen vektor mewakili nilai piksel atau fitur/deskriptor piksel. Dalam sistem rekomendasi musik, setiap vektor merepresentasikan sebuah lagu, dengan setiap elemen vektor mewakili sebuah fitur dari lagu, seperti irama, genre, lirik, dll.
Basis data vektor dioptimalkan untuk penyimpanan dan pencarian efisien vektor-vektor berdimensi tinggi, seringkali memanfaatkan struktur data khusus dan teknik-indeks seperti Hierarchical Navigable Small World (HNSW) untuk pencarian tetangga terdekat perkiraan dan Product Quantization. Basis data ini dapat memungkinkan pengguna untuk menemukan vektor-vektor terdekat dengan sebuah vektor kueri tertentu sesuai dengan suatu metrik jarak tertentu, memungkinkan pencarian kesamaan dan semantik yang cepat. Metrik jarak yang paling umum digunakan meliputi jarak Euclidean, kesamaan kosinus, dan produk dot, semuanya didukung sepenuhnya di Qdrant.
Berikut adalah pengantar singkat tentang tiga algoritma kesamaan vektor ini:
- Kesamaan Kosinus - Kesamaan kosinus adalah ukuran kesamaan antara dua item. Ini dapat dilihat sebagai penggaris yang digunakan untuk mengukur jarak antara dua titik; namun, daripada mengukur jarak, ia mengukur kesamaan antara dua item. Ini umum digunakan dalam membandingkan kesamaan antara dua dokumen atau kalimat dalam teks. Rentang output kesamaan kosinus adalah dari 0 hingga 1, di mana 0 menunjukkan ketidakkesamaan lengkap dan 1 menunjukkan kesamaan lengkap. Itu adalah cara yang sederhana dan efektif untuk membandingkan dua item!
- Produk Dot - Kesamaan produk dot adalah ukuran kesamaan lain antara dua item, serupa dengan kesamaan kosinus. Dalam penanganan angka, ini sering digunakan dalam pembelajaran mesin dan sains data. Kesamaan produk dot dihitung dengan mengalikan nilai-nilai dalam dua set angka lalu menambahkan produk-produk ini. Jumlah yang lebih tinggi menunjukkan kesamaan yang lebih tinggi antara kedua set angka. Ia seperti sebuah skala yang mengukur derajat kecocokan antara dua set angka.
- Jarak Euclidean - Jarak Euclidean adalah cara mengukur jarak antara dua titik dalam ruang, mirip dengan cara kita mengukur jarak antara dua tempat di peta. Ini dihitung dengan menemukan akar kuadrat dari jumlah kuadrat dari perbedaan koordinat dari dua titik. Metode pengukuran jarak ini umum digunakan dalam pembelajaran mesin untuk menilai kesamaan atau ketidaksesuaian dua titik data, dengan kata lain, untuk memahami seberapa jauh mereka terpisah.
Sekarang, setelah kita tahu apa itu basis data vektor dan bagaimana perbedaannya secara struktural dari basis data lain, mari kita pahami mengapa mereka penting.
Mengapa kita memerlukan basis data vektor?
Basis data vektor memainkan peran penting dalam berbagai aplikasi yang memerlukan pencarian kesamaan, seperti sistem rekomendasi, pengambilan gambar berbasis konten, dan pencarian personal. Dengan memanfaatkan teknik pengindeksan dan pencarian yang efisien, basis data vektor dapat mengambil data tak terstruktur yang diwakili sebagai vektor dengan lebih cepat dan akurat, menyajikan hasil yang paling relevan untuk kueri pengguna.
Selain itu, manfaat lain dari menggunakan basis data vektor termasuk:
- Penyimpanan dan pengindeksan data berdimensi tinggi yang efisien.
- Kemampuan untuk menangani kumpulan data skala besar dengan miliaran titik data.
- Mendukung analisis dan kueri real-time.
- Kemampuan untuk menangani vektor yang berasal dari tipe data kompleks seperti gambar, video, dan teks berbahasa alami.
- Peningkatan kinerja aplikasi pembelajaran mesin dan kecerdasan buatan sambil mengurangi latensi.
- Pengurangan waktu dan biaya pengembangan dan implementasi dibandingkan dengan membangun solusi kustom.
Harap dicatat bahwa manfaat khusus penggunaan basis data vektor dapat bervariasi tergantung pada kasus penggunaan organisasi Anda dan fungsionalitas basis data yang dipilih.
Sekarang, mari kita lakukan penilaian tingkat tinggi terhadap arsitektur Qdrant.
