
Una base de datos de vectores es una forma relativamente nueva de interactuar con representaciones de datos abstractos, que provienen de modelos de aprendizaje automático opacos, como estructuras de aprendizaje profundo. Estas representaciones comúnmente se denominan vectores o vectores de incrustación, y son versiones comprimidas de los datos utilizados para entrenar modelos de aprendizaje automático para realizar tareas como análisis de sentimientos, reconocimiento de voz y detección de objetos.
Estas nuevas bases de datos han demostrado un rendimiento sobresaliente en muchas aplicaciones, como la búsqueda semántica y los sistemas de recomendación.
¿Qué es Qdrant?
Qdrant es una base de datos de vectores de código abierto diseñada para aplicaciones de inteligencia artificial de próxima generación. Es nativa de la nube y proporciona API RESTful y gRPC para gestionar incrustaciones. Qdrant cuenta con potentes características, con soporte para búsqueda de imágenes, voz y videos, así como integración con motores de inteligencia artificial.
¿Qué es una base de datos de vectores?
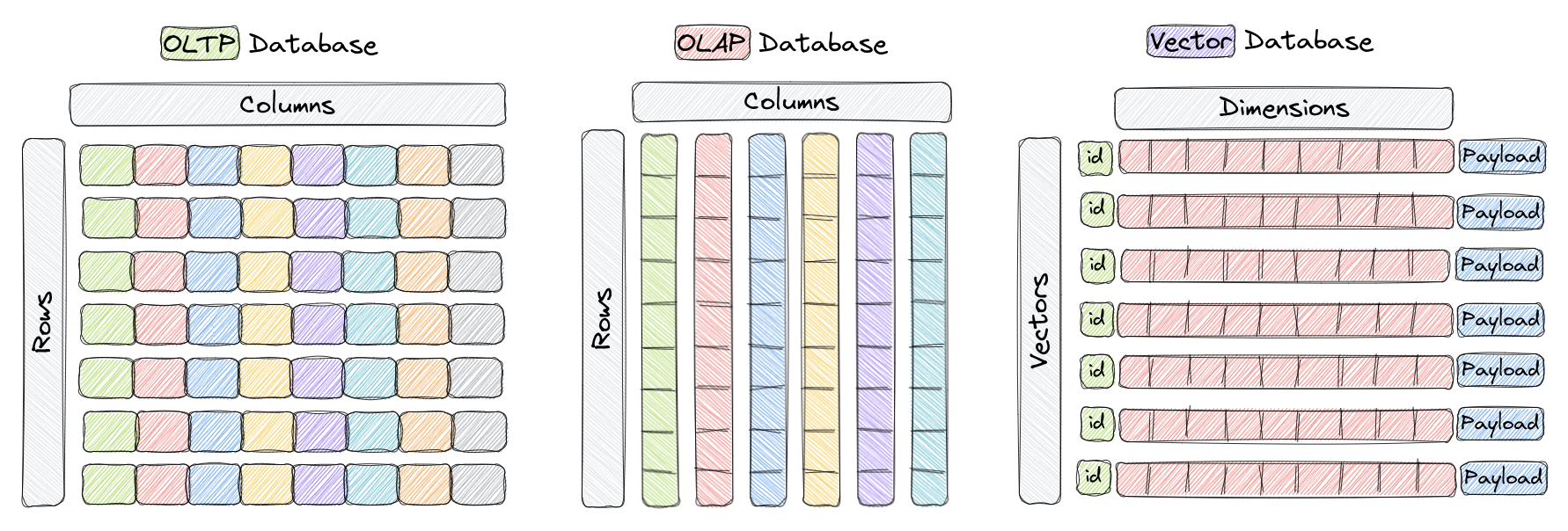
Una base de datos de vectores es un tipo de base de datos diseñada específicamente para el almacenamiento y la consulta eficientes de vectores de alta dimensionalidad. En las bases de datos tradicionales OLTP y OLAP (como se muestra en la figura anterior), los datos se organizan en filas y columnas (llamadas tablas), y las consultas se basan en los valores de estas columnas. Sin embargo, en ciertas aplicaciones como el reconocimiento de imágenes, el procesamiento del lenguaje natural y los sistemas de recomendación, los datos a menudo se representan en forma de vectores en un espacio de alta dimensionalidad. Estos vectores, junto con un ID y una carga útil, constituyen los elementos almacenados en bases de datos de vectores como Qdrant.
En este contexto, un vector es la representación matemática de un objeto o punto de datos, donde cada elemento del vector corresponde a una característica o atributo del objeto. Por ejemplo, en un sistema de reconocimiento de imágenes, un vector puede representar una imagen, donde cada elemento del vector representa los valores de los píxeles o el atributo/descriptor del píxel. En un sistema de recomendación de música, cada vector representa una canción, donde cada elemento del vector representa una característica de la canción, como el ritmo, el género, la letra, etc.
