Tryb pracy w RabbitMQ
Tryb pracy w RabbitMQ polega na konfigurowaniu wielu konsumentów do przetwarzania wiadomości z tego samego kolejki, co może zwiększyć współbieżną prędkość przetwarzania wiadomości. Architektura jest przedstawiona na poniższym diagramie:
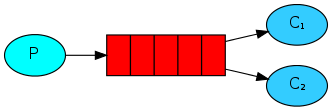
Uwaga: Niezależnie od używanego trybu pracy w RabbitMQ, każda kolejka obsługuje wielu konsumentów, a wiadomość w tej samej kolejce będzie przetwarzana tylko przez jednego z konsumentów.
1. Podręcznik wstępny
Przeczytaj poniższe sekcje, aby zrozumieć odpowiednią wiedzę:
- Podstawowe pojęcia w RabbitMQ
- Tryb pracy w RabbitMQ
- Szybki start dla PHP w RabbitMQ (konieczne do przeczytania, ponieważ kolejne sekcje nie będą powielać kodu, a jedynie pokażą kluczowy kod)
2. Implementacja wielu konsumentów w PHP
PHP sam w sobie nie obsługuje technologii współbieżnych, takich jak wielowątkowość i koorutyny, dlatego zazwyczaj wykorzystuje wieloprocesowość do osiągania przetwarzania współbieżnego. Tutaj używamy trybu wieloprocesowego do implementacji równoczesnego przetwarzania konsumentów wiadomości w kolejce.
2.1. Ręczne uruchamianie wielu procesów
Aby zaimplementować wiele procesów, najprostszym sposobem jest ręczne uruchamianie polecenia PHP wielokrotnie.
Na przykład:
Zakładając, że skrypt konsumenta z poprzedniej sekcji to recv.php, możemy otworzyć wiele okien terminala i wielokrotnie wykonywać skrypt konsumenta w ten sposób:
php recv.php
php recv.php
Lub w tym samym oknie terminala, umieścić skrypt w tle do działania w ten sposób:
php recv.php &
php recv.php &
Wyjaśnienie: Wadą implementacji wielu konsumentów w ten ręczny sposób jest to, że procesy nie są odpowiednio nadzorowane, nie ma monitorowania procesów. Jeśli proces ulegnie awarii, nie zostanie automatycznie ponownie uruchomiony.
2.2. Użycie narzędzia Supervisor do implementacji wielu procesów
Supervisor to monitor procesów w systemie operacyjnym Linux, który może monitorować procesy PHP. Jeśli proces PHP ulegnie awarii, zostanie automatycznie ponownie uruchomiony. Może także skonfigurować współbieżność procesów, ułatwiając osiągnięcie współbieżnego przetwarzania wielu konsumentów.
Oto przykład użycia w systemie Ubuntu, podobnie dla innych dystrybucji Linuxa.
Instalacja Supervisor
sudo apt-get install supervisor
Konfigurowanie Supervisor
Plik konfiguracyjny dla Supervisor zazwyczaj znajduje się w katalogu /etc/supervisor/conf.d. W tym katalogu można utworzyć dowolną liczbę plików konfiguracyjnych, aby powiedzieć Supervisorowi, jak monitorować nasze procesy. Na przykład, utwórz plik rabbitmq-worker.conf, aby monitorować nasze procesy konsumentów.
Przykład: Plik: rabbitmq-worker.conf
[program:rabbitmq-worker]
process_name=%(program_name)s_%(process_num)02d
command=php recv.php
autostart=true
autorestart=true
user=root
numprocs=10
redirect_stderr=true
stdout_logfile=/var/log/worker.log
Objaśnienie parametrów:
- process_name: Definicja nazwy procesu, może być dowolnie nazwana. Tutaj używane są dwie zmienne:
program_name(nazwa procesu) iprocess_num(numer procesu). - command: Polecenie, które musimy uruchomić.
- autostart: Czy uruchamiać automatycznie po uruchomieniu systemu.
- autorestart: Czy uruchomić ponownie automatycznie.
- user: Konto systemowe, które ma uruchomić polecenie.
- numprocs: Liczba procesów równoczesnych, określająca, ile procesów ma zostać uruchomionych.
- stdout_logfile: Lokalizacja zapisanego pliku dziennika pracy.