Gambaran Tingkat Tinggi Arsitektur Qdrant
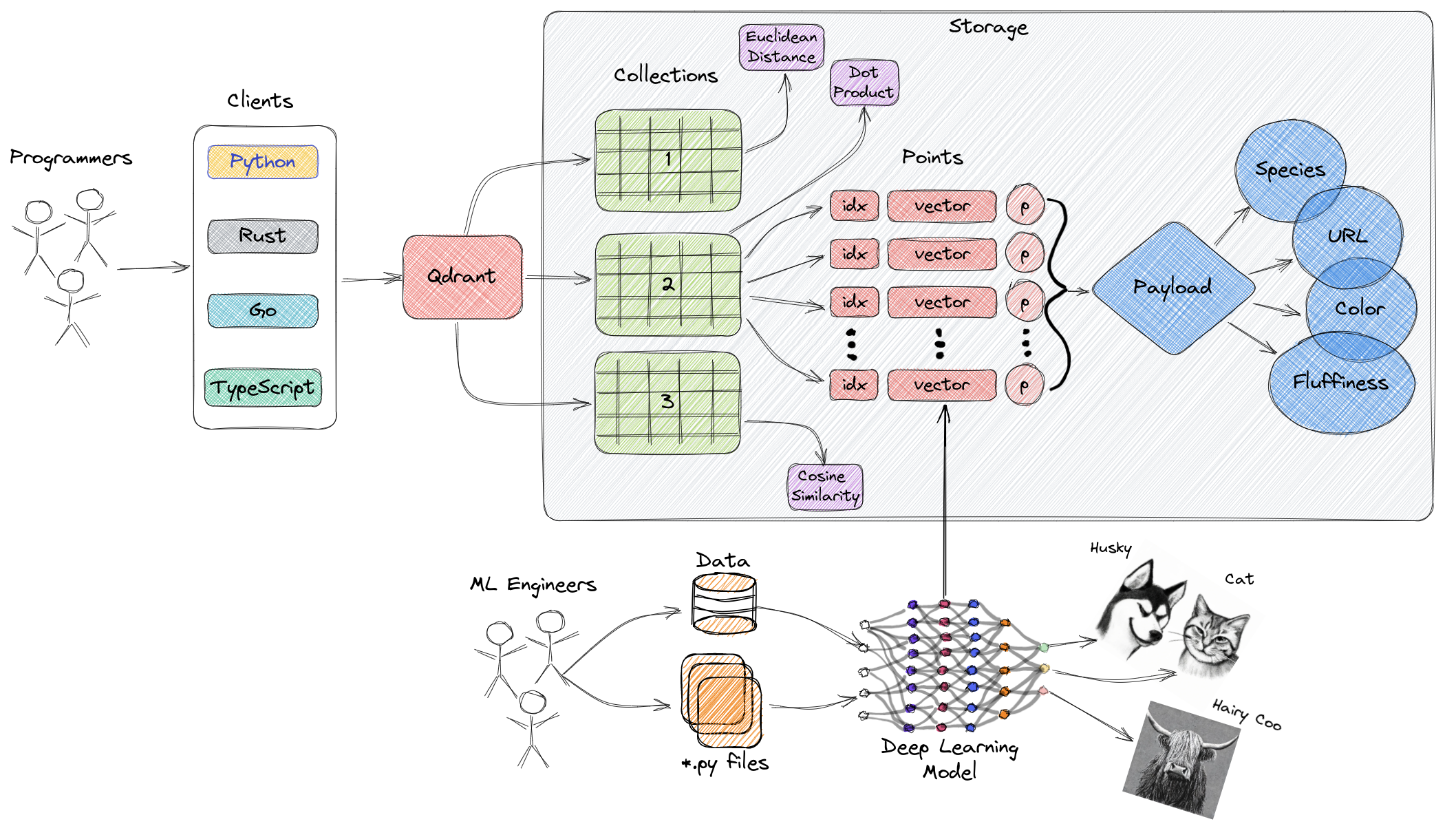
Diagram di atas memberikan gambaran tingkat tinggi mengenai komponen utama Qdrant. Berikut adalah istilah kunci terkait Qdrant:
- Koleksi: Koleksi adalah kelompok titik yang bernama (vektor dengan muatan—pada dasarnya data vektor). Dalam istilah yang lebih sederhana, koleksi serupa dengan tabel di MySQL, dan titik serupa dengan baris data dalam tabel tersebut. Pencarian dapat dilakukan di antara titik-titik ini. Setiap vektor dalam koleksi yang sama harus memiliki dimensi yang sama dan dibandingkan menggunakan metrik tunggal. Vektor bernama dapat digunakan untuk memiliki beberapa vektor dalam satu titik, masing-masing dengan dimensi dan persyaratan metriknya sendiri.
- Metrik: Ukuran yang digunakan untuk mengkuantifikasi kesamaan antara vektor, yang harus dipilih saat membuat koleksi. Pemilihan metrik bergantung pada metode akuisisi vektor, terutama untuk jaringan saraf yang digunakan untuk mengkodekan kueri baru (metrik adalah algoritma kesamaan yang kita pilih).
- Titik: Titik-titik adalah entitas inti yang dioperasikan oleh Qdrant, terdiri dari vektor, ID opsional, dan muatan (mirip dengan baris data dalam tabel MySQL).
- ID: Pengidentifikasi unik dari vektor.
- Vektor: Representasi berdimensi tinggi dari data, seperti gambar, audio, dokumen, video, dll.
- Muatan: Objek JSON yang dapat ditambahkan ke vektor sebagai data tambahan (utamanya digunakan untuk menyimpan properti bisnis yang terkait dengan vektor).
- Penyimpanan: Qdrant dapat memanfaatkan dua opsi penyimpanan—penyimpanan di memori (semua vektor disimpan di memori, menyediakan kecepatan tertinggi, karena akses ke disk hanya digunakan untuk ketekunan) dan penyimpanan Memmap (menciptakan ruang alamat virtual yang terkait dengan file di disk).
- Klien: Anda dapat terhubung ke Qdrant menggunakan SDK bahasa pemrograman atau berinteraksi langsung dengan Qdrant menggunakan API REST-nya.