Las bases de datos de vectores están optimizadas para el almacenamiento y la consulta eficientes de vectores de alta dimensionalidad, utilizando frecuentemente estructuras de datos especializadas y técnicas de indexación como el Navegable Pequeño Mundo Jerárquico (HNSW) para la búsqueda aproximada de vecinos más cercanos y la Cuantificación de Productos. Estas bases de datos permiten a los usuarios encontrar los vectores más cercanos a un vector de consulta dado según una determinada métrica de distancia, lo que permite una búsqueda rápida de similitud y semántica. Las métricas de distancia más comúnmente utilizadas incluyen la distancia euclidiana, la similitud del coseno y el producto escalar, todas plenamente compatibles con Qdrant.
Aquí tienes una breve introducción a estos tres algoritmos de similitud de vectores:
- Similitud del coseno - La similitud del coseno es una medida de similitud entre dos elementos. Puede verse como una regla utilizada para medir la distancia entre dos puntos; sin embargo, en lugar de medir la distancia, mide la similitud entre dos elementos. Se utiliza comúnmente para comparar la similitud entre dos documentos o frases de texto. El rango de salida de la similitud del coseno va de 0 a 1, donde 0 indica completa disimilitud y 1 indica completa similitud. ¡Es una forma simple y efectiva de comparar dos elementos!
- Producto escalar - La similitud del producto escalar es otra medida de similitud entre dos elementos, similar a la similitud del coseno. En el manejo de números, se usa a menudo en aprendizaje automático y ciencia de datos. La similitud del producto escalar se calcula multiplicando los valores en dos conjuntos de números y luego sumando estos productos. Una suma más alta indica una mayor similitud entre los dos conjuntos de números. Es como una escala que mide el grado de coincidencia entre dos conjuntos de números.
- Distancia euclidiana - La distancia euclidiana es una forma de medir la distancia entre dos puntos en el espacio, similar a cómo medimos la distancia entre dos lugares en un mapa. Se calcula encontrando la raíz cuadrada de la suma de los cuadrados de las diferencias entre las coordenadas de los dos puntos. Este método de medición de distancia se utiliza comúnmente en aprendizaje automático para evaluar la similitud o disimilitud de dos puntos de datos, es decir, para entender qué tan lejos están.
Ahora que sabemos qué son las bases de datos de vectores y cómo difieren estructuralmente de otras bases de datos, vamos a entender por qué son importantes.
¿Por qué necesitamos una base de datos de vectores?
Las bases de datos de vectores desempeñan un papel crucial en varias aplicaciones que requieren búsqueda de similitud, como sistemas de recomendación, recuperación de imágenes basada en contenido y búsqueda personalizada. Al aprovechar técnicas eficientes de indexación y búsqueda, las bases de datos de vectores pueden recuperar datos no estructurados representados como vectores de manera más rápida y precisa, presentando los resultados más relevantes para la consulta del usuario.
Además, otros beneficios de utilizar una base de datos de vectores incluyen:
- Almacenamiento eficiente e indexación de datos de alta dimensión.
- Capacidad para manejar conjuntos de datos a gran escala con miles de millones de puntos de datos.
- Soporte para análisis y consultas en tiempo real.
- Capacidad para manejar vectores derivados de tipos de datos complejos como imágenes, videos y textos en lenguaje natural.
- Mejora en el rendimiento de aplicaciones de aprendizaje automático e inteligencia artificial, al tiempo que reduce la latencia.
- Reducción en el tiempo y los costos de desarrollo e implementación en comparación con la construcción de soluciones personalizadas.
Por favor, tenga en cuenta que los beneficios específicos de usar una base de datos de vectores pueden variar dependiendo de los casos de uso de su organización y las funcionalidades de la base de datos elegida.
Ahora, hagamos una evaluación de alto nivel de la arquitectura de Qdrant.
Descripción general de alto nivel de la arquitectura de Qdrant
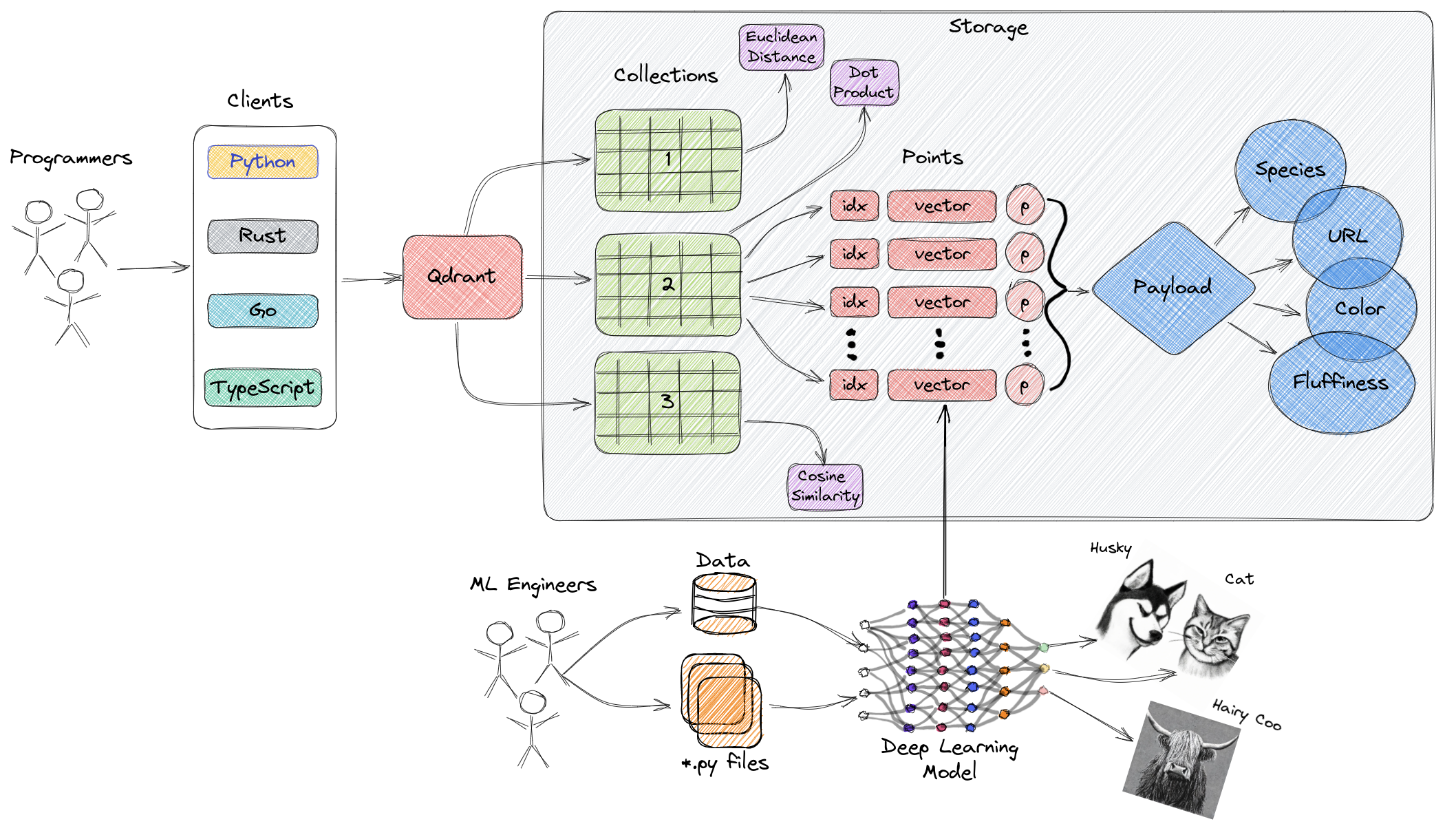
El diagrama anterior proporciona una descripción general de los componentes principales de Qdrant. A continuación se presentan los términos clave relacionados con Qdrant:
- Colecciones: Las colecciones son un grupo de puntos con nombre (vectores con cargas, esencialmente datos vectoriales). En términos más simples, las colecciones son similares a las tablas en MySQL, y los puntos son similares a las filas de datos dentro de esas tablas. La búsqueda se puede realizar entre estos puntos. Cada vector dentro de la misma colección debe tener la misma dimensión y compararse utilizando una única métrica. Los vectores con nombre se pueden usar para tener múltiples vectores en un solo punto, cada uno con sus propias dimensiones y requisitos métricos.
- Métrica: Una medida utilizada para cuantificar la similitud entre vectores, que debe ser seleccionada al crear una colección. La elección de la métrica depende del método de adquisición de vectores, especialmente para las redes neuronales utilizadas para codificar nuevas consultas (la métrica es el algoritmo de similitud que elegimos).
- Puntos: Los puntos son las entidades centrales operadas por Qdrant, compuestos por vectores, identificadores opcionales y cargas (similares a filas de datos en una tabla MySQL).
- ID: Identificador único del vector.
- Vector: Representación de alta dimensionalidad de datos, como imágenes, audio, documentos, videos, etc.
- Carga: Un objeto JSON que se puede agregar al vector como datos adicionales (principalmente utilizado para almacenar propiedades comerciales asociadas con el vector).
- Almacenamiento: Qdrant puede utilizar dos opciones de almacenamiento: almacenamiento en memoria (todos los vectores se almacenan en la memoria, lo que proporciona la mayor velocidad, ya que el acceso al disco solo se utiliza para la persistencia) y almacenamiento Memmap (creando un espacio de direcciones virtuales asociado con archivos en el disco).
- Clientes: Puede conectarse a Qdrant utilizando SDK de lenguaje de programación o interactuar directamente con Qdrant utilizando su API REST.